
 ?
?
1、构建特征工程的原则(保留有用信息,摒弃冗余信息)

2、 推荐系统中的常用特征
?1). 用户行为数据(显性反馈行为、隐性反馈行为)(人-物)

?2). 用户关系数据(人-人)

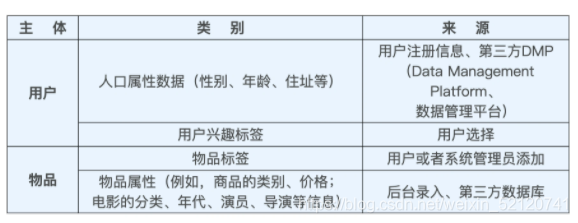
3). 属性、标签类数据?(Multi-hot 编码、embedding)
属性和标签的主体可以是用户,也可以是物品
4). 内容类数据(CV、NLP、Multi-hot 编码、embedding)
????????相比标签类特征,内容类数据往往是大段的描述型文字、图片,甚至视频。?需要通过自然语言处理、计算机视觉等技术手段提取关键内容特征,再输入推荐系统
5). 场景信息(上下文信息)
????????最常用的上下文信息是“时间”和通过 GPS、IP 地址获得的“地点”信息,还包括“当前所处推荐页面”“季节”“月份”“是否节假日”“天气”“空气质量”“社会大事件”等等。
3、Spark如何处理特征(海量、数值型特征)
最关键的过程是我们要理解哪些是可以纯并行处理的部分,哪些是必须 shuffle(混洗)和 reduce 的部分。shuffle 操作是 spark 程序应该尽量避免的。
Q:经典的特征处理方法有什么?Spark 是如何实现这些特征处理方法的?
类别型特征:One-hot 编码(也被称为独热编码)
数值型特征:归一化和分桶,主要考虑特征的尺度(归一化至[0,1])和分布(分桶)
所谓“分桶(Bucketing)”,就是将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶 ID 作为特征值。
特征处理并没有标准答案,实践中多尝试。
4、Embedding--Word2vec
Embedding 就是用一个数值向量“表示”一个对象(Object)的方法
一个物品能被向量表示,是因为这个向量跟其他物品向量之间的距离反映了这些物品的相似性。更进一步来说,两个向量间的距离向量甚至能够反映它们之间的关系。
Embedding 技术对深度学习推荐系统的重要性:
1)Embedding 是处理稀疏特征的利器(稀疏高维特征向量 -> 稠密低维特征向量)
2)Embedding 可以融合大量有价值信息,本身就是极其重要的特征向量(几乎可以引入任何信息进行编码,表达能力更强)
Word2vec
Word2vec 是“word to vector”的简称,它是一个生成对“词”的向量表达的模型。