The grid-based technique is used for a multi-dimensional dataset. In this technique, we create a grid structure, and the comparison is performed on grids(also know as cells). The grid-based technique is fast and has low computational complexity.�Cwiki
��������ļ������ڶ�ά���ݼ��������ּ�����,���Ǵ�����һ������ṹ,��������grids(Ҳ��Ϊ��Ԫ��cells)�Ͼ����˱Ƚϡ���������ļ����ٶȿ��Ҽ��㸴�Ӷȵ͡���������ľ����㷨�漰����Ϊ:
-
�����ݿռ仮��Ϊ���������ĵ�Ԫ��
-
���ѡ��һ����Ԫ��c��,c��Ӧ�����ȱ�����
-
���㡰c�����ܶ�
-
�����c�����ܶȴ�����ֵ���ܶ�
(1)����Ԫ��c�����Ϊ�µľ���(cluster)
(2)���㡰c�������ھӵ��ܶ�
(3)������ڵ�Ԫ���ܶȴ�����ֵ�ܶ�,�������ӵ���Ⱥ��,�����ظ�����4.2��4.3ֱ��û�����ڵ�Ԫ���ܶȴ�����ֵ�ܶ�
-
�ظ�����2,3,4,ֱ���������е�Ԫ��
-
ֹͣ
��������ķ���������ռ�������Ϊ���������ĵ�Ԫ��(������),Ȼ���������ռ���ִ������IJ�������������ķ�����Ҫ�ŵ������Ŀ��ٴ���ʱ��,��ȡ���������ռ���ÿ��ά���еĵ�Ԫ��������
���������һЩ��������ķ���:
CLIQUE (Clustering in QUEst)
STING (Statistical Information Grid ͳ����Ϣ����)
MAFIA (Merging of adaptive interval approach to spatial datamining �ռ������ھ������Ӧ���䷽���ĺϲ�)
Wave Cluster (������)
O-CLUSTER (orthogonal partitioning CLUSTERing ������������)
Axis Shifted Grid ClusteringAlgorithm(���ƶ���������㷨)
Adaptive Mesh Refinement (����Ӧ����ϸ��)
�����ǽ����ݷ��鵽��class���cluster�Ĺ���,ʹ���ڵĶ�����кܸߵ�������,�����������еĶ���dz���ͬ��һ���õľ����㷨Ӧ���ܹ�ʶ�����,���������ǵ���״�������㷨������Ҫ���ǿ���չ�ԡ������������ݵ��������������¼˳�����еȡ�
CLIQUE (Clustering in QUEst)
���������ܶȺͻ�������ķ������ڵ�һ����,CLIQUE ��nά���ݿռ�S����Ϊ���ص��ľ��ε�Ԫ(����)����λ��ͨ����ÿ��ά�ȷֳɵȳ��Ħ���������á��� ��һ���������,һ����Ԫ��ѡ���Զ���Ϊ���а����������ݵ㡣��ѡ����(u)���ڦ�,��λ u�dz��ܵ�,��������һ����Ҫ����IJ���,��Ϊ�ܶ���ֵ���ӿռ��е�һ����Ԫ������K�������е�ÿһ������Ľ�������Ⱥ�����ӵ��ܼ���Ԫ����ϡ��������Kά��Ԫu1, u2����ͬ������(commonface)����ô����������Ԫ���ӡ�Ȼ���ܼ���Ԫ���������γɼ�Ⱥ����ʹ��apriori �㷨(�Ե������㷨)���ҵ��ܼ���Ԫ���ܼ���Ԫ��ͨ��ʹ��������ʵ��ʶ���:���Kά��Ԫ(a1,b1)(a2,b2)��(ak,bk)���ܼ���, Ȼ���κ�k-1ά�ȵĵ�Ԫ(a1,b1)(a2,b2)��(aik-1,bik-1)Ҳ���ܼ���,����(ai,bi)�ǵ�i��ά�ȵĵ�λ��
����һ�����ݵ����������μ���,CLIQUE�ܹ�������ԭʼ�ռ�������ӿռ����ҵ�����,����DNF����ʽ����ʽ����ÿ����Ⱥ����С������CLIQUE���漰�IJ���Ϊ:
1)ʶ������ص��ӿռ�(�ܼ���Ԫ);
2)���ܼ���Ԫ�ϲ��γɾ���;
3)���ɼ�Ⱥ����С������
STING:( A Statistical Information grid approachto spatial data mining)
�ռ������ھ�����ȡ����֪ʶ���ռ��ϵ�ͷ������ݿ���δ��ȷ��ʾ����Ȥ������ģʽ��(�ռ������ھ��ںܶ������й㷺��Ӧ��,����GISϵͳ��ͼ�����ݿ�̽��,ҽѧ����ȵ�)��
STING ��һ����������Ķ�ֱ���༼��,���пռ�������Ϊ���ε�Ԫ(ʹ��ά�Ⱥ;���),�����÷ֲ�ṹ��(��ֱ漼��:����ʹ��һ�ֲִڵij߶ȶ�������ͼ�����ؽ��д���,Ȼ������һ��ʹ��һ�־�ȷ�ij߶�, ������һ��Ľ������������г�ʼ��. �����ù���, ֱ���ﵽ�ȷ�ij߶�.�����ɴֵ�ϸ, �ڴ�߶��Ͽ�����,��С�߶��Ͽ�ϸ�ڵķ����ܹ�����̶ȵ�������ɹ���)��
ͨ���м�����������־��ε�Ԫ��Ӧ�ڲ�ͬ�ķֱ��ʼ��𡣸����ÿ����Ԫ����Ϊ�ϵͼ�����ӵ�Ԫ��i��ĵ�Ԫ���Ӧ�ڵ�i+1����ӵ�Ԫ�IJ�����ÿ����Ԫ��(Ҷ�ӳ���)���ĸ��ӵ�Ԫ,ÿ���ӵ�Ԫ��Ӧ�ڸ���Ԫ��һ�����ޡ�
����ÿ������Ԫ�е����Ե�ͳ����Ϣ(����,��ֵ��������ֵ����Сֵ)��Ԥ�ȼ��㲢�洢�õġ�
��һ�㵥Ԫ��ͳ�Ʋ������Ժ����شӵͲ㵥Ԫ�IJ����������������ÿ����Ԫ��,�������Զ���������������ز���:
i)���Զ�������:
count ����;
ii)���Թ�������;
M-�˵�Ԫ��������ֵ��ƽ��ֵ;S-�˵�Ԫ���е�����ֵ�ı���;Min-�˵�Ԫ�������Ե���Сֵ;Max-�õ�Ԫ�������Ե����ֵ,Distribution-����ֵ��ѭ�ķֲ����͡��ֲ�����Ϊ��̬����ֵָ�����ޡ�
�����ݱ����ص����ݿ���,�ײ㵥Ԫ�IJ���count, m, s, min, max ֱ�Ӵ������м���õ���
����,ȷ����ѯ�������̴��ĸ��㿪ʼ������������������Ԫ��ɡ����ڸò��е�ÿ����Ԫ,����ͨ�������ڲ����Ŷ�����鵥Ԫ��֮�������ԡ�ȥ������صĵ�Ԫ��,���ظ��˹���,ֱ���ﵽ�ײ㡣
MAFIA (merging of adaptive intervals approachto spatial data mining)
MAFIA��������ڿ����ӿռ���������Ӧ����,���������ܹ���������һ������չ�IJ��мܹ��������������ݼ������������������㷨ʹ�þ��ȵ�����,��MAFIAʹ������Ӧ����MAFIA�����һ������Ӧ����ÿ��ά������������(binsͰ)�ļ���,��Щ���䱻�ϲ���̽������ά�ȵļ�Ⱥ��
����Ӧ����ߴ���ټ��㲢����߾������� �� ͨ���������ݿռ��о��и���㲢��˾��о���Ŀ����ԵIJ��֡����ֽ����ʾ,����ʹ��������Ӧ����,MAFIA��CLIQUE��40��50����MAFIA�����˲�����,�Ի�����ڴ����ݼ��ĸ߶ȿ���չ�ľ����㷨��
MAFIA�����һ������Ӧ�����С,����ά���е����ݷֲ�������ά�ȡ�ʹ�����ͨ��һ�����ݹ�����ֱ��ͼ,MAFIAȷ��һ��ά�ȵ�bin����С���������������Ƶ�ֱ��ͼֵ��Bin��������γɸ����Bin,���е������ܶȵ�Bin��cell���ᱻ�������ƺϸ���ܼ���Ԫ(Dense units),�Ӷ����ټ��㡣һ��bins�ı߽�Ҳ�����Ǹ��Ե�,�������ÿ��ά���ϸ�ȷ������˼�Ⱥ�߽硣������˾�������������
Wave Cluster(������)
Wave cluster��һ�ֶ�ֱ�����㷨���������ڷdz���Ŀռ��������ҵ����ࡣ
����һϵ�еĿռ����Oi, 1�� i �� N,����㷨��Ŀ���Ǽ����ࡣ������ͨ������ά����ṹ�ӵ����ݿռ����������ݡ���Ҫ˼����ͨ��Ӧ��С���任(wavelet transform)��ԭʼ�������б任Ȼ�����µĿռ����ҵ��ܼ�����С���任��һ�ֽ��źŷֽ�Ϊ��ͬƵ���Ӵ����źŴ���������
С�������㷨�ĵ�һ���Ƕ������ռ�����������ڶ���,�������������ռ�Ӧ����ɢС���任,�Ӷ������µĵ�Ԫ��Wavecluster(����) ��2�鵥Ԫ�������,���DZ���Ϊcluster�ء���Ӧ��С���任��ÿ���ֱ��ʦ�,����һ�����Cr, ͨ���ڽϴֵķֱ�����,�ص��������١�����һ����,wave cluster��ǰ����ڼ�Ⱥ�е������ռ��еĵ�Ԫ��
С���任������:1)С���任�����Զ�ȥ���쳣ֵ;2)С���任�Ķ�ֱ������ʿ����������ڲ�ͬ����ˮƽ�ľ���;3)С������ļ��㸴�Ӷ�Ϊo(n),��˼���dz���,����nΪ���ݿ��ж��������;4)���Է���������״�ľ���;5)���������˳������;6)�����Դ������20ά������;7)������Ч�ش����κδ����Ŀռ����ݿ⡣
O-Cluster(������������)
���־��������ӱ�ķ�������������������ƽ�в�������,��ʶ������ռ��е��������ܶ�����O-cluster��һ�ֽ���������ͶӰ(contracting projection)����֮�ϵķ�����
O-cluster ��������Ҫ�Ĺ���:1) ��ʹ��ͳ�Ƽ�������֤�ָ�ƽ�����������ͳ�Ƽ���ȷ��������ͶӰ�����÷ָ�㡣2) �������ڰ�������ԭʼ���ݼ����������С�����������С�û������ķ���������,�����ǹ��������ݵ�ӻ��������ɾ����
O-cluster �ݹ����С�����������������ͶӰ�Ŀ��ܲ�ֵ�,ѡ����ѡ�һ��,�������ݲ��Ϊ������
���㷨ͨ�����´����ķ������������õķָ�ƽ�������С�O-cluster����һ���ֲ����ṹ,������ռ�ת��Ϊ����������Ҫ��������Ϊ:
1)�������ݻ�����;
2)����������ֱ��ͼ;
3)�ҵ�������ġ���ѡ��ָ��;
4)��Dz���ȷ�Ͷ���ķ���;
5)��ֻ����;
6)���¼��ػ�������
O-cluster��һ�ַDz����㷨��O-cluster �������������¼��ά�ȵĴ������ݼ���
ASGC (Axis Shifted Grid Clustering Algorithm ���ƶ��������)
ASGC��һ�־��༼��,������˻����ܶȺ�����ķ���,ʹ�����ƶ��ָ����(Axis shifted partitioning strategy)�Զ�����з��顣�ֻ���������㷨�ľ���������Ԥ���趨��Ԫ��Ĵ�С�͵�Ԫ���ܶȵ�Ӱ�졣�÷���ʹ����������ṹ�����ٵ�Ԫ��߽��Ӱ�졣�ڶ�������ṹ��ͨ����ÿ��ά���Ͻ��������ƶ������Ԫ����ȶ��γɵġ�
ASGC���õķ�������6������:
1)���������ݿռ仮��Ϊ���ص��ĵ�Ԫ�Ӷ��γɵ�һ������ṹ;
2)ʶ�����Ҫ�ĵ�Ԫ��(����ø���ܶȴ����趨����ֵ);
3)�����������Ҫ��Ԫ�������һ���γɴ�(cluster);
4)��ԭʼ����ԭ�������ݿռ��ÿ��ά�����ƶ�����d�Ի���µ�����ṹ;
5)�µĴ�clusterͨ������2��3�γ�;
6)����������ṹ���ɵĴؿ��������Ĵ���������ṹ���ɵļ�Ⱥ��
ASGC�㷨����ʱ�临�Ӷȵ͵��ŵ㡣����һ�ַDz����㷨�����㷨�����ݿռ����Ԥ�������������ݿռ��ά�ȡ�
AMR (Adaptive Mesh Refinement ����Ӧ����ϸ��)
����Ӧ����ϸ����һ�ֶ�ֱ����㷨,���ھֲ�����ʵ�ָ߷ֱ��ʡ�AMR�����㷨����ʹ�õ�һ�ֱ��ʵ�����,���Ǹ��������ܶ�����Ӧ�ش�����ͬ�ֱ��ʵ��������,���㷨��ÿ��Ҷ����Ϊ����cluster������,���ݹ�ؽ�λ�ڸ��ڵ��е����ݶ�����з���,ֱ��������ڵ㡣AMR�����㷨���Լ�ⲻͬ�ֱ��ʼ����Ƕ���ࡣ

��ͼ��һ��Ƕ����ṹ�����ӡ�
AMR�Ӹ��������������Ĵֲھ�������ʼ,��ͨ���Զ����Ӹ���ϸ�����������Զ�ϸ��ijЩ�������ӵĸ�����Ԫ�����µ�������,ͨ��������(�����ܶ�)������������ֵ����ÿ�������͵ݹ�ؽ���ϸ��,ֱ�����е�����������ľ��Ȳ���

��ͼչʾ��AMR��������,����ÿ�����ڵ�ʹ���˲�ͬ�ķֱ���������������ȵĸ�����������,�������������������,grid1��grid2��Grid1��grid2�ְ�����ϸ�����ڵ������е�λ��Խ��,ʹ�õ������Խϸ��
AMR�����㷨ͨ��AMR��������������ͻ����ܶȵķ�����������,��˱������������㷨���ŵ㡣
����������㷨�ıȽ�:

ͨ��pyclustering��ʹ��CLIQUE�㷨����
import pyclustering
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
CLIQUE �Զ��ҵ���ά�Ⱦ�����ӿռ䡣��������ļ�¼����ʾ˳�����,�����������ͬ�Ľ���������ٶ��������κι淶�ֲ���(�ܶ�ʱ�����ǻ�Ĭ�ϼٶ�����Ϊ��˹�ֲ�)��
from pyclustering.cluster.clique import clique, clique_visualizer
from pyclustering.utils import read_sample
from pyclustering.samples.definitions import FCPS_SAMPLES
# read two-dimensional input data 'Target'
data = read_sample(FCPS_SAMPLES.SAMPLE_TARGET)
# create CLIQUE algorithm for processing
intervals = 10 # defines amount of cells in grid in each dimension
threshold = 0 # lets consider each point as non-outlier �������ֵ�ܶ�?
clique_instance = clique(data, intervals, threshold)
# start clustering process and obtain results
clique_instance.process()
clusters = clique_instance.get_clusters() # allocated clusters
noise = clique_instance.get_noise() # points that are considered as outliers (in this example should be empty)
cells = clique_instance.get_cells() # CLIQUE blocks that forms grid
print("Amount of clusters:", len(clusters))
# ��Ϊÿ���㶼���ǽ�ȥ��,���������м���������Ͻ����ĸ������һ����6��������
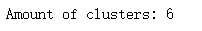
�鿴һ�·���ǰ�����ݵ�ķֲ�:
df=pd.DataFrame(data=data,columns=(['x','y'])
plt.scatter(df.x,df.y)

�������ͼ����Կ���,�м�Բ�Ŀ��Կ���һ������,Ȼ���м��Ǹ�������һ������,�ĸ����Ϸֱ��ĸ�����,��ôһ�����������ࡣ
Ȼ�����ǿ�һ��CLIQUE�㷨��thresholdΪ0������¶�data�����ά���ݵķ��������
# visualize clustering results
clique_visualizer.show_grid(cells, data)
# show grid that has been formed by the algorithm

��ͼΪ���㷨�γɵ��������,��ͼΪ���㷨�ľ�����,��������ֱ���������ɫ��ͼ�б�ʾ��
clique_visualizer.show_clusters(data, clusters, noise)
# show clustering results

���潫threshold��Ϊ3�˵�һЩoutlier(��Ⱥֵ),���鿴һ��CLIQUE�ľ�������
# read two-dimensional input data 'Target'
data = read_sample(FCPS_SAMPLES.SAMPLE_TARGET)
# create CLIQUE algorithm for processing
intervals = 10 # defines amount of cells in grid in each dimension
threshold = 3 # lets consider each point as non-outlier �������ֵ�ܶ�?
# block that contains 3 or less points is considered as a outlier as well as its points
clique_instance = clique(data, intervals, threshold)
# start clustering process and obtain results
clique_instance.process()
clusters = clique_instance.get_clusters() # allocated clusters
noise = clique_instance.get_noise() # points that are considered as outliers (in this example should be empty)
cells = clique_instance.get_cells() # CLIQUE blocks that forms grid
print("Amount of clusters:", len(clusters))
# ���ϵĵ㶼��ȥ����,�����ǿ�����outlier(��Ⱥֵ,),
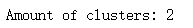
# visualize clustering results
clique_visualizer.show_grid(cells, data)
# show grid that has been formed by the algorithm չʾ�㷨�γɵ�����

clique_visualizer.show_clusters(data, clusters, noise)
# show clustering results

��Ϊ���threshold��ֵ����Ϊ3,�����ĸ����ϵ����Ǽ���ֵ,�����ܶȵ�����ֵ������������Ⱥֵ,������һ�����ࡣ
������ش���,���ںź�̨�ظ� CLIQUE
