1:БЈУћЕижЗ
https://tianchi.aliyun.com/competition/entrance/231576/score
2:ХХУћЗжЪ§?
3:ФЃаЭдДТы
?ЗЯЛАВЛЖрЫЕ,жБНгЩЯдДТы
import gc
import pandas as pd
# гУЛЇааЮЊ,ЪЙгУformat1НјааМгди
# МгдиШЋСПбљБО
user_log = pd.read_csv('./data_format1/user_log_format1.csv', dtype={'time_stamp':'str'})
user_info = pd.read_csv('./data_format1/user_info_format1.csv')
train_data1 = pd.read_csv('./data_format1/train_format1.csv')
submission = pd.read_csv('./data_format1/test_format1.csv')
train_data = pd.read_csv('./data_format2/train_format2.csv')
train_data1['origin'] = 'train'
submission['origin'] = 'test'
matrix = pd.concat([train_data1, submission], ignore_index=True, sort=False)
#print(matrix)
matrix.drop(['prob'], axis=1, inplace=True)
# СЌНгuser_infoБэ,ЭЈЙ§user_idЙиСЊ
matrix = matrix.merge(user_info, on='user_id', how='left')
# ЪЙгУmerchant_id(дСаУћseller_id)
user_log.rename(columns={'seller_id':'merchant_id'}, inplace=True)
# ИёЪНЛЏ
user_log['user_id'] = user_log['user_id'].astype('int32')
user_log['merchant_id'] = user_log['merchant_id'].astype('int32')
user_log['item_id'] = user_log['item_id'].astype('int32')
user_log['cat_id'] = user_log['cat_id'].astype('int32')
user_log['brand_id'].fillna(0, inplace=True)
user_log['brand_id'] = user_log['brand_id'].astype('int32')
user_log['time_stamp'] = pd.to_datetime(user_log['time_stamp'], format='%H%M')
# 1 for <18; 2 for [18,24]; 3 for [25,29]; 4 for [30,34]; 5 for [35,39]; 6 for [40,49]; 7 and 8 for >= 50; 0 and NULL for unknown
matrix['age_range'].fillna(0, inplace=True)
# 0:female, 1:male, 2:unknown
matrix['gender'].fillna(2, inplace=True)
matrix['age_range'] = matrix['age_range'].astype('int8')
matrix['gender'] = matrix['gender'].astype('int8')
matrix['label'] = matrix['label'].astype('str')
matrix['user_id'] = matrix['user_id'].astype('int32')
matrix['merchant_id'] = matrix['merchant_id'].astype('int32')
del user_info, train_data1
gc.collect()
print(matrix)
# UserЬиеїДІРэ
groups = user_log.groupby(['user_id'])
# гУЛЇНЛЛЅааЮЊЪ§СП u1
temp = groups.size().reset_index().rename(columns={0:'u1'})
matrix = matrix.merge(temp, on='user_id', how='left')
# ЪЙгУagg ЛљгкСаЕФОлКЯВйзї,ЭГМЦЮЈвЛжЕЕФИіЪ§ item_id, cat_id, merchant_id, brand_id
#temp = groups['item_id', 'cat_id', 'merchant_id', 'brand_id'].nunique().reset_index().rename(columns={'item_id':'u2', 'cat_id':'u3', 'merchant_id':'u4', 'brand_id':'u5'})
# ЖдгкУПИіuser_id ВЛжиИДЕФitem_idЕФЪ§СП => u2
temp = groups['item_id'].agg([('u2', 'nunique')]).reset_index()
matrix = matrix.merge(temp, on='user_id', how='left')
# ЖдгкУПИіuser_id ВЛжиИДЕФcat_idЕФЪ§СП => u3
temp = groups['cat_id'].agg([('u3', 'nunique')]).reset_index()
matrix = matrix.merge(temp, on='user_id', how='left')
temp = groups['merchant_id'].agg([('u4', 'nunique')]).reset_index()
matrix = matrix.merge(temp, on='user_id', how='left')
temp = groups['brand_id'].agg([('u5', 'nunique')]).reset_index()
matrix = matrix.merge(temp, on='user_id', how='left')
# ЪБМфМфИєЬиеї u6 АДееаЁЪБ
# ЖдгкУПИіuser_id МЦЫуtime_stampЕФзюаЁЪБМф => F_time, зюДѓЪБМфmax => L_time
temp = groups['time_stamp'].agg([('F_time', 'min'), ('L_time', 'max')]).reset_index()
temp['u6'] = (temp['L_time'] - temp['F_time']).dt.seconds/3600
matrix = matrix.merge(temp[['user_id', 'u6']], on='user_id', how='left')
# ЭГМЦВйзїРраЭЮЊ0,1,2,3ЕФИіЪ§
temp = groups['action_type'].value_counts().unstack().reset_index().rename(columns={0:'u7', 1:'u8', 2:'u9', 3:'u10'})
matrix = matrix.merge(temp, on='user_id', how='left')
#print(matrix)
# ЩЬМвЬиеїДІРэ
groups = user_log.groupby(['merchant_id'])
# ЩЬМвБЛНЛЛЅааЮЊЪ§СП m1
temp = groups.size().reset_index().rename(columns={0:'m1'})
matrix = matrix.merge(temp, on='merchant_id', how='left')
# ЭГМЦЩЬМвБЛНЛЛЅЕФuser_id, item_id, cat_id, brand_id ЮЈвЛжЕ
temp = groups['user_id', 'item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(columns={'user_id':'m2', 'item_id':'m3', 'cat_id':'m4', 'brand_id':'m5'})
matrix = matrix.merge(temp, on='merchant_id', how='left')
# ЭГМЦЩЬМвБЛНЛЛЅЕФaction_type ЮЈвЛжЕ
temp = groups['action_type'].value_counts().unstack().reset_index().rename(columns={0:'m6', 1:'m7', 2:'m8', 3:'m9'})
matrix = matrix.merge(temp, on='merchant_id', how='left')
# АДееmerchant_id ЭГМЦЫцЛњИКВЩбљЕФИіЪ§
temp = train_data[train_data['label']==-1].groupby(['merchant_id']).size().reset_index().rename(columns={0:'m10'})
matrix = matrix.merge(temp, on='merchant_id', how='left')
#print(matrix)
# АДееuser_id, merchant_idЗжзщ
groups = user_log.groupby(['user_id', 'merchant_id'])
temp = groups.size().reset_index().rename(columns={0:'um1'}) #ЭГМЦааЮЊИіЪ§
matrix = matrix.merge(temp, on=['user_id', 'merchant_id'], how='left')
temp = groups['item_id', 'cat_id', 'brand_id'].nunique().reset_index().rename(columns={'item_id':'um2', 'cat_id':'um3', 'brand_id':'um4'}) #ЭГМЦitem_id, cat_id, brand_idЮЈвЛИіЪ§
matrix = matrix.merge(temp, on=['user_id', 'merchant_id'], how='left')
temp = groups['action_type'].value_counts().unstack().reset_index().rename(columns={0:'um5', 1:'um6', 2:'um7', 3:'um8'})#ЭГМЦВЛЭЌaction_typeЮЈвЛИіЪ§
matrix = matrix.merge(temp, on=['user_id', 'merchant_id'], how='left')
temp = groups['time_stamp'].agg([('first', 'min'), ('last', 'max')]).reset_index()
temp['um9'] = (temp['last'] - temp['first']).dt.seconds/3600
temp.drop(['first', 'last'], axis=1, inplace=True)
matrix = matrix.merge(temp, on=['user_id', 'merchant_id'], how='left') #ЭГМЦЪБМфМфИє
#print(matrix)
#гУЛЇЙКТђЕуЛїБШ
matrix['r1'] = matrix['u9']/matrix['u7']
#ЩЬМвЙКТђЕуЛїБШ
matrix['r2'] = matrix['m8']/matrix['m6']
#ВЛЭЌгУЛЇВЛЭЌЩЬМвЙКТђЕуЛїБШ
matrix['r3'] = matrix['um7']/matrix['um5']
matrix.fillna(0, inplace=True)
# # аоИФage_rangeзжЖЮУћГЦЮЊ age_0, age_1, age_2... age_8
temp = pd.get_dummies(matrix['age_range'], prefix='age')
matrix = pd.concat([matrix, temp], axis=1)
temp = pd.get_dummies(matrix['gender'], prefix='g')
matrix = pd.concat([matrix, temp], axis=1)
matrix.drop(['age_range', 'gender'], axis=1, inplace=True)
print(matrix)
# ЗжИюбЕСЗЪ§ОнКЭВтЪдЪ§Он
train_data = matrix[matrix['origin'] == 'train'].drop(['origin'], axis=1)
test_data = matrix[matrix['origin'] == 'test'].drop(['label', 'origin'], axis=1)
train_X, train_y = train_data.drop(['label'], axis=1), train_data['label']
del temp, matrix
gc.collect()
# ЪЙгУЛњЦїбЇЯАЙЄОп
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LinearRegression
from sklearn.metrics import classification_report
import xgboost as xgb
# НЋбЕСЗМЏНјааЧаЗж,20%гУгкбщжЄ
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_y, test_size=.2)
# ЪЙгУXGBoost
model = xgb.XGBClassifier(
max_depth=8,
n_estimators=2000,
min_child_weight=300,
colsample_bytree=0.8,
subsample=0.8,
eta=0.3,
seed=42
)
model.fit(
X_train, y_train,
eval_metric='auc', eval_set=[(X_train, y_train), (X_valid, y_valid)],
verbose=True,
#дчЭЃЗЈ,ШчЙћaucдк10epochУЛгаНјВНОЭstop
early_stopping_rounds=30
)
model.fit(X_train, y_train)
prob = model.predict_proba(test_data)
submission['prob'] = pd.Series(prob[:,1])
submission.drop(['origin'], axis=1, inplace=True)
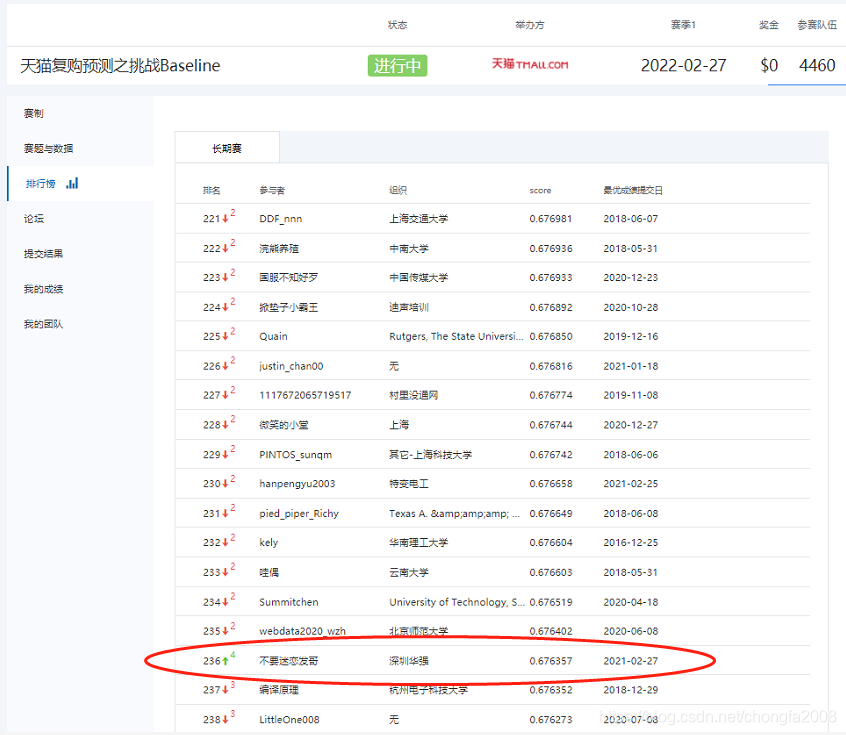
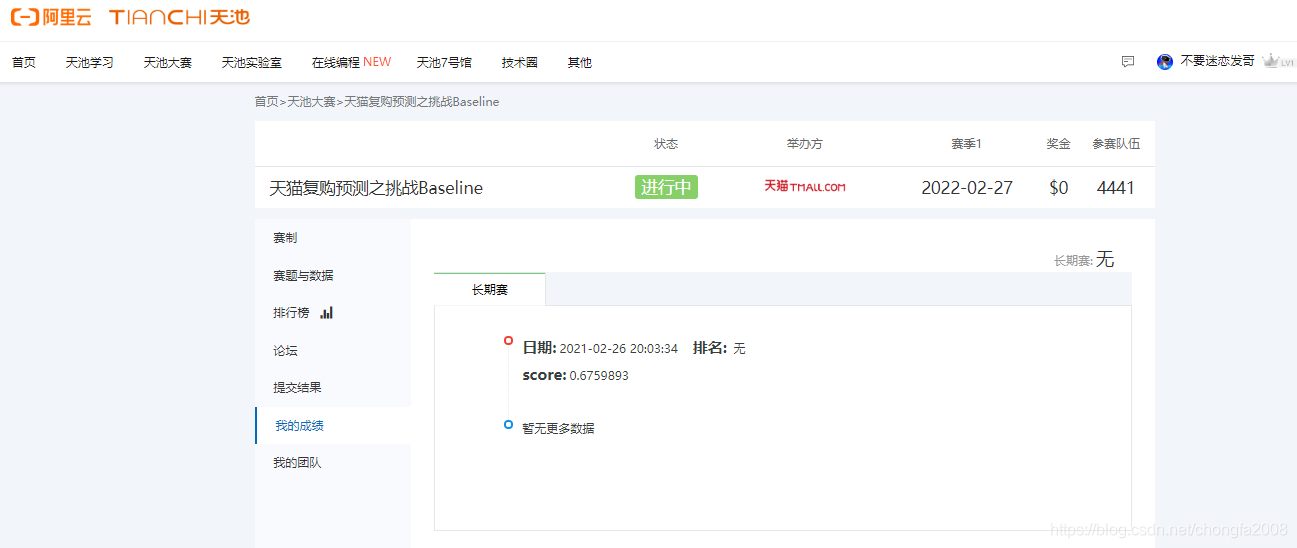
submission.to_csv('BaseLine_0.676357.csv', index=False)?4:ЬсЗжвЊСь
? ? ? ?гУЛЇЬиеїДІРэ
????????ЪБМфМфИєЬиеї
????????ЩЬМвЬиеїДІРэ
? ? ? ? ЙКТђЕуЛїБШ
5:ЯрЙижЊЪЖВЙГф
1:DINФЃаЭ

2:DIENФЃаЭ

?3:DSINФЃаЭ

??