该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
笔记【4】到笔记【11】为李宏毅《深度强化学习》的部分;
笔记 【1】和笔记?【2】根据《强化学习纲要》整理而来;
笔记 【3】?和笔记?【12】根据《百度强化学习》?整理而来。
这一章的内容比较少,主要讲解了Q-learning在处理连续动作时的几种方法。
由于动作是连续时,“穷举所有的a然后选出其中Q值最大的”这一项操作难度较大,计算量大且耗时,所以Q-learning采取以下几个方法来解决。
(1)第一个解决方法:我们可以使用所谓的sample方法,即随机sample出N个可能的action,然后一个一个带到我们的Q-function中,计算对应的N个Q value比较哪一个的值最大。但是这个方法因为是sample所以不会非常的精确。
(2)第二个解决方法:我们将这个continuous action问题,看为一个优化问题,从而自然而然地想到了可以用gradient ascend去最大化我们的目标函数。具体地,我们将action看为我们的变量,使用gradient ascend方法去update action对应的Q-value。但是这个方法通常的时间花销比较大,因为是需要迭代运算的。
(3)第三个解决方法:设计一个特别的network架构,设计一个特别的Q-function,使得argmax Q-value的问题变得非常容易。也就是这边的Q-function 不是一个general的 Q-function,特别设计一下它的样子,让你要找让这个 Q-function 最大的a的时候非常容易。但是这个方法的function不能随意乱设,其必须有一些额外的限制。具体的设计方法如下:
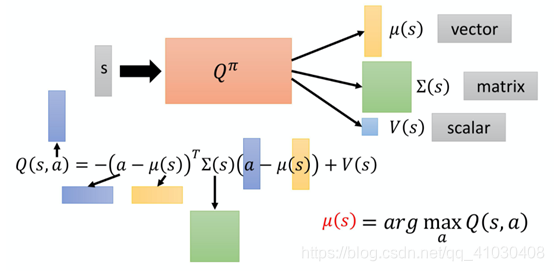
(4)第四个解决方法:不用Q-learning,毕竟用其处理continuous的action比较麻烦。?