YOLOv3: An Incremental Improvement

文章目录
参考
Introduction
-
YOLOv3这个模型真的可谓是‘家喻户晓’,我当年入坑就是用的这个模型~现在回过头来看这个模型,又有些理解,回到模型本身,YOLOv3大致结构可以用下图表示,这是一张非常经典的图:
-

-
主要有两点:
- backbone部分用的是DarkNet53,引入了ResNet的残差结构
- 模型整体采用FPN思想,卷积三个阶段的输出进行检测(feature map的大小深度不同,因此可以检测到不同尺寸的obj)
The Deal
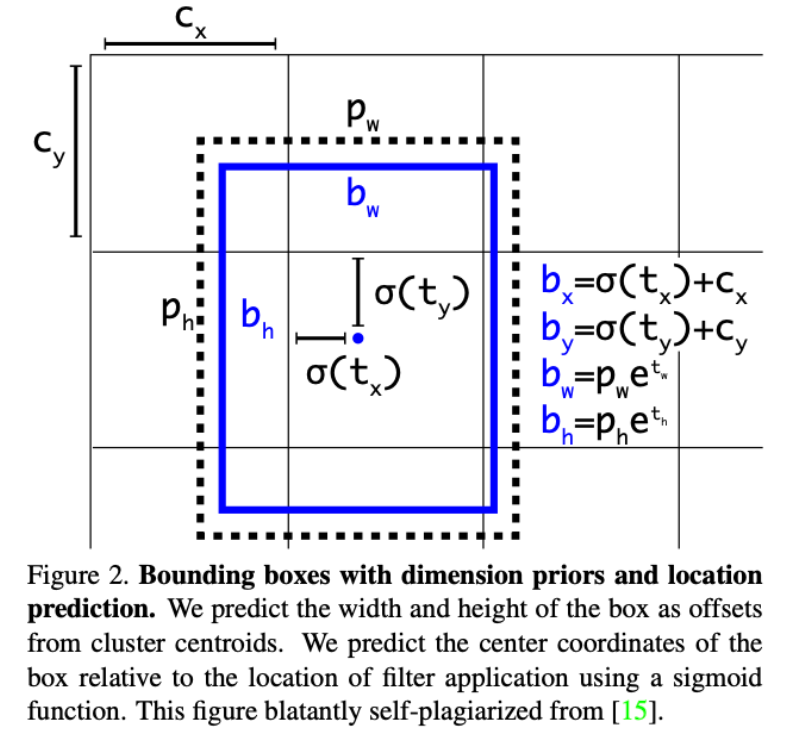
Bounding Box Prediction
-
这部分沿用了YOLOv2部分,这里就放张图,同时可以参考我的上一篇:YOLO9000: Better, Faster, Stronger
-
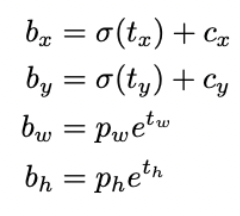
Class Prediction
- 这里作者提出一个问题:每个框使用多标签分类预测边界框可能包含的类。
- 因此此时使用softmax就不合适(因为它会假设每个框正好有一类,但事实通常并非如此(重叠目标,或者大框包小框))
- we simply use independent logistic classifiers,作者用独立的逻辑回归分类器替代,loss用的交叉熵
Predictions Across Scales
- 上面提到YOLO引入FPN,在卷积的三个阶段都引出一个feature map用来检测,因此有三个scale(尺度)
- 而每个scale都tensor的长度为: N × N × [ 3 ? ( 4 + 1 + 80 ) ] N × N × [3 ? (4 + 1 + 80)] N×N×[3?(4+1+80)],其中4=box参数,1=是否有对象,80=类别个数
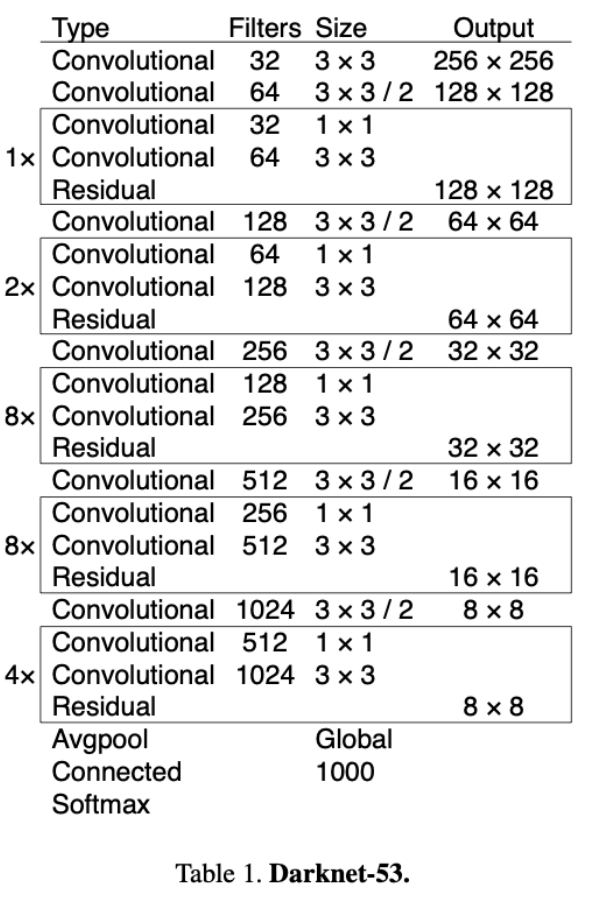
Feature Extractor(DarkNet53)
-
它长这样:
-
其实就是一堆卷积池化拼成的类,不同是每个模块引入的残差机制用于防止模型退化
-
-
Things We Tried That Didn’t Work
-
作者认为没啥用的trick
-
Anchor box x, y offset predictions
- 作者认为 b x = σ ( t x ) + c x b y = σ ( t y ) + c y b_x= \sigma(t_x) + c_x \\ b_y= \sigma(t_y) + c_y bx?=σ(tx?)+cx?by?=σ(ty?)+cy?这个公式降低了模型的稳定性,效果不太好
-
Linear x, y predictions instead of logistic.
- 作者尝试使用线性激活直接预测x,y偏移,而非逻辑激活。这导致了mAP几个点的下降(Leaky ReLU替代Sigmoid?)
-
Focal loss
- 作者尝试使用Focal loss。mAP大约掉了2个点。
- 作者认为YOLOv3可能已经对Focus loss试图解决的问题具有鲁棒性,因为它有单独的对象性预测和条件类预测。
- 但是我们在实践中发现并不是这样的,在检测密集目标的时候仍然会有正负样本不平衡的问题,因此Focal loss在某些情况下依然有效
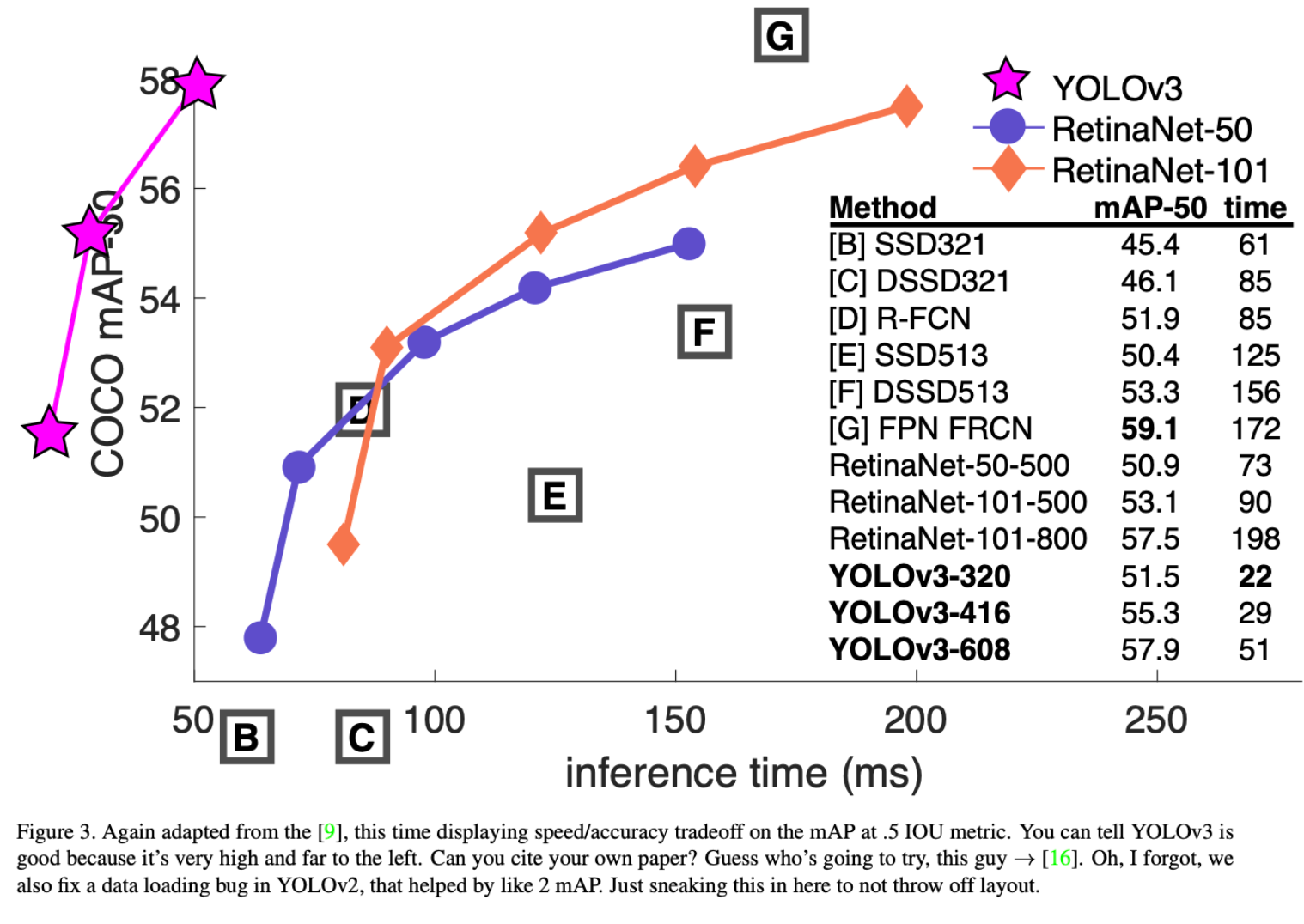
Performance
-
给张图:
-