[Դ�����] ����ѧϰ����������ps-lite ֮(3) ----- ������Customer
����Ŀ¼
0x00 ժҪ
�����Dz�������������ƪ,����ps-lite��Customerģ�顣
Ŀǰ�����ʾ� (PostOffice)��ͨ��ģ��С�Ƴ�(Van),��������Ҫ�����ʾֵĿͻ�Customer��
Customer ���� SimpleApp ���ʾֵĴ���������Ϊ worker,server ��Ҫ���о������㷨��,���� worker,server ������������ص��շ���Ϣ���� ���ܽ�/ת�Ƶ� Customer ֮�С�
��ϵ������������:
[Դ�����] ����ѧϰ����������ps-lite ֮(1) ----- PostOffice
[Դ�����] ����ѧϰ����������ps-lite(2) ----- ͨ��ģ��Van
0x01 ��Դ
1.1 Ŀǰ����
�����ܽ�һ��Ŀǰ������״̬:
- PostOffice:һ������ģʽ��ȫ�ֹ�����,һ�� node ���������ھ���һ��PostOffice,�����������Ա��Node���й���;
- Van:ͨ��ģ��,�����������ڵ������ͨ�ź�Message��ʵ���շ�������PostOffice����һ��Van��Ա;
- SimpleApp:KVServer��KVWorker�ĸ���,���ṩ�˼�Request, Wait, Response,Process����;KVServer��KVWorker�ֱ�����Լ���ʹ����д����Щ����;
- Node :��Ϣ��,�洢�˱��ڵ�Ķ�Ӧ��Ϣ,ÿ�� Node ����ʹ�� hostname + port ��Ψһ��ʶ��
- Customer:ÿ��SimpleApp�������һ��Customer��ij�Ա,��Customer��Ҫ��PostOffice����ע��,������Ҫ����:
- ��Ϊһ�����ͷ�,������SimpleApp���ͳ�ȥ����Ϣ�Ļظ����;
- ��Ϊ���շ�,ά��һ��Node����Ϣ����,ΪNode������Ϣ;
�˽�һ����������Ļ������������Ǹ��õ����������,��������������Ҫ���� Customer ������ʹ�õ�,����Ŀǰ�Ѿ�������������,���ǾͿ����������������ʹ��Customer��
1.2 Postoffice
�� PostOffice ֮��,�����³�Ա����:
// app_id -> (customer_id -> customer pointer)
std::unordered_map<int, std::unordered_map<int, Customer*>> customers_;
�Լ����³�Ա����,���ǰ�Customerע�ᵽcustomers_:
void Postoffice::AddCustomer(Customer* customer) {
std::lock_guard<std::mutex> lk(mu_);
int app_id = CHECK_NOTNULL(customer)->app_id();
// check if the customer id has existed
int customer_id = CHECK_NOTNULL(customer)->customer_id();
customers_[app_id].insert(std::make_pair(customer_id, customer));
std::unique_lock<std::mutex> ulk(barrier_mu_);
barrier_done_[app_id].insert(std::make_pair(customer_id, false));
}
Customer* Postoffice::GetCustomer(int app_id, int customer_id, int timeout) const {
Customer* obj = nullptr;
for (int i = 0; i < timeout * 1000 + 1; ++i) {
{
std::lock_guard<std::mutex> lk(mu_);
const auto it = customers_.find(app_id);
if (it != customers_.end()) {
std::unordered_map<int, Customer*> customers_in_app = it->second;
obj = customers_in_app[customer_id];
break;
}
}
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
return obj;
}
���,���ǿ��Կ���������:
- һ�� app ʵ�����Զ�Ӧ��� Customer;
- Customer ��Ҫע�ᵽ Postoffice ֮��;
1.3 Van
�� Van ��,���ǿ��Կ���,������������Ϣʱ��,��:
- ������Ϣ�е� app_id ��Postoffice ֮�еõ� customer_id;
- ���� customer_id �� Postoffice ֮�еõ� Customer;
- ���� Customer �� Accept ������������Ϣ;
void Van::ProcessDataMsg(Message* msg) {
// data msg
int app_id = msg->meta.app_id;
int customer_id =
Postoffice::Get()->is_worker() ? msg->meta.customer_id : app_id;
auto* obj = Postoffice::Get()->GetCustomer(app_id, customer_id, 5);
obj->Accept(*msg);
}
�������֪��:
- һ�� app ʵ�����Զ�Ӧ��� Customer;
- Customer ��Ҫע�ᵽ Postoffice ֮��;
- ������Ϣʱ���������Ϣ�е�app id�ҵ� Customer,�Ӷ����� Customer �� Accept ��������������������Ϣ;
1.4 Customer
�� Customer ֮�����ǿ��Կ���,Accept �����þ����� Customer �� queue ֮�в�����Ϣ��
ThreadsafePQueue recv_queue_;
inline void Accept(const Message& recved) {
recv_queue_.Push(recved);
}
Customer������Ҳ������һ�������߳� recv_thread_,ʹ�� Customer::Receiving(),���е���ע���recv_handle_��������Ϣ���д�����
std::unique_ptr<std::thread> recv_thread_;
recv_thread_ = std::unique_ptr<std::thread>(new std::thread(&Customer::Receiving, this));
void Customer::Receiving() {
while (true) {
Message recv;
recv_queue_.WaitAndPop(&recv);
if (!recv.meta.control.empty() &&
recv.meta.control.cmd == Control::TERMINATE) {
break;
}
recv_handle_(recv);
if (!recv.meta.request) {
std::lock_guard<std::mutex> lk(tracker_mu_);
tracker_[recv.meta.timestamp].second++;
tracker_cond_.notify_all();
}
}
}
1.5 Ŀǰ��
������ǿ��Եó�Ŀǰ��(������Ϣ��)����:
- worker�ڵ� ���� server�ڵ� �ڳ�����ʼ��ִ��
Postoffice::start()�� Postoffice::start()���ʼ���ڵ���Ϣ,���ҵ���Van::start()��Van::start()����һ�������߳�,ʹ��Van::Receiving()�����������յ���message��Van::Receiving()���պ���Ϣ֮��,���ݲ�ͬ����ִ�в�ͬ���������������Ϣ,�����Ҫ��һ������,�����ProcessDataMsg:- ������Ϣ�е�app id�ҵ�
Customer�� - ����Ϣ���ݸ�
Customer::Accept������
- ������Ϣ�е�app id�ҵ�
Customer::Accept()��������Ϣ���ӵ�һ������recv_queue_;Customer������Ҳ������һ�������߳�recv_thread_,ʹ�� Customer::Receiving()- ��
recv_queue_����ȡ��Ϣ�� - ����ע���
recv_handle_��������Ϣ���д�����
- ��
��Ҫ��������,����������ͼ������˳�����,����Ҳ���Կ���, Van,Postoffice,Customer ��������˴�֮����Щ�����,������һ�����������:
+--------------------------+
| Van |
| |
DataMessage +-----------> Receiving |
| 1 + | +---------------------------+
| | | | Postoffice |
| | 2 | | |
| v | GetCustomer | |
| ProcessDataMsg <------------------> unordered_map customers_|
| + | 3 | |
| | | +---------------------------+
+--------------------------+
|
|
| 4
|
+-------------------------+
| Customer | |
| | |
| v |
| Accept |
| + |
| | |
| | 5 |
| v |
| recv_queue_ |
| + |
| | 6 |
| | |
| v |
| Receiving |
| + |
| | 7 |
| | |
| v |
| recv_handle_ |
| |
+-------------------------+
�������Ǿ���ϸ�����¾�������
0x02 ������
��������Ҫ����һЩ�����ࡣ
2.1 SArray
SArray �������ص�:
- SArray �ǹ������ݵ���������,�ṩ���� std::vector �Ĺ��ܡ�
- SArray ���Դ� std::vector ����������
- SArray ������ C ָ��һ��������ֵ,����ij��SArray������Ϊ0ʱ,���Զ����ո�SArray���ڴ档
- ��������Ϊһ���㿽����vector,�ܼ���vector�����ݽṹ��
2.2 KVPairs
��ps-lite��,ÿ��server ӵ��һ��������key,�Լ���Щkey��Ӧ��value��key��value�Ƿֿ��洢��,ÿ��key���ܶ�Ӧ���value,�����Ҫ��¼ÿ��key�ij���,���Ծ����� KVPairs��
KVPairs �ص�����:
- KVPairs��װ��Key-Value�ṹ,��������һ������ѡ��,ӵ��keys,values,lens��3�����顣
- KVPairs ����SArray keys,SArray vals,SArray lens��ģ���ࡣKey��ʵ��int64�ı���,Val��ģ�������
- lens��keys �ȳ�,��ʾÿ��key��Ӧ��value�ĸ�����
- lens��Ϊ��,��ʱvalues��ƽ�֡�
��������:
- ��keys=[1,5],lens=[2,3],��ôkeys[0] ��Ӧ�����ݾ��� :values[0] �� values[1],��keys[1] ��Ӧ�����ݾ��� values[2],values[3],values[5]��
- �����lenΪ��,��values.size()������keys.size()(�˴�Ϊ2)�ı���,key[0]��key[1]����Ӧһ���values��
��������:
struct KVPairs {
// /** \brief empty constructor */
// KVPairs() {}
/** \brief the list of keys */
SArray<Key> keys;
/** \brief the according values */
SArray<Val> vals;
/** \brief the according value lengths (could be empty) */
SArray<int> lens; // key��Ӧvalue�ij���vector
/** \brief priority */
int priority = 0;
};
2.3 Node
Node��װ�˽ڵ���Ϣ,�����ɫ,ip,�˿�,�Ƿ��ǻָ��ڵ㡣
struct Node {
/** \brief the empty value */
static const int kEmpty;
/** \brief default constructor */
Node() : id(kEmpty), port(kEmpty), is_recovery(false) {}
/** \brief node roles */
enum Role { SERVER, WORKER, SCHEDULER };
/** \brief the role of this node */
Role role;
/** \brief node id */
int id;
/** \brief customer id */
int customer_id;
/** \brief hostname or ip */
std::string hostname;
/** \brief the port this node is binding */
int port;
/** \brief whether this node is created by failover */
bool is_recovery;
};
2.4 Control
Control :��װ�˿�����Ϣ��meta��Ϣ,barrier_group(���ڱ�ʶ��Щ�ڵ���Ҫͬ��,��command=BARRIERʱʹ��),node(Node��,���ڱ�ʶ�����������Щ�ڵ�ʹ��)��,����ǩ����
���Կ���,Control �Ͱ�����������ܵ� Node ���͡�
struct Control {
/** \brief empty constructor */
Control() : cmd(EMPTY) { }
/** \brief return true is empty */
inline bool empty() const { return cmd == EMPTY; }
/** \brief all commands */
enum Command { EMPTY, TERMINATE, ADD_NODE, BARRIER, ACK, HEARTBEAT };
/** \brief the command */
Command cmd;
/** \brief node infos */
std::vector<Node> node;
/** \brief the node group for a barrier, such as kWorkerGroup */
int barrier_group;
/** message signature */
uint64_t msg_sig;
};
2.5 Meta
Meta :����Ϣ��Ԫ���ݲ���,����ʱ���,������id,������id,������ϢControl,��Ϣ���͵�;
struct Meta {
/** \brief the empty value */
static const int kEmpty;
/** \brief default constructor */
Meta() : head(kEmpty), app_id(kEmpty), customer_id(kEmpty),
timestamp(kEmpty), sender(kEmpty), recver(kEmpty),
request(false), push(false), pull(false), simple_app(false) {}
/** \brief an int head */
int head;
/** \brief the unique id of the application of messsage is for*/
int app_id;
/** \brief customer id*/
int customer_id;
/** \brief the timestamp of this message */
int timestamp;
/** \brief the node id of the sender of this message */
int sender;
/** \brief the node id of the receiver of this message */
int recver;
/** \brief whether or not this is a request message*/
bool request;
/** \brief whether or not a push message */
bool push;
/** \brief whether or not a pull message */
bool pull;
/** \brief whether or not it's for SimpleApp */
bool simple_app;
/** \brief an string body */
std::string body;
/** \brief data type of message.data[i] */
std::vector<DataType> data_type;
/** \brief system control message */
Control control;
/** \brief the byte size */
int data_size = 0;
/** \brief message priority */
int priority = 0;
};
2.6 Message
2.6.1 �ṹ
Message ��Ҫ���͵���Ϣ,��������:
-
��Ϣͷ meta:����Ԫ����(ʹ����Protobuf ��������ѹ��),����:
- ������Ϣ(Control)��ʾ�����Ϣ��ʾ������(������ֹ,ȷ��ACK,ͬ����),�������:
- ��������;
- �ڵ��б�(vector),�ڵ����:
- �ڵ�Ľ�ɫ
- ip, port
- id
- �Ƿ��ǻָ��ڵ�
- group id��ʾ������������˭ִ��;
- ����ǩ��;
- ������;
- ������;
- ʱ���;
- ��
- ������Ϣ(Control)��ʾ�����Ϣ��ʾ������(������ֹ,ȷ��ACK,ͬ����),�������:
-
��Ϣ�� body:���Ƿ��͵�����,ʹ�����Զ���� SArray ��������,�������ݿ���;
2.6.2 ����ϵ
������֮�������ϵ����:
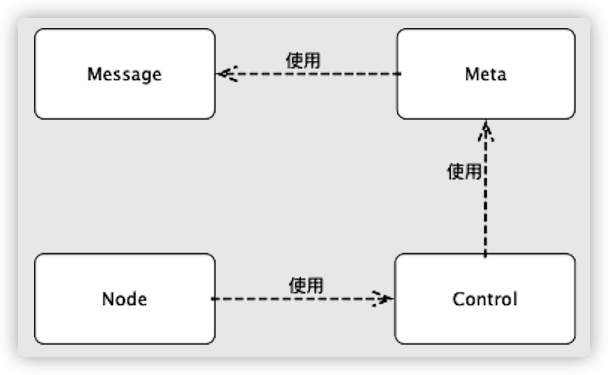
Message�е�ijЩ������Ҫ����Meta�����,�Դ����ơ�
2.6.3 message����
message ������������:
- ADD_NODE:worker��server��shceduler���нڵ�����
- BARRIER:�ڵ���ͬ��������Ϣ
- HEARTBEAT:�ڵ��������ź�,check alive
- TERMINATE:�ڵ��˳��ź�
- EMPTY:��ͨ��Ϣ,���� push or pull
2.6.4 ����
���嶨������:
struct Message {
/** \brief the meta info of this message */
Meta meta;
/** \brief the large chunk of data of this message */
std::vector<SArray<char> > data;
/**
* \brief push array into data, and add the data type
*/
template <typename V>
void AddData(const SArray<V>& val) {
CHECK_EQ(data.size(), meta.data_type.size());
meta.data_type.push_back(GetDataType<V>());
SArray<char> bytes(val);
meta.data_size += bytes.size();
data.push_back(bytes);
}
};
ÿ�η�����Ϣʱ,��Ϣ�Ͱ������ʽ��װ��,��������Ϣ�����Ա(Customer��)�ͻᰴ��Meta֮�е���Ϣ����Ϣ�ͻ�������
0x03 Customer
3.1 ����
Customer ��ʵ����������:
- ��Ϊһ�����ͷ�,������SimpleApp���ͳ�ȥÿ��Request��Ӧ��Response���;
- ��Ϊ���շ�,��Ϊ���Լ��Ľ����̺߳ͽ�����Ϣ����,����Customerʵ��������Ϊһ��������Ϣ��������(����˵�������һ����)����;
�����ص�����:
-
ÿ��SimpleApp�������һ��Customer��ij�Ա,��Customer��Ҫ��PostOffice����ע�ᡣ
-
��Ϊ Customer ͬʱ��Ҫ����Message �����䱾����û�нӹ�����,���ʵ�ʵ�Response��Message��Ҫ�ⲿ�����߸�����,���Թ��ܺ�ְ�����е���ѡ�
-
ÿһ�����Ӷ�Ӧһ��Customerʵ��,ÿ��Customer����ij��node id���,������ǰ�ڵ㷢�͵���Ӧnode id�ڵ㡣���ӶԷ���id��Customerʵ����id��ͬ��
-
�½�һ��request,�᷵��һ��timestamp,���timestamp����Ϊ���request��id,ÿ�����������1,��Ӧ��resҲ������1,����waitʱ�ᱣ֤ ����������Wait�Դ�ΪIDʶ��
3.2 ����
3.2.1 ��Ա����
�������ȿ���Customer�ij�Ա������
��Ҫע��,������ڱ������ܵ�����,���ǿ��Դ���Ϣ��������,�������һ��������Ϣ,�������������������,�������ǰ� Customer �ij�Ա����Ҳ�������˳������ :
Van::ProcessDataMsg ---> Customer::Accept ---> Customer::recv_queue_ ---> Customer::recv_thread_ ---> Customer::recv_handle_
��Ҫ��Ա��������:
-
ThreadsafePQueue recv_queue_ :�̰߳�ȫ����Ϣ����;
-
std::unique_ptr< std::thread> recv_thread_ : ���ϴ� recv_queue ��ȡmessage������ recv_handle_;
-
RecvHandle recv_handle_ :worker ���� server ����Ϣ����������
- ��Customer���յ�request��Ĵ�������(SimpleApp::Process);
- Customer��������һ���߳�,������customer����������,ʹ��recv_handle_���������ܵ�����,������ʹ����һ���̰߳�ȫ����,Accept()������������һֱ������Ϣ,
- ���ܵ�����Ϣ������Van��receiving thread,��ÿ���ڵ��Van�����յ�message��,����message�IJ�ͬ,���͵���ͬ��customer�����С�
- ����Worker,����KVWorker,recv_handle_������ȡ��msg�е�����,
- ����Server,��Ҫʹ��set_request_handle�����ö�Ӧ�Ĵ�������,��KVServerDefaultHandle,
-
std::vector<std::pair<int, int>> tracker_ :request & response ��ͬ��������
- tracker_��Customer��������¼request��response��״̬��map����¼��ÿ�� request(ʹ��request id)���ܷ����˶��ٽڵ� �Լ� �Ӷ��ٸ��ڵ㷵�ص� response�Ĵ���,
- tracker_�±�Ϊÿ��request ��timestamp,��Request��š�
- tracker_[i] . first ��ʾ���������˶��ٽڵ�,�����ڵ�Ӧ�յ���Response������
- tracker_[i] . second ��ʾĿǰΪֹʵ���յ���Response������
3.2.2 ���嶨��
���嶨������:
class Customer {
public:
/**
* \brief the handle for a received message
* \param recved the received message
*/
using RecvHandle = std::function<void(const Message& recved)>;
/**
* \brief constructor
* \param app_id the globally unique id indicating the application the postoffice
* serving for
* \param customer_id the locally unique id indicating the customer of a postoffice
* \param recv_handle the functino for processing a received message
*/
Customer(int app_id, int customer_id, const RecvHandle& recv_handle);
/**
* \brief desconstructor
*/
~Customer();
/**
* \brief return the globally unique application id
*/
inline int app_id() { return app_id_; }
/**
* \brief return the locally unique customer id
*/
inline int customer_id() { return customer_id_; }
/**
* \brief get a timestamp for a new request. threadsafe
* \param recver the receive node id of this request
* \return the timestamp of this request
*/
int NewRequest(int recver);
/**
* \brief wait until the request is finished. threadsafe
* \param timestamp the timestamp of the request
*/
void WaitRequest(int timestamp);
/**
* \brief return the number of responses received for the request. threadsafe
* \param timestamp the timestamp of the request
*/
int NumResponse(int timestamp);
/**
* \brief add a number of responses to timestamp
*/
void AddResponse(int timestamp, int num = 1);
/**
* \brief accept a received message from \ref Van. threadsafe
* \param recved the received the message
*/
inline void Accept(const Message& recved) {
recv_queue_.Push(recved);
}
private:
/**
* \brief the thread function
*/
void Receiving();
int app_id_;
int customer_id_;
RecvHandle recv_handle_;
ThreadsafePQueue recv_queue_;
std::unique_ptr<std::thread> recv_thread_;
std::mutex tracker_mu_;
std::condition_variable tracker_cond_;
std::vector<std::pair<int, int>> tracker_;
DISALLOW_COPY_AND_ASSIGN(Customer);
};
3.3 �����߳�
�ڹ���������,�Ὠ�������̡߳�
recv_thread_ = std::unique_ptr<std::thread>(new std::thread(&Customer::Receiving, this));
�̴߳�����������,����������:
- ����Ϣ�����ϵȴ�,�������Ϣ��ȡ��;
- ʹ�� recv_handle_ ������Ϣ;
- ��� meta.request Ϊ false,˵���� response,������ tracker ֮�ж�Ӧ������
void Customer::Receiving() {
while (true) {
Message recv;
recv_queue_.WaitAndPop(&recv);
if (!recv.meta.control.empty() &&
recv.meta.control.cmd == Control::TERMINATE) {
break;
}
recv_handle_(recv);
if (!recv.meta.request) {
std::lock_guard<std::mutex> lk(tracker_mu_);
tracker_[recv.meta.timestamp].second++;
tracker_cond_.notify_all();
}
}
}
��Ϊ��ʹ�� recv_handle_ �����о����ҵ����,������������Ϳ��� recv_handle_ �������,��ʵҲ���� Customer ��ι���,ʹ�á�
3.4 ����
������Ҫ��ǰʹ�����Ľ�Ҫ������һЩ��,��Ϊ������ Customer ��ʹ����,��ϵ�̫�����ˡ�
3.4.1 In SimpleApp
�������ǿ���SimpleApp,���Ǿ��������ܽڵ�Ļ��ࡣ
ÿ��SimpleApp�������һ��Customer��ij�Ա,��Customer��Ҫ��PostOffice����ע��,
������� �½�һ��Custom�����ʼ��obj_��Ա��
inline SimpleApp::SimpleApp(int app_id, int customer_id) : SimpleApp() {
using namespace std::placeholders;
obj_ = new Customer(app_id, customer_id, std::bind(&SimpleApp::Process, this, _1));
}
�����ٿ���SimpleApp���������ࡣ
3.4.2 KVServer(app_id)
KVServer����Ҫ��������key-values����,����һЩҵ�����,�����ݶȸ��¡���Ҫ����Ϊ:Process() ��Response()��
���乹�캯���л�:
- �½�һ��Customer��������ʼ�� obj_ ��Ա;
- �� KVServer::Process ����Customer���캯��,��ʵ���ǰ� Process ����������
Customer:: recv_handle_; - ����Server��˵,app_id = custom_id = server��s id;
���캯������:
/**
* \brief constructor
* \param app_id the app id, should match with \ref KVWorker's id
*/
explicit KVServer(int app_id) : SimpleApp() {
using namespace std::placeholders;
obj_ = new Customer(app_id, app_id, std::bind(&KVServer<Val>::Process, this, _1));
}
3.4.3 KVWorker(app_id, custom_id)
KVWorker�� ��Ҫ������Server Push/Pull �Լ��� key-value ���ݡ��������·���: Push(),Pull(),Wait()��
���乹�캯���л�:
- ��Ĭ�ϵ�KVWorker::DefaultSlicer��slicer_��Ա;
- �½�һ��Customer�����ʼ��obj_ ��Ա,��KVWorker::Process����Customer���캯��,��ʵ���ǰ� Process ���������� Customer:: recv_handle_;
/**
* \brief constructor
*
* \param app_id the app id, should match with \ref KVServer's id
* \param customer_id the customer id which is unique locally
*/
explicit KVWorker(int app_id, int customer_id) : SimpleApp() {
using namespace std::placeholders;
slicer_ = std::bind(&KVWorker<Val>::DefaultSlicer, this, _1, _2, _3);
obj_ = new Customer(app_id, customer_id, std::bind(&KVWorker<Val>::Process, this, _1));
}
3.4.4 Customer
��������������:
- �ֱ��ô��빹�캯���IJ�����ʼ��
app_id_, custom_id_ , recv_handle��Ա - ����PostOffice::AddCustomer����ǰCustomerע�ᵽPostOffice;
- PostOffice��customers_��Ա: �ڶ�Ӧ��app_id��Ԫ��������custom_id;
- PostOffice��barrier_done_��Ա����custom_id��ͬ��״̬��Ϊfalse
- ����һ��Receiving�߳�recv_thread_;
���幹����������:
Customer::Customer(int app_id, int customer_id, const Customer::RecvHandle& recv_handle)
: app_id_(app_id), customer_id_(customer_id), recv_handle_(recv_handle) {
Postoffice::Get()->AddCustomer(this);
recv_thread_ = std::unique_ptr<std::thread>(new std::thread(&Customer::Receiving, this));
}
3.4.5 ����
3.4.5.1 ʾ������
��ҿ��ܶ� app_id �� customer_id ��Щ����,����:
�� KVWorker ������������:
- app_id the app id, should match with KVServer��s id
- customer_id the customer id which is unique locally
�� KVServer ������������:
- app_id the app id, should match with KVWorker��s id
����ʹ��Դ���Դ��� tests/test_kv_app_multi_workers.cc ������һ�� app_id �� customer_id ������ϵ��
������ǰ��:worker���� customer_id ��ȷ���Լ���������customer id �� worker �����б�����ȷ�� ��worker ��Ӧ�� key �ķ�Χ��
�ӽű��п��Կ�����,ʹ������������:
find test_* -type f -executable -exec ./repeat.sh 4 ./local.sh 2 2 ./{} \;
�ļ���������һ�� server �� ���� worker��
- server �� app_id, customer_id ���� 0;
- worker �� app_id �� 0,customer_id �ֱ��� 0,1;
- ʹ�� std::thread ��ִ�� worker,�����˵,��ͬһ���������������� worker �ڵ㡣��Ϳ��Խ��� KVWorker ���������� ע���е� ��the customer id which is unique locally����
- ����,�� Postoffice �� std::unordered_map<int, std::unordered_map<int, Customer*>> customers_ ��Ա������������:
- [0, [ 0, Customer_0] ],��һ�� 0 �� app id, �ڶ��� 0 ��customer id
- [0, [ 1, Customer_1] ],��һ�� 0 �� app id, �ڶ��� 1 ��customer id
���,���ǿ���������:
- app id ����ȷ��һ��Ӧ�á�
- customer id �����ڱ�Ӧ��(app id)��ȷ��һ�� local worker,����һ�� server��
- ���� KVServer ����������˵,app id ��Ҫ�� KVWorker��s id һ��,��ʵ����˵,��ҵ� app id ��Ҫһ����
- customer id ������� worker �����б�����ȷ�� ��worker ��Ӧ�� key �ķ�Χ��
�����������:
#include <cmath>
#include "ps/ps.h"
using namespace ps;
void StartServer() { // ��������
if (!IsServer()) return;
auto server = new KVServer<float>(0);
server->set_request_handle(KVServerDefaultHandle<float>());
RegisterExitCallback([server](){ delete server; });
}
void RunWorker(int customer_id) { // ����worker
Start(customer_id);
if (!IsWorker()) {
return;
}
KVWorker<float> kv(0, customer_id);
// init
int num = 10000;
std::vector<Key> keys(num);
std::vector<float> vals(num);
int rank = MyRank();
srand(rank + 7);
for (int i = 0; i < num; ++i) {
keys[i] = kMaxKey / num * i + customer_id;
vals[i] = (rand() % 1000);
}
// push
int repeat = 50;
std::vector<int> ts;
for (int i = 0; i < repeat; ++i) {
ts.push_back(kv.Push(keys, vals));
// to avoid too frequency push, which leads huge memory usage
if (i > 10) kv.Wait(ts[ts.size()-10]);
}
for (int t : ts) kv.Wait(t);
// pull
std::vector<float> rets;
kv.Wait(kv.Pull(keys, &rets));
// pushpull
std::vector<float> outs;
for (int i = 0; i < repeat; ++i) {
kv.Wait(kv.PushPull(keys, vals, &outs));
}
float res = 0;
float res2 = 0;
for (int i = 0; i < num; ++i) {
res += fabs(rets[i] - vals[i] * repeat);
res += fabs(outs[i] - vals[i] * 2 * repeat);
}
CHECK_LT(res / repeat, 1e-5);
CHECK_LT(res2 / (2 * repeat), 1e-5);
LL << "error: " << res / repeat << ", " << res2 / (2 * repeat);
// stop system
Finalize(customer_id, true);
}
int main(int argc, char *argv[]) {
// start system
bool isWorker = (strcmp(argv[1], "worker") == 0);
if (!isWorker) {
Start(0);
// setup server nodes,����server�ڵ�
StartServer();
Finalize(0, true);
return 0;
}
// run worker nodes,��������worker�ڵ�
std::thread t0(RunWorker, 0);
std::thread t1(RunWorker, 1);
t0.join();
t1.join();
return 0;
}
3.4.5.2 ȷ������
�����ٻ����� Postoffice �ij�ʼ��,���Կ���,����ʱ��,worker���� customer_id ��ȷ���Լ�������������,customer id �� worker �����б�����ȷ�� ��worker ��Ӧ�� key �ķ�Χ��
void Postoffice::Start(int customer_id, const char* argv0, const bool do_barrier) {
// init node info.
// �������е�worker,����node����
for (int i = 0; i < num_workers_; ++i) {
int id = WorkerRankToID(i);
for (int g : {id, kWorkerGroup, kWorkerGroup + kServerGroup,
kWorkerGroup + kScheduler,
kWorkerGroup + kServerGroup + kScheduler}) {
node_ids_[g].push_back(id);
}
}
// �������е�server,����node����
for (int i = 0; i < num_servers_; ++i) {
int id = ServerRankToID(i);
for (int g : {id, kServerGroup, kWorkerGroup + kServerGroup,
kServerGroup + kScheduler,
kWorkerGroup + kServerGroup + kScheduler}) {
node_ids_[g].push_back(id);
}
}
// ����scheduler��node
for (int g : {kScheduler, kScheduler + kServerGroup + kWorkerGroup,
kScheduler + kWorkerGroup, kScheduler + kServerGroup}) {
node_ids_[g].push_back(kScheduler);
}
init_stage_++;
}
// start van
van_->Start(customer_id); // ������ customer_id
......
// do a barrier here,������ customer_id
if (do_barrier) Barrier(customer_id, kWorkerGroup + kServerGroup + kScheduler);
}
�ٿ��� Van �ij�ʼ��,Ҳ���� customer_id ��ȷ���Լ���������
void Van::Start(int customer_id) {
if (init_stage == 0) {
// get my node info
if (is_scheduler_) {
my_node_ = scheduler_;
} else {
my_node_.hostname = ip;
my_node_.role = role;
my_node_.port = port;
my_node_.id = Node::kEmpty;
my_node_.customer_id = customer_id; // ������ customer_id
}
}
if (!is_scheduler_) {
// let the scheduler know myself
Message msg;
Node customer_specific_node = my_node_;
customer_specific_node.customer_id = customer_id; // ������ customer_id
msg.meta.recver = kScheduler;
msg.meta.control.cmd = Control::ADD_NODE;
msg.meta.control.node.push_back(customer_specific_node);
msg.meta.timestamp = timestamp_++;
Send(msg);
}
......
}
����,Ҳ�ܹ�������Ϊʲô�� KVWorker ������Ϣʱ��ʹ�� app_id �� customer_id��
template <typename Val>
void KVWorker<Val>::Send(int timestamp, bool push, bool pull, int cmd, const KVPairs<Val>& kvs) {
.....
for (size_t i = 0; i < sliced.size(); ++i) {
Message msg;
msg.meta.app_id = obj_->app_id(); // ע������
msg.meta.customer_id = obj_->customer_id();// ע������
msg.meta.request = true;
......
Postoffice::Get()->van()->Send(msg);
}
}
�� KVServer ֮��,Ҳ��Ҫ�ڻ�Ӧ��Ϣʱ��,ʹ�� app_id �� customer_id��
template <typename Val>
void KVServer<Val>::Response(const KVMeta& req, const KVPairs<Val>& res) {
Message msg;
msg.meta.app_id = obj_->app_id();// ע������
msg.meta.customer_id = req.customer_id;// ע������
msg.meta.request = false;
msg.meta.push = req.push;
msg.meta.pull = req.pull;
msg.meta.head = req.cmd;
msg.meta.timestamp = req.timestamp;
msg.meta.recver = req.sender;
......
Postoffice::Get()->van()->Send(msg);
}
3.4.5.3 ����
��ô��������,Ϊʲô Server ��,app_id �� customer_id ���?
��ΪĿǰû�� ps ���������,���Բ²���:
�� ps ������,Server ��Ҳ���ж�� cusomer,���dz��ھ���Ŀ��,�� ps-lite ֮��ɾ�����ⲿ�ֹ���,����� ps-lite ֮��,app_id �� customer_id ��ȡ�
3.5 Ŀǰ��
��������ٴ���������(������Ϣ��)����:
-
worker�ڵ� ���� server�ڵ� �ڳ�����ʼ��ִ��
Postoffice::start()�� -
Postoffice::start()���ʼ���ڵ���Ϣ,���ҵ���Van::start()�� -
Van::start()����һ�������߳�,ʹ��Van::Receiving()�����������յ���message�� -
Van::Receiving()���պ���Ϣ֮��,���ݲ�ͬ����ִ�в�ͬ���������������Ϣ,�����Ҫ��һ������,����� ProcessDataMsg:- ������Ϣ�е�app id�ҵ� Customer,�������customer id�IJ�ͬ��message������ͬ��customer��recv thread��
- ����Ϣ���ݸ�
Customer::Accept������
-
Customer::Accept() ��������Ϣ���ӵ�һ������
recv_queue_; -
Customer ������Ҳ������һ�������߳�
recv_thread_,ʹ�� Customer::Receiving()- ��
recv_queue_����ȡ��Ϣ�� - ��� (!recv.meta.request) ,��˵���� response,��
tracker_[req.timestamp].second++ - ����ע���
recv_handle_��������Ϣ���д�����
- ��
-
����worker��˵,��ע���
recv_handle_��KVWorker::Process()��������Ϊworker��recv thread���ܵ�����Ϣ��Ҫ�Ǵ�server��pull������KV��,��˸�Process()��Ҫ�ǽ���message�е�KV��; -
������Server��˵,��ע���
recv_handle_��KVServer::Process()��������Ϊserver���ܵ���worker��push������KV��,��Ҫ������д���,��˸�Process()�����е��õ��û�ͨ��KVServer::set_request_handle()����ĺ�������
Ŀǰ������ͼ,�� �� 8 ��,recv_handle_ ָ�� KVServer::Process ���� KVWorker::Process��
+--------------------------+
| Van |
| |
DataMessage +-----------> Receiving |
| 1 + | +---------------------------+
| | | | Postoffice |
| | 2 | | |
| v | GetCustomer | |
| ProcessDataMsg <------------------> unordered_map customers_|
| + | 3 | |
| | | +---------------------------+
+--------------------------+
|
|
| 4
|
+-------------------------+
| Customer | |
| | |
| v |
| Accept |
| + |
| | |
| | 5 |
| v |
| recv_queue_ | +-----------------+
| + | |KVWorker |
| | 6 | +--------> | |
| | | | 8 | Process |
| v | | +-----------------+
| Receiving | |
| + | |
| | 7 | |
| | | | +-----------------+
| v | | |KVServer |
| recv_handle_+---------+--------> | |
| | 8 | Process |
+-------------------------+ +-----------------+
0x04 ���ܺ���
������Щ Customer �������DZ�����ģ����á�
4.1 Customer::NewRequest
4.1.1 ʵ��
�˺�����������:������һ�� request ʱ��,�����Դ� request �ļ���������,��������Ҫ��һ��Resquest������ʱ��,ʹ�ô˺�����
�ص�����:
-
ÿ�η�����Ϣǰ,���Ĵ�����Ϣ Ӧ�յ��� Response������
-
recver��ʾ�����ߵ�node_id,��Ϊps-lite��һ���������ܶ�Ӧ�ڶ��node_id,����ʹ��Postoffice���������е���ʵnode_id ����Ŀ��
-
����� kServerGroup ����Ϣ,kServerGroup ������3 �� server,�� num Ϊ 3,����Ӧ���յ� 3 ��response��tracker_ ��Ӧ��item ���� [3,0],��ʾӦ���յ� 3��,Ŀǰ�յ� 0 ����
-
�����ķ���ֵ������Ϊ��һ��ʱ���,���ʱ��� ����Ϊ���request��id,����waitʱ�ᱣ֤����Wait�Դ�ΪIDʶ��
int Customer::NewRequest(int recver) {
std::lock_guard<std::mutex> lk(tracker_mu_);
int num = Postoffice::Get()->GetNodeIDs(recver).size(); // recver ���ܻ����һ��group��
tracker_.push_back(std::make_pair(num, 0));
return tracker_.size() - 1; // �����˴������ʱ���timestamp,����customerʹ�����ֵ�������request
}
4.1.2 ����
������þ��������� worker �� server ����ʱ��
int ZPush(const SArray<Key>& keys,
const SArray<Val>& vals,
const SArray<int>& lens = {},
int cmd = 0,
const Callback& cb = nullptr,
int priority = 0) {
int ts = obj_->NewRequest(kServerGroup); // ��������
AddCallback(ts, cb);
KVPairs<Val> kvs;
kvs.keys = keys;
kvs.vals = vals;
kvs.lens = lens;
kvs.priority = priority;
Send(ts, true, false, cmd, kvs);
return ts;
}
4.2 Customer::AddResponse
4.2.1 ʵ��
������:���request�Ѿ�����response���м�����
�ص�����:
-
���ⲿ�������յ�Responseʱ,����AddResponse����Customer����
-
��������ij������ʵ���յ���Response��,��Ҫ���ڿͻ��˷�������ʱ,��ʱ��������ijЩserver��ͨ��(�˴�ͨ�ŵ�keysû�зֲ�����Щserver��),�ڿͻ��˾Ϳ�ֱ����Ϊ�ѽ��յ�Response��
-
����,��
Customer::Receiving��,��������һ����request�����,Ҳ�����Ӷ�Ӧ�������Response����tracker_[recv.meta.timestamp].second++; -
������и�ȱ��,���ڹ��ڵ��Ժ����õ���Request��Ϣ,û��ɾ���������������ĵ�����������������ֽ������ڽ��̵��������ڡ����,����ps-lite�����ܵ�ʱ����˻�������OOM��
void Customer::AddResponse(int timestamp, int num) {
std::lock_guard<std::mutex> lk(tracker_mu_);
tracker_[timestamp].second += num;
}
4.2.2 ����
�� KVWorker �� Send ���������,��ΪijЩ�����,(�˴�ͨ�ŵ�keysû�зֲ�����Щserver��),�ڿͻ��˾Ϳ�ֱ����Ϊ�ѽ��յ�Response,����Ҫ������
template <typename Val>
void KVWorker<Val>::Send(int timestamp, bool push, bool pull, int cmd, const KVPairs<Val>& kvs) {
// slice the message
SlicedKVs sliced;
slicer_(kvs, Postoffice::Get()->GetServerKeyRanges(), &sliced);
// need to add response first, since it will not always trigger the callback
int skipped = 0;
for (size_t i = 0; i < sliced.size(); ++i) {
if (!sliced[i].first) ++skipped;
}
obj_->AddResponse(timestamp, skipped); // �������
if ((size_t)skipped == sliced.size()) {
RunCallback(timestamp);
}
for (size_t i = 0; i < sliced.size(); ++i) {
const auto& s = sliced[i];
if (!s.first) continue;
Message msg;
msg.meta.app_id = obj_->app_id();
msg.meta.customer_id = obj_->customer_id();
msg.meta.request = true;
msg.meta.push = push;
msg.meta.pull = pull;
msg.meta.head = cmd;
msg.meta.timestamp = timestamp;
msg.meta.recver = Postoffice::Get()->ServerRankToID(i);
msg.meta.priority = kvs.priority;
const auto& kvs = s.second;
if (kvs.keys.size()) {
msg.AddData(kvs.keys);
msg.AddData(kvs.vals);
if (kvs.lens.size()) {
msg.AddData(kvs.lens);
}
}
Postoffice::Get()->van()->Send(msg);
}
}
4.3 Customer::WaitRequest
4.3.1 ʵ��
������:��������Ҫ�ȴ�ij������ȥ��Request��Ӧ��Responseȫ���յ�ʱ,ʹ�ô˺����������ȴ�,ֱ�� Ӧ�յ�Response�� ���� ʵ���յ���Response����
wait�����Ĺ��̾���tracker_cond_һֱ�����ȴ�,ֱ�����ͳ�ȥ���������Ѿ����ص�������ȡ�
void Customer::WaitRequest(int timestamp) {
std::unique_lock<std::mutex> lk(tracker_mu_);
tracker_cond_.wait(lk, [this, timestamp]{
return tracker_[timestamp].first == tracker_[timestamp].second;
});
}
4.3.2 ����
Wait ��������ʹ�� WaitRequest ��ȷ��������ɡ�
/**
* \brief Waits until a push or pull has been finished
*
* Sample usage:
* \code
* int ts = w.Pull(keys, &vals);
* Wait(ts);
* // now vals is ready for use
* \endcode
*
* \param timestamp the timestamp returned by the push or pull
*/
void Wait(int timestamp) { obj_->WaitRequest(timestamp); }
���Ǿ�����ε���,�����û����о���,����:
for (int i = 0; i < repeat; ++i) {
kv.Wait(kv.Push(keys, vals));
}
�������������ͬ�����Ե����⡣
0x05 ͬ������
��ͬ��workerͬʱ���������ʱ��,������Ϊ���硢�������õ����ԭ��,���²�ͬ��worker�Ľ����Dz�һ����,��ο���worker��ͬ��������һ���Ƚ���Ҫ�Ŀ��⡣
5.1 ͬ��Э��
һ����˵,������������첽����Э��:BSP(Bulk Synchronous Parallel),SSP(Stalness Synchronous Parallel)��ASP(Asynchronous Parallel),���ǵ�ͬ���������ηſ���Ϊ�������ļ����ٶ�,�㷨����ѡ������ɵ�ͬ��Э�顣
Ϊ�˽�����ܵ�����,ҵ�翪ʼ̽�������һ����ģ��,���ȳ����İ汾��ASPģʽ,��ASP֮���������һ����Լ��˵�ͬ��Э��BSP,�������������ASP��BSP��һ������,����SSP��
���������������:
-
ASP:task֮����ȫ������ȴ�,��ȫ����worker֮���˳��,ÿ��worker�����Լ��Ľ�����,����һ��������update,����ɵ�task,������һ�ֵ�ѵ����
-
�ŵ�:�����˵ȴ���task��ʱ��,������GPU�Ŀ���ʱ��,�����BSP��������Ӳ��Ч�ʡ������ٶȿ�,����������˼�Ⱥ�ļ�������,���е�worker���ڵĻ��������õȴ�
-
ȱ��:
- ������̿��ܻᵼ���ݶȱ������ʱ��Ȩ��,�Ӷ�����ͳ��Ч�ʡ�
- �����Բ�,��һЩ����²����ܱ�֤������
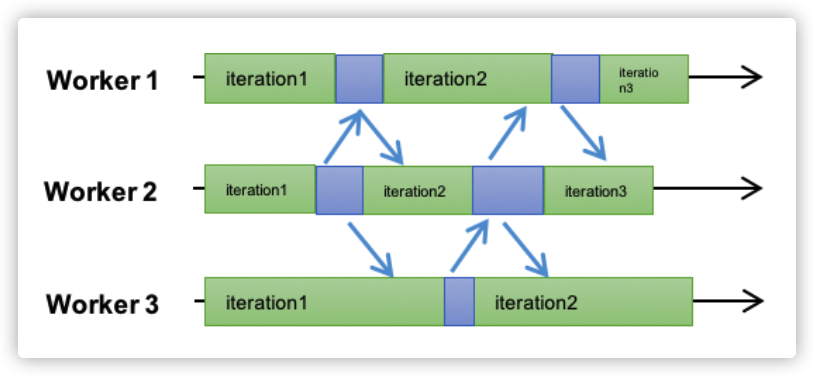
-
-
BSP:��һ��ֲ�ʽ������õ�ͬ��Э��,ÿһ�ֵ����ж���Ҫ�ȴ����е�task������ɡ�ÿ��worker��������ͬһ����������,ֻ��һ�������������е�worker�������,�Ż����һ��worker��server֮���ͬ���ͷ�Ƭ���¡�
-
BSP��ģʽ�͵���������Ϊ������batch size������,������ģ��������������ȫһ���ġ�ͬʱ,��Ϊÿ��worker��һ���������ǿ��Բ��м����,��������һ���IJ���������spark�õľ������ַ�ʽ��
-
�ŵ�:���÷�Χ��;ÿһ�ֵ�������������
-
ȱ��:ÿһ�ֵ�����,,BSPҪ��ÿ��worker�ȴ�����ͣ��������worker���ݶ�,��������Ҫ�ȴ�������task,�Ӷ�����������Ӳ��Ч��,���������������ʱ�䳤������worker group������������������worker����;���workerһ���Ϊstraggler��
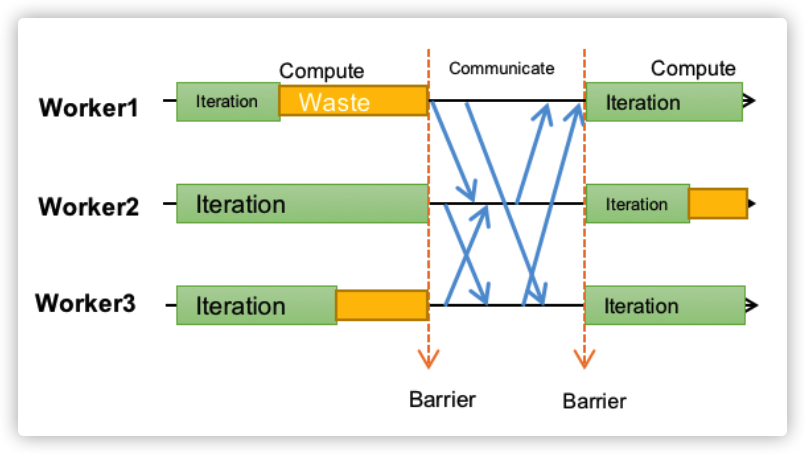
-
-
SSP:����һ���̶ȵ�task���Ȳ�һ��,�������һ����һ������,��Ϊstalenessֵ,������task�������������task staleness�ֵ�����
-
���ǰѽ�ASP��BSP��һ�����С���ȻASP��������ͬworker֮��ĵ���������������,��BSP��ֻ����Ϊ0,���Ҿ�ȡһ������s������SSP,BSP�Ϳ���ͨ��ָ��s=0���õ�����ASPͬ������ͨ���ƶ�s=�����ﵽ��
-
�ŵ�:һ���̶ȼ�����task֮��ĵȴ�ʱ��,�����ٶȽϿ졣
-
ȱ��:ÿһ�ֵ�����������������BSP,�ﵽͬ��������Ч��������Ҫ�����ֵĵ���,������Ҳ����BSP,�����㷨�����á�
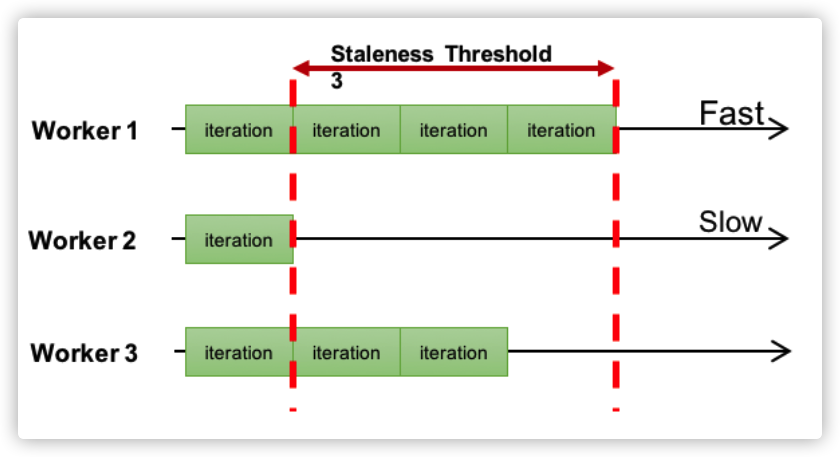
-
5.2 ����
�������������ᵽ,parameter server Ϊ�û��ṩ�˶�������������ʽ:
-
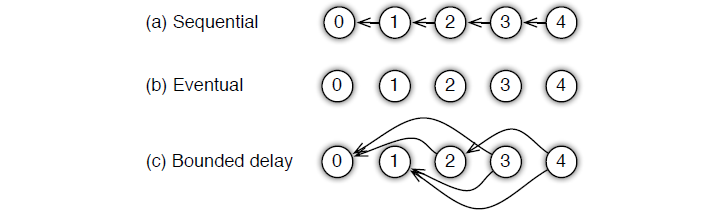
Sequential: ������ʵ�� synchronous task,����֮������˳���,ֻ����һ���������,���ܿ�ʼ��һ������;
-
Eventual: �� sequential �෴,��������֮��û��˳��,���Զ�������Լ�������,
-
Bounded Delay:����sequential �� eventual ֮���trade-off,��������һ�� �� \tau �� ��Ϊ������ʱʱ�䡣Ҳ����˵,ֻ�� > �� >\tau >�� ֮ǰ�����������,���ܿ�ʼһ���µ�����;���˵����:
- �� \tau �� = 0,������� Sequential;
- �� \tau �� = ��,������� Eventual;
5.3 ps-lite
ps-lite�����м����漰���ȴ�ͬ���ĵط�:
- Worker pull ���첽����,�����Ҫ�ȴ� pull ���,����Ե���Wait����֤customer�����request��response�������,����֤Pull��ɺ�������������;
- ��һ��worker��,���Դ��ڶ��Customer,����һ������barrier��,scheduler���յ�request����,Ȼ�����msg�ж���request,Ȼ��,��barrier_group�������node,node�ӵ���, Postoffice::Get()->Manage(*msg)��barrier_done_�е�customer_id��Ӧ��bool��true,���ͬ��������
- �������ڵ�����ʱ,Ҳ���Խ���һ��barrier;
�����ӵı���Asp,bsp,ssp����ͨ��������Ӧ��Command����ɡ�
0x06 �ֲ�ʽ�Ż�
6.1 ���ⶨ��
��������Ҫ�����������
min
?
w
��
i
=
1
n
f
(
x
i
,
y
i
,
w
)
\min_w \sum_{i=1}^n f(x_i, y_i, w)
wmin?i=1��n?f(xi?,yi?,w)
���� (yi, xi) ��һ��������,w��ģ��Ȩ�ء�
���ǿ���ʹ��������СΪb��С��������ݶ��½�(SGD)������������⡣ �ڲ��� t,���㷨�������ѡȡb������,Ȼ��ͨ�����湫ʽ����Ȩ��w
w
=
w
?
��
t
��
i
=
1
b
?
f
(
x
k
i
,
y
k
i
,
w
)
w = w - \eta_t \sum_{i=1}^b \nabla f(x_{k_i}, y_{k_i}, w)
w=w?��t?i=1��b??f(xki??,yki??,w)
����ʹ������������չʾ��ps-lite֮�����ʵ��һ���ֲ�ʽ�Ż��㷨��
6.2 Asynchronous SGD
��һ��ʾ����,���ǽ�SGD��չΪ�첽SGD�� ��������ά��ģ��Ȩ��w,����server k �����Ȩ��w�ĵ�k����,�� wk ��ʾ�� һ��Server��worker�յ��ݶ�,server k����������ά����Ȩ�ء�
t = 0;
while (Received(&grad)) {
w_k -= eta(t) * grad;
t++;
}
����һ��worker��˵,ÿһ����������ļ�����
Read(&X, &Y); // ��ȡһ�� minibatch ����
Pull(&w); // �ӷ�������ȥ���µ�Ȩ��
ComputeGrad(X, Y, w, &grad); // �����ݶ�
Push(grad); // ��Ȩ������������
ps-lite���ṩpush��pull����,worker ���������ȷ�������ݵ�serverͨ�š�
��ע��:�첽SGD���㷨ģʽ���뵥���汾��ͬ�� ����worker֮��û��ͨ��,����п�����һ��worker�����ݶȵ�ʱ��,����worker�����˷������ϵ�Ȩ�ء� ��,ÿ��worker���ܻ��õ��ӳٵ�Ȩ�ء�
6.3 Synchronized SGD
���첽�汾��ͬ,ͬ���汾���������뵥���㷨��ͬ�� ����ÿһ�ε�����Ҫ���е�worker������ݶ�,����ͬ����server�С�
����ʹ��scheduler ����������ͬ����
for (t = 0, t < num_iteration; ++t) {
for (i = 0; i < num_worker; ++i) {
IssueComputeGrad(i, t);
}
for (i = 0; i < num_server; ++i) {
IssueUpdateWeight(i, t);
}
WaitAllFinished();
}
IssueComputeGrad �� IssueUpdateWeight �ᷢ������� worker �� servers,Ȼ�� scheduler ����� WaitAllFinished �ȴ����з��͵����������
����һ��worker���ܵ�һ������,����������:
ExecComputeGrad(i, t) {
Read(&X, &Y); // ��ȡ���� minibatch = batch / num_workers ������
Pull(&w); // �ӷ�������ȡ����Ȩ��
ComputeGrad(X, Y, w, &grad); // �����ݶ�
Push(grad); // ��Ȩ������������
}
����㷨��ASGD������ͬ,ֻ��ÿ�β�����,ֻ�� b/num_workers��������������
�� server �ڵ�,��ASGD���,����һ���ۺϲ��衣�ǰ�����worker���ݶ��ۼ�����֮��,����� ѧϰ���ʽ��е�����
ExecUpdateWeight(i, t) {
for (j = 0; j < num_workers; ++j) {
Receive(&grad);
aggregated_grad += grad;
}
w_i -= eta(t) * aggregated_grad;
}
0x07 �ܽ�
-
PostOffice:һ������ģʽ��ȫ�ֹ�����,ÿһ�� node (ÿ�� Node ����ʹ�� hostname + port ��Ψһ��ʶ)���������ھ���һ��PostOffice,ֱ�Ӵ������������֪��,PostOffice�����ʾ�;
-
Van:ͨ��ģ��,�����������ڵ������ͨ�ź�Message��ʵ���շ�������PostOffice����һ��Van��Ա,ֱ�Ӵ������������֪��,Van����С�Ƴ�,�����ṩ���ŵĹ���;
-
SimpleApp:KVServer��KVWorker�ĸ���,���ṩ�˼�Request, Wait, Response,Process����;KVServer��KVWorker�ֱ�����Լ���ʹ����д����Щ����;
-
Customer:ÿ��SimpleApp�������һ��Customer��ij�Ա,��Customer��Ҫ��PostOffice����ע��,������Ҫ����:
- ��Ϊһ�����ͷ�,������SimpleApp���ͳ�ȥ����Ϣ�Ļظ����;
- ��Ϊ���շ�,ά��һ��Node����Ϣ����,Ϊ��Node������Ϣ;
Customer �����־Ϳ���֪��,���ʾֵĿͻ�,���� SimpleApp ���ʾֵĴ���������Ϊ��Ҫ worker,server ��Ҫ���о���Ϊ�㷨��,���� worker,server ������������ص��շ���Ϣ���ܶ��ܽ�/ת�Ƶ� Customer ֮�С�
�����������ͼ��
+--------------------------+
| Van |
| |
DataMessage +-----------> Receiving |
| 1 + | +---------------------------+
| | | | Postoffice |
| | 2 | | |
| v | GetCustomer | |
| ProcessDataMsg <------------------> unordered_map customers_|
| + | 3 | |
| | | +---------------------------+
+--------------------------+
|
|
| 4
|
+-------------------------+
| Customer | |
| | |
| v |
| Accept |
| + |
| | |
| | 5 |
| v |
| recv_queue_ | +-----------------+
| + | |KVWorker |
| | 6 | +--------> | |
| | | | 8 | Process |
| v | | +-----------------+
| Receiving | |
| + | |
| | 7 | |
| | | | +-----------------+
| v | | |KVServer |
| recv_handle_+---------+--------> | |
| | 8 | Process |
+-------------------------+ +-----------------+
0xEE ������Ϣ
��������������ͼ�����˼���������
�Ź����˺�:������˼��
������뼰ʱ�õ�����д���µ���Ϣ����,�����뿴�������Ƽ��ļ�������,�����ע��
 ****
****
0xFF �ο�
https://www.cs.cmu.edu/~muli/file/parameter_server_osdi14.pdf
sona:Spark on Angel���ģ�ֲ�ʽ����ѧϰƽ̨����
����Parameter Server�Ŀ���չ�ֲ�ʽ����ѧϰ�ܹ�
Mu Li. Scaling Distributed Machine Learning with the Parameter Server.
CMU. http://parameterserver.org/
Joseph E.Gonzalez. Emerging Systems For Large-scale Machine Learning.
���ֲ�ʽ���㡿MapReduce�������-Parameter Server
Parameter Server for Distributed Machine Learning
PS-Lite Documents
ps-liteԴ������
http://blog.csdn.net/stdcoutzyx/article/details/51241868
http://blog.csdn.net/cyh_24/article/details/50545780
https://www.zybuluo.com/Dounm/note/529299
http://blog.csdn.net/KangRoger/article/details/73307685
http://www.cnblogs.com/heguanyou/p/7868596.html
MXNet֮ps-lite��parameter serverԭ��
ps-liteѧЩϵ��֮һ ----- mac��װps-lite
��Tech1�����IJ���������:ps-lite����
���ŷֲ�ʽ����ѧϰ�����ڲ��������������ع�ʵ��ԭ��
https://www.zhihu.com/topic/20175752/top-answers
Large Scale Machine Learning�CAn Engineering Perspective�CĿ¼
ps-liteѧЩϵ��֮3 �� ps-lite�ļ��(1. Overview)
https://www.zhihu.com/topic/20175752/top-answers
https://blog.csdn.net/zkwdn/article/details/53840091
https://www.zhihu.com/topic/20175752/top-answers
https://blog.csdn.net/zkwdn/article/details/53840091