
Motivation
�����ε�OCR�㷨��,����ʶ���㷨��Ч��ͨ���յ����ּ���Ч�����ơ� ��������� Implicit Feature Alignment,IFAģ��,�ܹ�����ͨ�����ּ��ģ��������text detector�½��ж�������ʶ��(ʶ��ƪ��)��
ͨ����IFA���ϵ�����ʶ��������������� attention-based��CTC-based,�ֱ��Ӧattention-guided prediction(ADP)��Extended CTC(ExCTC);����Ϊ������negative prediction,�Ľ� Aggregation Cross-Entropy,���Wassetein-based Hollow Aggreation Cross-Entropy(WH-ACE )
����
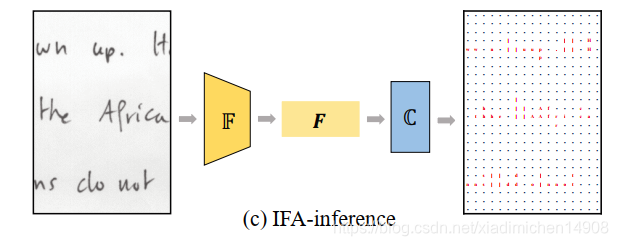
ģ��������������ͼ��ʾ,����ͼ��
x
x
x(�����ı����߶����ı�),���Ȳ���CNN��������ȡ��
F
\mathfrak{F}
F��ȡ�õ�����F
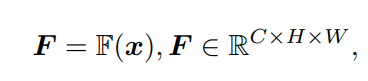
�õ�������
F
F
Fֱ�Ӿ���������
C
\mathfrak{C}
C�õ�����Ľ��ͼY,����K��ʾ�ַ������+���ַ�
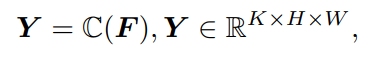
ͨ�������Ϳ��Եõ����յ�Ԥ�����С�
IFA��ʽλ�ö���,�Ӷ�����Fֱ�ӽӷ�����,�ܹ��ڶ�Ӧλ��Ԥ�����ȷ���ַ���������ϸ���ܸ������������
Attention-guided Dense Prediction(ADP)
ģ����ѵ��ʱͼƬ�õĵ����ı�����ͨ���Ĵ�ע��������Encoder decoder��, attention decoder
A
\mathfrak{A}
A����RNN,GRU,LSTM�����л�����ı�,�Ӷ���֤��������й�ϵ,��
P
(
y
�O
x
)
=
P
(
y
1
�O
x
)
P
(
y
2
�O
x
,
y
1
)
?
.
.
.
?
P
(
y
t
�O
x
,
y
1
,
.
.
.
,
y
t
?
1
)
P(y|x)=P(y1_|x)P(y_2|x,y_1)*...*P(y_t|x,y_1,...,y_{t-1})
P(y�Ox)=P(y1�O?x)P(y2?�Ox,y1?)?...?P(yt?�Ox,y1?,...,yt?1?)
��attention map��t������
��
t
\alpha_t
��t?,
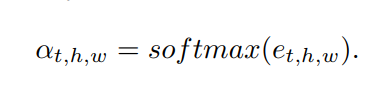
����
e
t
,
h
,
w
e_{t,h,w}
et,h,w?����������attention map��energy map����score map������������
c
t
c_t
ct?,
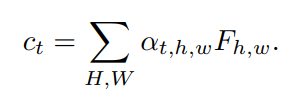
c
t
c_t
ct?��Ϊ������������,�õ�tʱ�̵�Ԥ��
y
t
y_t
yt?
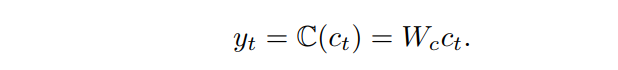
��ʧ����Ϊ��������ʧ����,
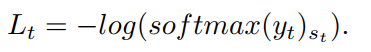
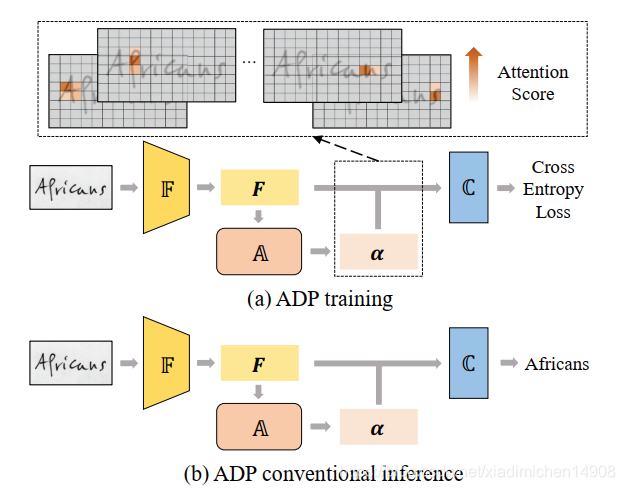
softmax�����Ԥ��ӽ�one hot�ֲ�(�о��ⲿ����,t��Ԥ��ʱattenion mapͨ��ֻ�ڶ�Ӧ���ַ���������Ӧ,�Ӷ���������Ĺ�ʽ)
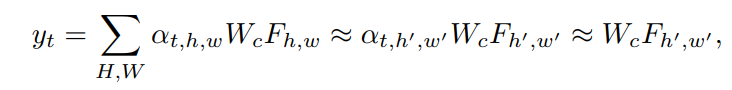
������������Ϊattention map�Ļ���ʵ���˶����,�Ӷ�����Ҳѧϰ�����ض�Ӧ��λ��������
Extended CTC(ExCTC)
�����ExCTC������squeezeNet channel-wise��attention��˼��,���õ���
N
?
C
?
H
?
W
N*C*H*W
N?C?H?W��feature map����
H
H
Hά����attention,����ͨ��softmax��ÿһ��ֻ��һ����Ӧ,������
H
H
H�������,�õ�
N
?
C
?
1
?
W
N*C*1*W
N?C?1?W,���ֱ�ӹ����������õ�Ԥ����,Ԥ������1ά��,���������Ǵ�ͳ��CTC loss��
Wassertein-based Hollow ACE(WH-ACE)
����
ͨ��������,���յõ���Ӧ�Ķ�ά���ַ�Ԥ����,����������Ҫ����������ĺ���������DFS�����ͨ��
���մ�����,���ϵ��µ�˳��,Ѱ��ÿһ����blankԤ����,��������ͨ�Ľ���ϲ�����һ��,���õ����Ľ����
�ܽ�
������ѵ���õ����ı�ѵ��,ͨ����Ƶ�attentionģ���exCTC��֤�����ڲ���Ҫ�ַ����ı�ע��,�ܹ��ڶ����ı�inference�ڲ�ͬλ��Ԥ���Ӧ�ַ������Ǹо���ԭ����attention �����ڶ����ܹ�������,SE���ֶ����ı�Ӧ��һ��ֻ��һ����Ӧ��,��Ȼ��inference��ʱ��SE��ȥ��,Ҳ����ͨ��ѵ��ʱ��ֻ�õ����ı�,��SE�����������ڶ�Ӧλ�ú��ַ�����implicit��Լ���ɡ�