数据的特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取. sklearn.feature_extraction提供了特征提取的很多方法
分类特征变量提取
我们将城市和环境作为字典数据,来进行特征的提取。
sklearn.feature_extraction.DictVectorizer(sparse = True)
将映射列表转换为Numpy数组或scipy.sparse矩阵
- sparse 是否转换为scipy.sparse矩阵表示,默认开启
方法
fit_transform(X,y)
应用并转化映射列表X,y为目标类型
inverse_transform(X[, dict_type])
将Numpy数组或scipy.sparse矩阵转换为映射列表
from sklearn.feature_extraction import DictVectorizer
onehot = DictVectorizer() # 如果结果不用toarray,请开启sparse=False
instances = [{'city': '北京','temperature':100},{'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
X = onehot.fit_transform(instances).toarray()
print(onehot.inverse_transform(X))
文本特征提取(只限于英文)
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1)文档的中词的出现
数值为1表示词表中的这个词出现,为0表示未出现
sklearn.feature_extraction.text.CountVectorizer()
将文本文档的集合转换为计数矩阵(scipy.sparse matrices)
方法
fit_transform(raw_documents,y)
学习词汇词典并返回词汇文档矩阵
from sklearn.feature_extraction.text import CountVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = CountVectorizer()
print(vectorizer.fit_transform(content).toarray())
需要toarray()方法转变为numpy的数组形式
方法
fit_transform(raw_documents,y)
学习词汇和idf,返回术语文档矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
数据的特征预处理
归一化
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。 例如:一个人的身高和体重两个特征,假如体重50kg,身高175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,k-临近算法会有这个距离公式。
min-max方法
常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换的函数为:
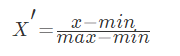
其中min是样本中最小值,max是样本中最大值,注意在数据流场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
def mm():
"""
归一化处理
:return: None
"""
mm = MinMaxScaler(feature_range=(2, 3))
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
标准化
常用的方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:
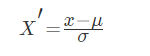
其中\muμ是样本的均值,\sigmaσ是样本的标准差,它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景
def stand():
"""
标准化缩放
:return: None
"""
std = StandardScaler()
data = std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]])
print(data)
return None
缺失值
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN或其他占位符。然而,这样的数据集与scikit的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
填充缺失值 使用sklearn.preprocessing中的Imputer(或者sklearn.impute中的Simpleimputer,因为sklearn版本不同)类进行数据的填充
def im():
"""
缺失值处理
:return: None
"""
im = SimpleImputer(missing_values=np.nan, strategy='mean')
data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])
print(data)
return None