һ��Q-learning
ǿ��ѧϰ��һ��episode:
ǿ��ѧϰ������Ŀ��:���Ҵ��� s t s_t st?״̬,��Ӧ�ò�ȡ�ӳ�Զ������õĶ��� a t a_t at?
���ʵ�����Ŀ��?��� s t s_t st??״̬��,ÿ����ѡ��������������֪��,��ֻ��Ҫѡ��߷ֵĶ���;��ʵ����������δ֪��,����Ҫ�������й��ơ�
�������ֵĶ���
�Ӷ�̬�滮�ĽǶ�����,���ij���������Ե���ʤ����״̬,��ô��������͵÷����;���ij��������Ȼ����ֱ��ʤ��,�����Լ�ӵ���������ȡʤ��״̬,��ô����������ǵ�ǰ��ѡ�����е÷���ߵġ���ͼ,��ɫ��ͨ��������ͨ����
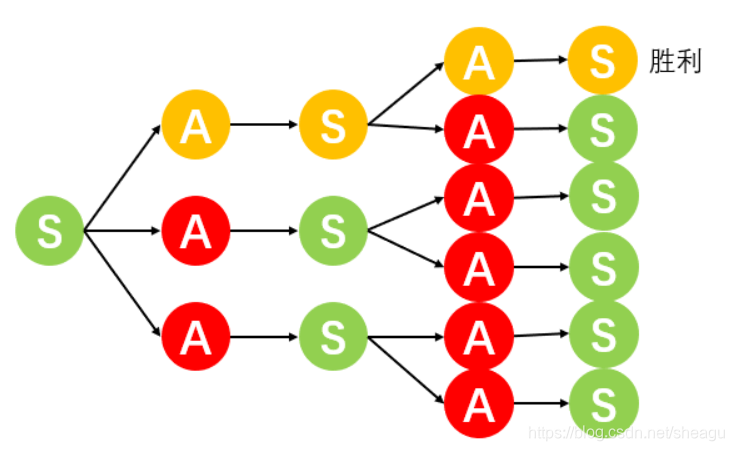
���,����һ�������ĺû�Ҫ�����ij�Զ���档��κ�����Զ������?����ÿ��
(
s
t
,
a
t
)
(s_t,a_t)
(st?,at?)���,������һ������
r
t
r_t
rt?,��ôij��
(
s
t
,
a
t
)
(s_t,a_t)
(st?,at?)?��ϵĻر�����Ϊ:
U
t
=
r
t
+
��
r
t
+
1
+
��
2
r
t
+
2
+
.
.
.
=
��
i
=
t
��
��
i
?
t
r
i
???
(
1
)
U_t=r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+...=\sum_{i=t}^\infty\gamma^{i-t}r_i\ \ \ (1)
Ut?=rt?+��rt+1?+��2rt+2?+...=i=t����?��i?tri????(1)
���Dz�ȷ����:ÿ��
(
s
t
,
a
t
)
(s_t,a_t)
(st?,at?)����һ��
s
t
s_t
st?֮����һ��ת�Ƹ��ʾ���,������һһ��Ӧ��,����,��
a
t
a_t
at?�ļ�ֵ��������ֱ����
U
t
U_t
Ut?,Ҫ������������������ֵ��������Ϊ:
Q
��
(
s
t
,
a
t
)
=
E
[
U
t
�O
s
t
,
a
t
,
��
]
=
E
[
��
i
=
t
��
��
i
?
t
r
i
�O
s
t
,
a
t
,
��
]
???
(
2
)
Q_\pi(s_t,a_t)=E[U_t|s_t,a_t,\pi]=E[\sum_{i=t}^\infty\gamma^{i-t}r_i|s_t,a_t,\pi]\ \ \ (2)
Q��?(st?,at?)=E[Ut?�Ost?,at?,��]=E[i=t����?��i?tri?�Ost?,at?,��]???(2)
����Ҫ���ľ��Ƕ����
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)????���бƽ�����ô�ƽ���?
��
U
t
U_t
Ut?,�������:
U
t
=
��
i
=
t
��
��
i
?
t
r
i
=
r
t
+
��
(
��
i
=
t
+
1
��
��
i
?
t
?
1
r
i
)
=
r
t
+
��
U
t
+
1
???
(
3
)
U_t=\sum_{i=t}^\infty\gamma^{i-t}r_i =r_t+\gamma(\sum_{i=t+1}^\infty\gamma^{i-t-1}r_i) =r_t+\gamma U_{t+1}\ \ \ (3)
Ut?=i=t����?��i?tri?=rt?+��(i=t+1����?��i?t?1ri?)=rt?+��Ut+1????(3)
���
Q
��
(
s
t
,
a
t
)
=
E
[
r
t
+
��
U
t
+
1
�O
s
t
,
a
t
,
��
]
???
(
4
)
Q_\pi(s_t,a_t)=E[r_t+\gamma U_{t+1}|s_t,a_t,\pi]\ \ \ (4)
Q��?(st?,at?)=E[rt?+��Ut+1?�Ost?,at?,��]???(4)
��������
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)??���ƽ�
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)?:??
Q
��
(
s
t
,
a
t
,
w
t
)
��
Q
��
(
s
t
,
a
t
)
???
(
5
)
Q_\pi(s_t,a_t,w_t)\approx Q_\pi(s_t,a_t)\ \ \ (5)
Q��?(st?,at?,wt?)��Q��?(st?,at?)???(5)
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)�ij�ֵ���������,ͨ��������������Ȩ�ز���,��ʹ�����ϱƽ���ѵ����ʱ��,����,��
s
t
s_t
st???״̬,���ָ��ÿ��
a
t
a_t
at???�Ķ�����ֵ����
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)??,Ȼ��ѡ��Ŀǰ��õ�
a
t
a_t
at???(��Ȼ��Ϲѡ)����һ��,����
s
t
+
1
s_{t+1}
st+1???,��ʱ���ǵõ���
r
t
r_t
rt???,�������
r
t
r_t
rt??�Ϳ����Ż�(5)��
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)????��:
Q
��
(
s
t
,
a
t
,
w
t
)
=
r
t
+
��
E
[
U
t
+
1
�O
s
t
+
1
,
a
t
+
1
,
��
]
???
(
6
)
Q_\pi(s_t,a_t,w_t)=r_t+\gamma E[U_{t+1}|s_{t+1},a_{t+1},\pi]\ \ \ (6)
Q��?(st?,at?,wt?)=rt?+��E[Ut+1?�Ost+1?,at+1?,��]???(6)
���ʽ��֮��������ôд,����Ϊ�Ѿ�������t+1ʱ��,
r
t
r_t
rt???�Ѿ�֪����,��һ����������ѡ��,
(
s
t
+
1
,
a
t
+
1
)
(s_{t+1},a_{t+1})
(st+1?,at+1?)??Ҳ�ǿ���֪����,δ֪�IJ���ֻ��
U
t
+
1
U_{t+1}
Ut+1???��,��������������������ʽ��
��(6)�õ���
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)??�DZ�(5)��
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)??��ȷ��,���dz���ΪTD target,����ʾ������֪��Ϣ�õ��Ķ�
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)?????��ȷ�Ĺ���ֵ:
y
t
Q
=
Q
��
(
s
t
,
a
t
,
w
t
)
=
r
t
+
��
Q
��
(
s
t
+
1
,
a
t
+
1
,
w
t
)
=
r
t
+
��
max
?
a
Q
��
(
s
t
+
1
,
a
,
w
t
)
???
(
6
)
y_t^Q=Q_\pi(s_t,a_t,w_t)\\ =r_t+\gamma Q_\pi(s_{t+1},a_{t+1},w_t)\\ =r_t+\gamma \max_a Q_\pi(s_{t+1},a,w_t)\ \ \ (6)
ytQ?=Q��?(st?,at?,wt?)=rt?+��Q��?(st+1?,at+1?,wt?)=rt?+��amax?Q��?(st+1?,a,wt?)???(6)
���������
y
t
Q
y_t^Q
ytQ??����֪�Ķ�
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)?����õĹ���,������һʱ�̵Ĺ���ֵ
Q
��
(
s
t
,
a
t
,
w
t
)
Q_\pi(s_t,a_t,w_t)
Q��?(st?,at?,wt?)??���в���,���Ǿ����������������Ż��������������loss����Ϊ:
L
t
=
1
2
(
Q
��
(
s
t
,
a
t
,
w
t
)
?
y
t
Q
)
2
???
(
7
)
L_t=\frac{1}{2}(Q_\pi(s_t,a_t,w_t)-y_t^Q)^2\ \ \ (7)
Lt?=21?(Q��?(st?,at?,wt?)?ytQ?)2???(7)
Ȼ��Բ���w���ݶ��½�:
KaTeX parse error: Undefined control sequence: \grad at position 105: ��i(s_t,a_t,w_t))\?g?r?a?d?_{w_t}Q_\pi(s_t��
��t������,ֱ������һ��episode,��ô��ʱ��
y
t
Q
y_t^Q
ytQ?���Ƕ�
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)��õĹ����ˡ�����û����֮ǰ,
y
t
Q
y_t^Q
ytQ?Ҳ���ڲ����Ż���,���Կ��ܲ���Ҫ����Ҳ�ܵõ��ܾ�ȷ�Ķ�
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)�Ĺ��ơ����Կ϶�����,����һ��episode,��;����������
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)���ᱻ����,�����ڴ�ÿ��״̬��ֻ��ȥ��һ��,������һ��
a
t
a_t
at?,��������������,����ÿ��
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)����Ƭ���,��������episode,�Ϳ���̽�������·��,�õ���ȫ���
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?)ֵ�������Ѿ�������
(
s
t
,
a
t
)
(s_t,a_t)
(st?,at?),�����г�Q-Table��¼���ǵļ�ֵ,�Ա��¸�episode������
s
t
s_t
st?��ʱ��,����ѡ����õ�
a
t
a_t
at?�����¸�episode�Ѿ�֪����һ����
Q
��
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Q��?(st?,at?),������δ֪�Ķ������ܴ������������,����ǡ�̽��-���á���ƽ�⡣
| Q-Table | a1 | a2 |
|---|---|---|
| s1 | q(s1,a1) | q(s1,a2) |
| s2 | q(s2,a1) | q(s2,a2) |
| s3 | q(s3,a1) | q(s3,a2) |
����Deep Q Networks
DQN�� a multi-layered neural network,��Q-learning�Ļ�����������target network��experience replay��
target network���������缸����ͬ,ֻ��������������ʱ���µ�,����ÿ���Ӳ�����һ�β����֡�DQN�õ�target��ʾ:
y
t
D
Q
N
=
r
t
+
��
max
?
a
Q
��
(
s
t
+
1
,
a
,
w
t
?
)
???
(
9
)
y_t^{DQN}=r_t+\gamma \max_a Q_\pi(s_{t+1},a,w_t^-)\ \ \ (9)
ytDQN?=rt?+��amax?Q��?(st+1?,a,wt??)???(9)
��
y
t
Q
y_t^Q
ytQ?������ֻ�в���
w
t
?
w_t^-
wt??��ͬ��
experience replay��ָ,�۲��״̬ת�ƻᱻ�洢һ��ʱ��,��������洢���о��Ȳ���,�Ը������硣
target network��experience replay������������㷨�����ܡ�
����double Q-learning
��Q-learning��DQN��,��ѡ����һ������ʱʹ�õ����ۺ����IJ������롱�������б�ѡ����ʱʹ�õ����ۺ����IJ���������ͬ��,Ҳ����˵,�Ҹ������еĶԱ�ѡ�����Ĵ��ֵ,ѡ��һ����õ�,Ȼ������������ǰ�Ķ�����ֵ,��Ȼ�õ�һ���ܸߵķ��������������ڵ�������,�ҿ��ܻ�߹�ij�������ķ���,����һ���߹���,����ѡ������ʱ��ͻ�ѡ��,�´δ�ֵ�ʱ����Ȼ�߹�,����һ�����֡��߹����ͻ�Ӱ���Һ����״̬�켣��
Ϊ�˱�������Ӱ��,�������ײ���,�ѡ���֡��͡�ѡ�������Ĺ��̷ֿ���
Ϊ�˱��ڶԱ�,�Ȱ�Q-learning��(6)д��:
y
t
Q
=
r
t
+
��
max
?
a
Q
��
(
s
t
+
1
,
a
,
w
t
)
=
r
t
+
��
Q
��
(
s
t
+
1
,
max
?
a
Q
��
(
s
t
+
1
,
a
,
w
t
)
,
w
t
)
???
(
10
)
y_t^Q=r_t+\gamma \max_a Q_\pi(s_{t+1},a,w_t)\\ =r_t+\gamma Q_\pi(s_{t+1},\max_a Q_\pi(s_{t+1},a,w_t),w_t)\ \ \ (10)
ytQ?=rt?+��amax?Q��?(st+1?,a,wt?)=rt?+��Q��?(st+1?,amax?Q��?(st+1?,a,wt?),wt?)???(10)
Ҳ����˵,ѡ������ʱ���õ��������
w
t
w_t
wt?,��ѡ�����Ķ����ٴδ�ֵ�ʱ���õ��������
w
t
w_t
wt?��DQN��������,ֻ�����Ǽ���Եظ���
w
t
w_t
wt?��?
��double Q-learning��,target�:
y
t
D
o
u
b
l
e
Q
=
r
t
+
��
Q
��
(
s
t
+
1
,
max
?
a
Q
��
(
s
t
+
1
,
a
,
w
t
)
,
w
t
��
)
y_t^{DoubleQ}=r_t+\gamma Q_\pi(s_{t+1},\max_a Q_\pi(s_{t+1},a,w_t),w_t')
ytDoubleQ?=rt?+��Q��?(st+1?,amax?Q��?(st+1?,a,wt?),wt��?)
Ҳ����˵,ѡ������ʱ���õ��������
w
t
w_t
wt?,�������ߵIJ���;��ѡ�����Ķ����ٴδ�ֵ�ʱ���õ��������
w
t
��
w_t'
wt��?��ÿ�θ��µ�ʱ��,���µ���
w
t
w_t
wt?,��������
w
t
��
w_t'
wt��?,��Ҫ����
w
t
w_t
wt?��
w
t
��
w_t'
wt��?�ĵ�λ��
ѡ������ʱ���õ�������� w t w_t wt?,�������ߵIJ���;��ѡ�����Ķ����ٴδ�ֵ�ʱ���õ�������� w t �� w_t' wt��?��ÿ�θ��µ�ʱ��,���µ��� w t w_t wt?,�������� w t �� w_t' wt��?,��Ҫ���� w t w_t wt?�� w t �� w_t' wt��?�ĵ�λ��
���������:ijѡ���Ŀ��������ί,��һ���ѡ�ִ�ֲ�ѡ��С��ھ�,Ȼ��ڶ�����ί�ٸ������´��,���������Ϊѡ�ֵķ�������¼��������ί��һ��ʱ�佻��һ�Ρ�
�����
[1] ���ǿ��ѧϰ(ȫ)
[2] ��ǿ��ѧϰ��Q-Learning�㷨���
[3] H. Van Hasselt, A. Guez, and D. Silver, ��Deep reinforcement learning with double q-learning,�� in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30, no. 1, 2016.