Pre-training is a Hot Topic: Contextualized Document Embeddings
Improve Topic Coherence
������Ϣ
-
��Ŀ: Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence
-
����: Federico Bianchi Bocconi University
-
�ڿ�: ACL
-
ʱ��: 2021
ժҪ
����ģ�ʹ��ĵ�����ȡ������,�������Ϊ�����������õ��������ݡ�Ȼ��,�ɴ˲����Ĵ�������������,ʹ���Ǹ��ѽ��͡����,������ģ��������һ���Է������˸��ơ����ͬʱ,������Ƕ��Ҳ���������ƽ�����ģ�͵ķ�չ���ڱ�����,���ǽ��龳����ʾ��������ģ�����ϡ����Ƿ���,���ǵķ����ȴ�ͳ�Ĵ��ʲ����˸����������������������ǵ��о��������,δ������ģ�͵ĸĽ���ת��Ϊ���õ�����ģ�͡�
�����&���������
����ģ�������ǻ��ڴʴ�ģ�ͱ�ʾΪ���µ�����,�ʴ�ģ����������Դʾ�֮�����Լ����塣����Bowģ�ͱ��¾Ͳ���һ�����������,���������NLP�е�Ԥѵ��ģ����������ģ�Ϳ����������������������ԡ�
����
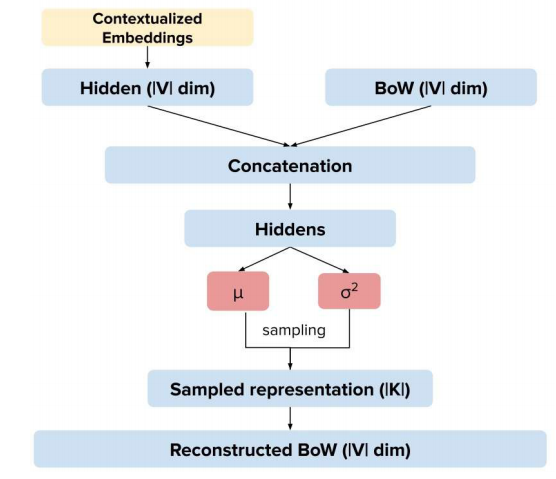
��Ҫ�����������:
-
Neural Topic Modelʹ��ProdLDA
-
ʹ��SBERT��embed��ʾ
ģ�͵ļܹ�����ͼ��ʾ,���д�Context Vector��Embeddingӳ�䵽 �O V �O |V| �OV�Oά������,����Bow��������ƴ�ӡ�
ʵ����
1�� ���ⶨ�Ժ���:
����ָ��:NMPI ( �� \tau ��)��External word embeddings topic coherence( �� \alpha ��������Word Embedding�������֮��������� ������������������ƶ�)��Inversed Rank-Biased Overlap(��ͬ�����������)

- ʹ�ò�ͬ��Ԥѵ��ģ��:Ours-R : SBERT Ours-B:Bert ��SBERT�ȽϺ�

���µ�������
��Ԥѵ��ģ�ͽ����������ģ���ĵ�ʹ�ôʴ������IJ��㡣ʵ������������Ԥѵ�����ĵ���ʾȷʵ����������ģ�͵�����̶��кܴ�İ�����
����
���½���ʲô?����Щ����?��ʲô����?��
��Ҫ������
�������õ�����Ϊ������д���ṩ�ο��ġ��м�ֵ�IJο����ס�
-
Auto encoding variational inference for topic models
-
Sentence-BERT: Sentence embeddings using Siamese BERT-networks