1 前言

历史三个月,文本可读性识别大赛终于落下帷幕,我们队伍的ID为wordpeace,队员分别为:致Great,firfile,heshien,heng zheng,XiaobaiLan,私榜取得91名成绩,排名top2%,整体比赛竞争比较大,邻近手分数非常接近甚至片段并列,同时私榜出现大面积抖动。
2 比赛简介

比赛名称:CommonLit Readability Prize
比赛任务:在本次比赛中,选手构建算法来评估 3-12 年级课堂使用的阅读文本段落的复杂性,用来评估文本的可读性,是否通俗易懂。
比赛链接:https://www.kaggle.com/c/commonlitreadabilityprize/overview
评估指标:
RMSE
=
1
n
∑
i
=
1
n
(
y
i
?
y
^
i
)
2
\text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2}
RMSE=n1?i=1∑n?(yi??y^?i?)2?
比赛数据:
id:每条文本的唯一ID
url_legal:数据来源,测试集中为空
license :数据许可协议,测试集中为空
excerpt :需要预测的测试集文本
target :可读性分数,目标值
standard_error :衡量每个摘录的多个评分者之间的分数分布。不包括测试数据。
3 方案总结
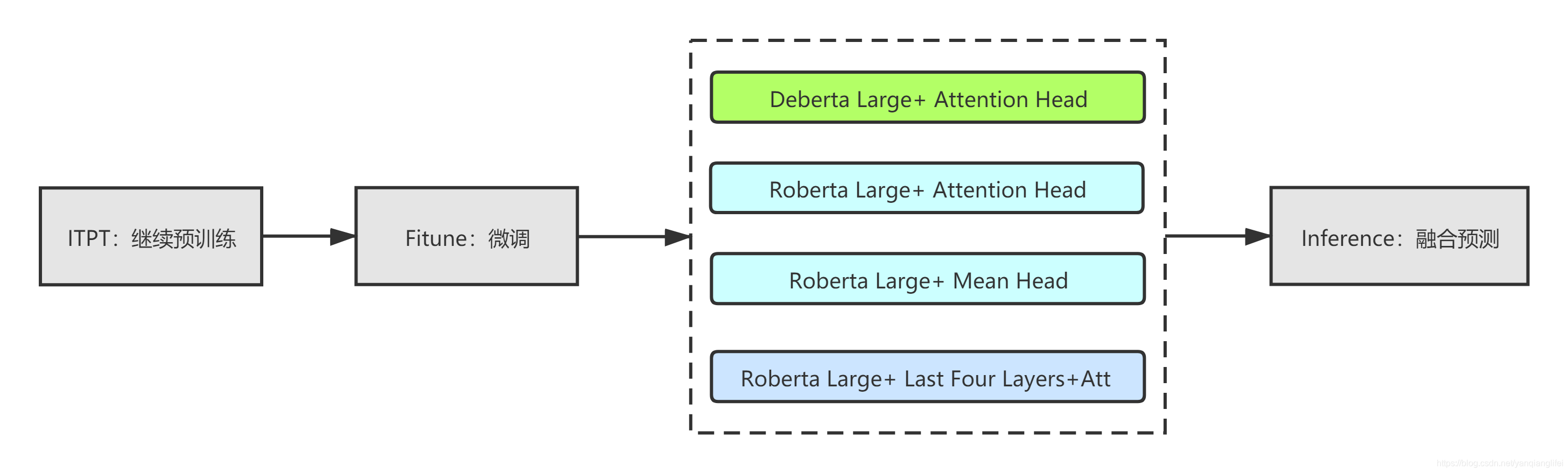
总体方案为:
- 基于比赛任务给定的训练集和测试集语料进行继续预训练:MLM任务
- 对于预训练模型输出拼接其他网络层进行微调,主要用到的池化层有AttentionHead,MeanPooling以及预训练模型最后四个隐层输出的组合。
- 融合非常简单,根据公榜分数设置权重进行加权相加
【论文解读】文本分类上分利器:Bert微调trick大全
B站回放:科大讯飞NLP文本分类赛事上分利器:Bert微调技巧大全 ChallengeHub分享
3.1 ITPT:继续预训练
Bert是在通用的语料上进行预训练的,如果要在特定领域应用文本分类,数据分布一定是有一些差距的。这时候可以考虑进行深度预训练。
Within-task pre-training:Bert在训练语料上进行预训练
import warnings
import pandas as pd
from transformers import (AutoModelForMaskedLM,
AutoTokenizer, LineByLineTextDataset,
DataCollatorForLanguageModeling,
Trainer, TrainingArguments)
warnings.filterwarnings('ignore')
train_data = pd.read_csv('data/train/train.csv', sep='\t')
test_data = pd.read_csv('data/test/test.csv', sep='\t')
train_data['text'] = train_data['title'] + '.' + train_data['abstract']
test_data['text'] = test_data['title'] + '.' + test_data['abstract']
data = pd.concat([train_data, test_data])
data['text'] = data['text'].apply(lambda x: x.replace('\n', ''))
text = '\n'.join(data.text.tolist())
with open('text.txt', 'w') as f:
f.write(text)
model_name = 'roberta-base'
model = AutoModelForMaskedLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.save_pretrained('./paper_roberta_base')
train_dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="text.txt", # mention train text file here
block_size=256)
valid_dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="text.txt", # mention valid text file here
block_size=256)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
training_args = TrainingArguments(
output_dir="./paper_roberta_base_chk", # select model path for checkpoint
overwrite_output_dir=True,
num_train_epochs=5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
gradient_accumulation_steps=2,
evaluation_strategy='steps',
save_total_limit=2,
eval_steps=200,
metric_for_best_model='eval_loss',
greater_is_better=False,
load_best_model_at_end=True,
prediction_loss_only=True,
report_to="none")
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=valid_dataset)
trainer.train()
trainer.save_model(f'./paper_roberta_base')
3.2 不同层的特征
BERT 的每一层都捕获输入文本的不同特征。 文本研究了来自不同层的特征的有效性, 然后我们微调模型并记录测试错误率的性能。
class AttentionHead(nn.Module):
def __init__(self, h_size, hidden_dim=512):
super().__init__()
self.W = nn.Linear(h_size, hidden_dim)
self.V = nn.Linear(hidden_dim, 1)
def forward(self, features):
att = torch.tanh(self.W(features))
score = self.V(att)
attention_weights = torch.softmax(score, dim=1)
context_vector = attention_weights * features
context_vector = torch.sum(context_vector, dim=1)
return context_vector
class MeanPoolingHead(nn.Module):
def __init__(self, h_size, hidden_dim=512):
super().__init__()
def forward(self, last_hidden_state,attention_mask):
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
sum_embeddings = torch.sum(last_hidden_state * input_mask_expanded, 1)
sum_mask = input_mask_expanded.sum(1)
sum_mask = torch.clamp(sum_mask, min=1e-9)
mean_embeddings = sum_embeddings / sum_mask
return mean_embeddings
class MaxPoolingHead(nn.Module):
def __init__(self, h_size, hidden_dim=512):
super().__init__()
def forward(self, last_hidden_state,attention_mask):
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
last_hidden_state[input_mask_expanded == 0] = -1e9 # large negative value
max_embeddings, _ = torch.max(last_hidden_state, 1)
return max_embeddings
3.3 模型层间差分学习率
我们发现为下层分配较低的学习率对微调Roberta-Large 是有效的,比较合适的设置是 ξ=0.95 和 lr=2.0e-5,其中24代表Large模型encoder层数,如果使用base需要改成12.
def get_parameters(model, model_init_lr, multiplier, classifier_lr):
parameters = []
lr = model_init_lr
for layer in range(24,-1,-1):
layer_params = {
'params': [p for n,p in model.named_parameters() if f'encoder.layer.{layer}.' in n],
'lr': lr
}
parameters.append(layer_params)
lr *= multiplier
classifier_params = {
'params': [p for n,p in model.named_parameters() if 'layer_norm' in n or 'linear' in n
or 'pooling' in n],
'lr': classifier_lr
}
parameters.append(classifier_params)
return parameters
parameters=get_parameters(model,2e-5,0.95, 1e-4)
optimizer=AdamW(parameters)
4 比赛总结
在阅读前排方案之后,我们比较好的地方是单模5折可以达到0.458的分数,融合一些基础微调模型就可以达到0.455-0.456的分数,不足之处是微调模型比较单一,只采用了Deberta和Roberta的Large模型,另外在其他预训练模型比如XLNET或者T5尝试比较少;另外预训练的时候使用的语料没有做数据增强等