��������̳�Ϊ��,����̳�Ϊ��,����������,�����¼һ��:
1.���Python�����CUnicodeDecodeError: ��gbk�� codec can��t decode byte 0x80 in position 658: illegal multibyte sequence
ԭ��:���뷽ʽ��һ��
�������:
��open()�������encoding����encoding='utf-8'
file1=open("���������ȡ�ļ���·��","r",encoding='utf-8')2.Error: l.outputs == params.inputs filters= in the [convolutional]-layer doesn't correspond to classes= or mask= in [yolo]-layer
ԭ��:cfg�ļ����ó���,һ����filters����û�и���
�������:
use the filter formula for convolution layer before YOLO layer (classes+5)x3
so the filter not 255 but 18, (1+5)x3
--------------------------------------------------------------------
��yolo(����yolo,һ��������)��������һ��������filter �ij�(classes+5)x3
������classesΪ1 ���ij�filter=18,������:
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
...
...
...
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
...
...
...
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=13.Error in load_data_detection() - OpenCV
ԭ��:�����������������·������
�������:�ŷ����ҵ�ͼƬ��png��ʽ����������jpg,��д��·������һ�¾ͺ��ˡ�
for year, image_set in sets:
if not os.path.exists('myData/labels/'): # �ij��Լ�������myData
os.makedirs('myData/labels/')
image_ids = open('myData/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('myData/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s\myData\JPEGImages\%s.png\n'%(wd, image_id)) #����ط��Ӳ���ǰ��...������Ҫ��ǰ
convert_annotation(year, image_id)
list_file.close()4.CUDA status Error: file: ..\..\src\dark_cuda.c : cuda_make_array() : line: 493 :
������Ҳ��̫�����������ô����
��������ɹ���,���Dz��Ե�ʱ��,���Խ����㿴һ����һƪ����,��û��ϸ��,��Ϊ�Ҹ���cfg�����subdivisions�Ĵ�֮��֮����ܿ�ʼѵ���ˡ�
����:ԭ���ұ�windows��ƭ�ˡ�����
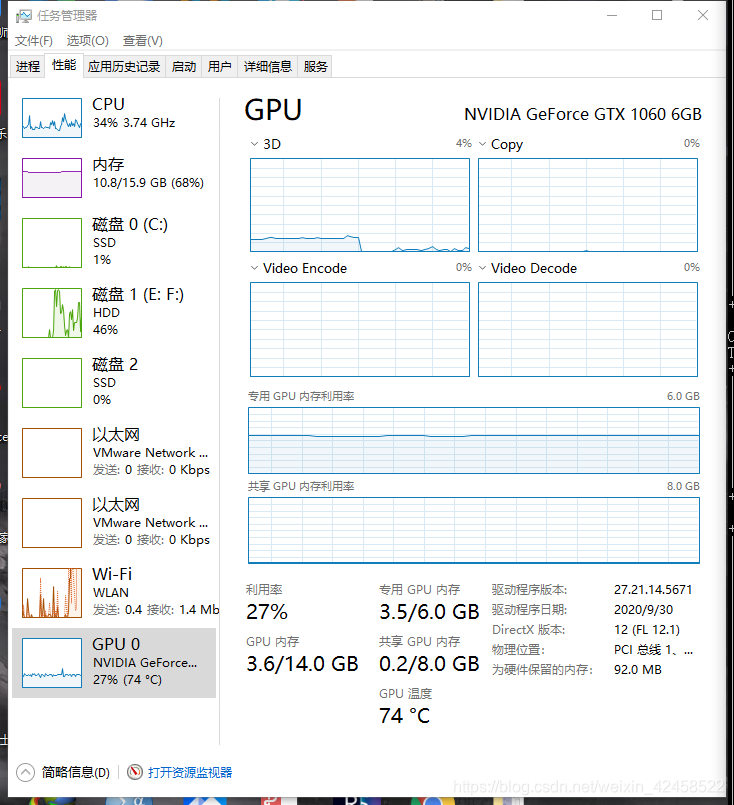
��������������,���ò��Ծ�,����ѵ����ʱ��,GPU֮ռ����8%,�������?�ⲻ����,�Ҿ����úÿ�����ô���������⡣����������Щ˵����makefile�ļ�,������win10ϵͳ��ʹ��VS2019�������������ļ�,������֮ǰ����darknet���̳���,����ɹ��Ϳ����ˡ�
������win10����ж�,Win 10��Ȼ��Bug 10:GPUռ����ԭ������ô���,��ô��ʵ�ʶ�GPU��ѵ����ʱ���������Ƕ�����?
ʹ������nvidia-sim
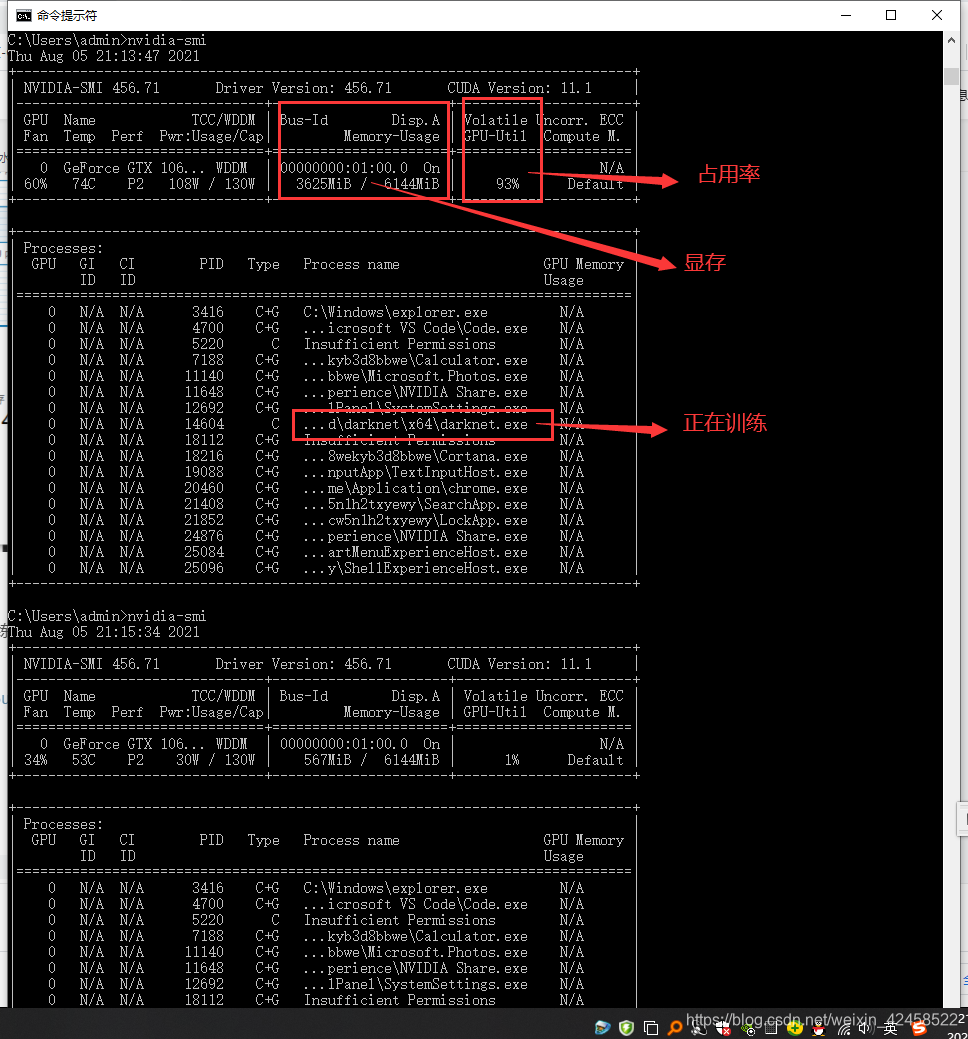
����ôһ˵ȷʵ�dz����� ,��Ҫ��subdivisions�Ĵ�һ�㻺��ѹ��,�����Ҹij���32,���ѵ�������ij���2000��,��Ϊ�ҿ�����˵ѵ������classes����2000��,ѵ����ʱ��Ҳ�������,˵��Ҫ7��Сʱ,�����ʮ�������Ҿ�ѵ�����ˡ�
ϣ���ҵľ���̸֮�ܹ�������Ҫ����~