一.引言
上一篇文章?Tensorflow - 一文搞懂 TF2.x tf.feature_column?讲到了 tensorflow 如何构建特征工程,本文继续反向探索,构造特征工程之前需要处理源数据构造原始样本,下面主要介绍 DataSet 的使用与优化技巧。
二.基础使用
这里以 tf.data.TextLineDataset 生成 DataSet 为例。最基本的处理方法:
1.读取对应文件夹文件
file_names = "./tr"
field_size = 100
dataSet = tf.data.TextLineDataset(file_names).map(
lambda line: decode_line(line)
)
2.指定Map Function 处理得到特征文件?
这里假定原始数据形式为 label + k:v + k:v + k:v ... 的形式,按 sep 分隔符隔开
def decode_line(line):
feat_infos = tf.strings.split([line], 'sep')
label = tf.py_function(get_label, [feat_infos.values[0]], tf.int64)
features = {}
for index in range(1, FieldSize, 1):
feat_name, feat_value = parse_feature(feat_infos.values[index])
features[str(index)] = feat_value
return features, label3.通过 Dataset 生成 Iterator
dataSet = dataSet.repeat(epoch_num)
dataSet = dataSet.batch(batch_size)
iterator = tf.compat.v1.data.make_one_shot_iterator(dataSet)根据训练对应的 batch_size,epoch_num 参数对 Dataset 进行调整,上述为 TF 2.x 版本使用方法,如果使用 1.X 版本,则对应生成迭代器方法为:
iterator = dataSet.make_initializable_iterator()三.常用方法与优化
1.filter
处理原始数据时过滤脏数据,验证数据的逻辑加入到 filter_line 方法即可。
dataSet = tf.data.TextLineDataset(file_names).filter(
lambda line: filter_line(line)).map(
lambda line: decode_line(line))2.repeat / batch
repeat 和 batch 一般是同时使用,二者和模型训练的 epoch 次数与 batch_size 相关,repeat epoch次保证当前训练样本在每个训练 epoch 中存在,batch 则保证原始数据能够按照 batch_size 送进模型侧。?
dataSet = dataSet.repeat(epoch_num)
dataSet = dataSet.batch(batch_size)
Tips:?
假设 sample_num?条样本,repeat?epoch_num 次,批量大小为 batch_size,则可以从迭代器调用item 次。
iter_num = math.ceil(sample_num * epoch_num / batch_size)
假设 sample_num = 10, epoch = 1, batch_size = 3,则可以调用生成 4 个batch,前三个 batch 都包含3条样本,最后一个样本包含1个样本。

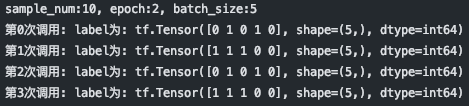
sample_num=10,epoch=2,batch_size=5 该情况下可以整除:
3.加载压缩格式样本
TextLineDataset 函数支持读取压缩格式样本,例如:?ZLIB,GZIP。常见于 Spark (大数据) +? Python (深度学习) 的架构。
dataset = tf.data.TextLineDataset(file_names, compression_type="GZIP")4.并行加载
大规模开发场景下可以通过加入 num_parallel_calls 增加读取数据的并行度,提高吞吐效率。本机的话 num_parallel_cells 可以设置为本机 core 的数量, 集群则根据对应申请的资源进行配置。
dataset = tf.data.TextLineDataset(file_names).map(map_func, num_parallel_calls=3)5.prefetch
prefetch 预加载数据,可以把处理数据+训练数据的串行关系改变为处理数据且训练数据的并行关系,提高处理器的利用率,进而缩短任务执行时间。一般而言 prefetch(n) n 为 batch_size 或者 batch_size 的倍数。
dataset = dataset.filter(...)
.map(...)
.prefetch(batch_size)6.shuffle
打散数据,改变原有数据的次序,主要针对非时序的数据。为了保证元素在 epoch 内出现的唯一性,一般采用先 shuffle 后 repeat 的方式,shuffle(n) 的 n 一般选择为 batch_size,引入 shuffle 会影响整体的性能。
dataset = dataset.filter(...)
.map(...)
.prefetch(batch_size)
.shuffle(buffer_size=batch_size)7.interleave
interleave(
map_func, cycle_length=None, block_length=None, num_parallel_calls=None,
deterministic=None
)interleave 参考了?官方API,其字面意思为内部交织,主要作用用于将多个 FIleName 对应的文件或者多个 TF_record 的内容结合在一起,类似于一个文件夹只有类型 A 的样本,一个文件夹只有类型 B 的样本,如果想训练时 DataSet 中又有A又有B,则可以 interleave,执行的过程是 :?
A.从当点 Dataset 中取出 cycle_length 个 element 并针对 element 执行 map_func
B.上一步得到 cycle_length 个 Dataset ,从这些 Dataset 取数据,每个 DataSet 取?block_length 个
C.新生成的 Dataset 中按 block_lenght 取完后则从原始 Dataset 继续拿 cycle_length 个 element,然后 map_func,然后取?block_length
dataset = tf.data.Dataset.range(1, 6) # ==> [ 1, 2, 3, 4, 5 ]
# NOTE: New lines indicate "block" boundaries.
dataset = dataset.interleave(
lambda x: tf.data.Dataset.from_tensors(x).repeat(6),
cycle_length=2, block_length=4)
print(list(dataset.as_numpy_iterator()))上例子中 cycle_lenght 为2,block_length 为4,每次取2个元素,生成 Dataset 后取4个元素
A. 取两个元素 1,2,执行map_func,本例为 repeat(6),所以得到两个 Dataset,分别有6个1,6个2
B.从每个新生成的 Dataset (6个1,6个2)取block_length(4)个数据,得到 [1,1,1,1],[2,2,2,2]
C.继续取 [1,1],[2,2] 6个取完不够了,再拿两个新元素3,4,生成6个3,6个4,循环往复
[1, 1, 1, 1,
2, 2, 2, 2,
1, 1,
2, 2,
3, 3, 3, 3,
4, 4, 4, 4,
3, 3,
4, 4,
5, 5, 5, 5,
5, 5]Tips:
(Optional.) If specified, the implementation creates a threadpool, which is
used to fetch inputs from cycle elements asynchronously and in parallel.
The default behavior is to fetch inputs from cycle elements synchronously
with no parallelism. If the value tf.data.AUTOTUNE is used,
then the number of parallel calls is set dynamically based on available CPU.interleave 过程中也可以加入?num_parallel_calls 参数,增加任务执行的并行度。
4.总结
tf.dataset 的常用方法大致就这些,大规模工业场景下多为 Gzip + filter + map + prefetch + repeat + batch + shuffle 的顺序,上述方法可以基于?Esitimator 生成 input_function 供 model_function 调用或者基于 Keras 生成训练 Dataset 再结合特征工程,直接调用 fit(dataset) 的方法,都非常的好用。除此之外,Dataset 也支持通过 TF-record 生成,后续有空继续整理~