《Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach》
dataset:
- Topic主题: yahoo dataset
共10个类别:{“Society & Culture”, “Science & Mathematics”, “Health”, “Education & Reference”,
“Computers & Internet”, “Sports”, “Business &Finance”, “Entertainment & Music”, “Family &Relationships”, “Politics & Government”}
train集(仅部分可见设置需要):分为两个,每个各五类彼此不重叠:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tGSPKx34-1628257067468)(https://user-images.githubusercontent.com/60767110/128443443-711c347c-e913-4550-8b53-152f9c3c516e.png?raw=true)]
dev集(共用):10个类,每个类别6k labeled data。
test集(共用):10个类,每个类10k labeled data
- Emotion主题: UnifyEmotion dataset
9 个类别,作者删除了多标签的: {“sadness”, “joy”,“anger”, “disgust”, “fear”, “surprise”, “shame”,“guilt”, “love”} and “none” (if no emotion applies).
train集:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y1ghQQSp-1628257067474)(https://user-images.githubusercontent.com/60767110/128443774-a04d73cc-ac1e-4ea3-a87a-e05d9d42eede.png?raw=true)]
dev集:
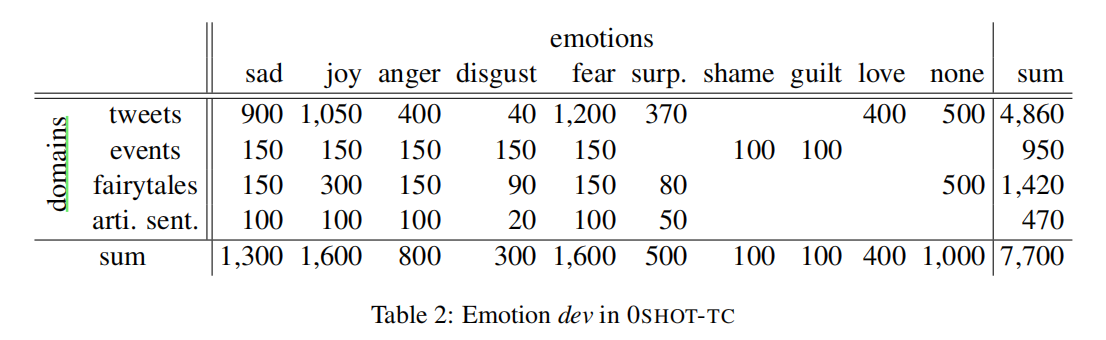
test集:
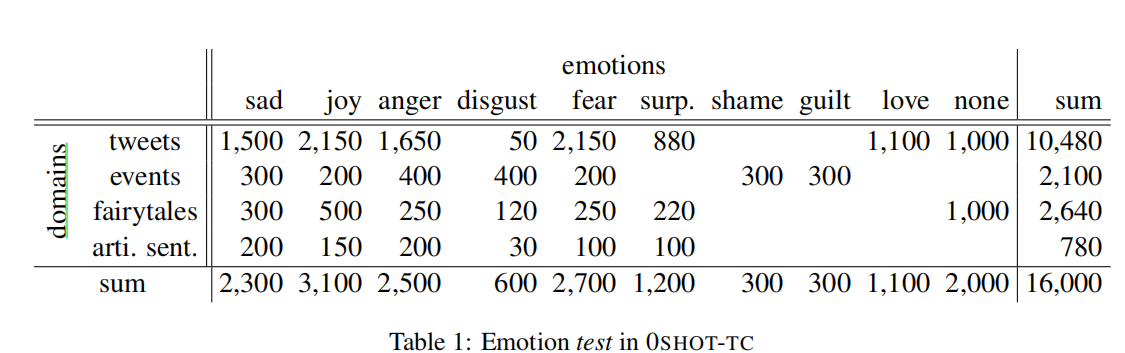
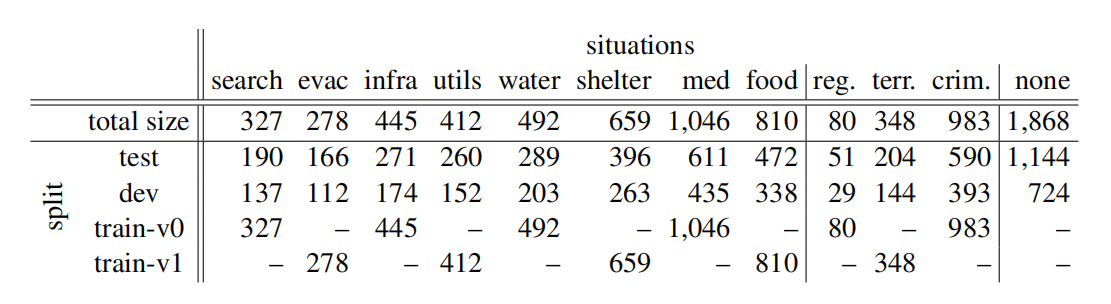
- Situation主题: Situation Typing dataset
11 个类别,作者删除多标签设置:“food supply”, “infrastructure”, “medical assistance”, “search/rescue”, “shelter”, “utilities, energy, or sanitation”, “water supply”, “evacuation”,“regime change”, “terrisms”, “crime violence”and an extra type “none”
train&dev&test:
baseline
本文使用 两种zero shot设置, 一种标签部分可见 , 一种标签完全不可见(无训练集) ,
作者方法: zeroshot模型应该像人一样根据隐含信息进行分类,所以作者将以上数据集转化成含有隐含信息的形式,即用标签名称解释与WordNet中的标签定义补充隐含信息。在测试中,一旦其中任意一个隐含信息置信度足够高,那么就可以被分类,但同时用一个严苛的策略以防将unseen的类别数据错分到见过的类别中(详见论文)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aWkgUdCY-1628257067493)(https://user-images.githubusercontent.com/60767110/128444374-a3c8f133-24f0-4719-82a2-583f40dc13fc.png?raw=true)]
作者使用bert在三个主流隐含数据集:MNLI、GLUERT和FEVER3进行隐含预训练,我们将所有数据集”转换为二进制情况:“包含”和“非隐含。若标签部分可见设置,则该模型先在train上训练,dev与test集fintune。在完全不可见设置下则直接应用该模型进行分类。
对比baseline:
- Majority:选择label名最长的作为标签(哈哈哈,这方法就离谱)
- ESA:一种无数据分类器。它将文本的单词以及标签的单词映射到维基百科文章的标题空间中,然后将文本与标签名称进行比较。这种方法并不依赖于训练集。
- Word2vec:通过计算其表示的余弦相似度来衡量标签与文本的匹配程度。文本和标签的表示都是他们单词嵌入的平均值。这种方法也不依赖训练集
- binary-bert:我们在训练集上对BERT进行微调,这将产生一个二进制分类器判断是否有隐含信息;然后我们在测试中进行测试――选择具有最大概率的标签。
result
1. 标签部分可见的结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m1ZULYev-1628257067504)(https://user-images.githubusercontent.com/60767110/128446651-0f38b8c2-1bb3-498a-91df-8547221d9162.png?raw=true)]
v0/v1”是指该列中的结果是通过对训练集v0/v1的训练获得的。“s”:可见的标签;“u”:看不见的标签。
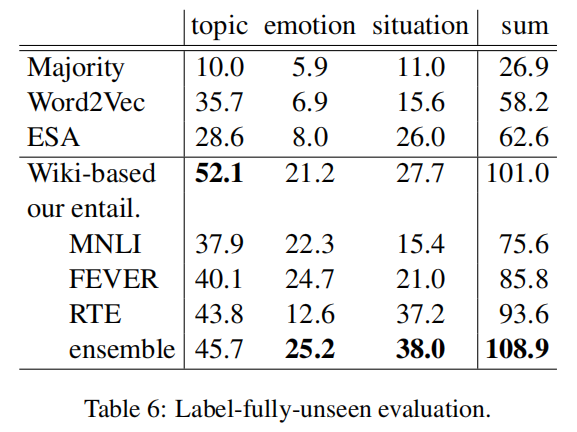
2. 标签完全不可见的结果
3. 对比三种隐含信息设置:word,defination,word&defination
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4BTYUP85-1628257067517)(https://user-images.githubusercontent.com/60767110/128447883-d81ace26-cbf0-4fc4-a05c-467f5302cdeb.png?raw=true)]
4. 标签完全不可见在situation主题下的F1分数
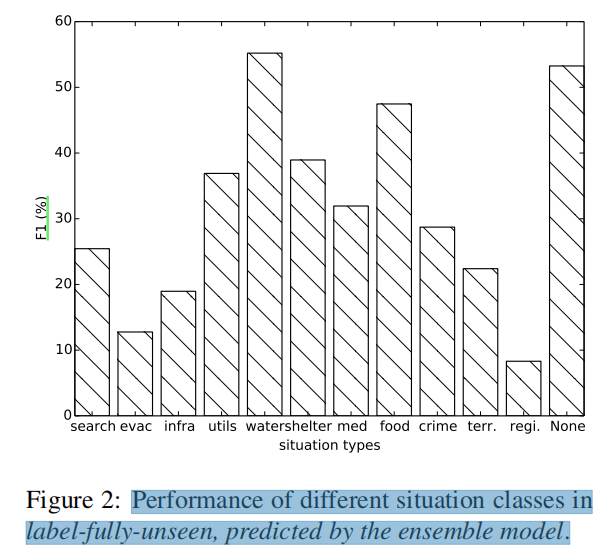
《Zero-shot Text Classification via Reinforced Self-training》
baseline
本文方法 采用的是bert+self training+Reinforciing learning,具体流程与算法如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0gm6KojJ-1628257067526)(https://user-images.githubusercontent.com/60767110/128507183-3aba29ea-b74c-4111-a505-887c3ad5dbce.png)]
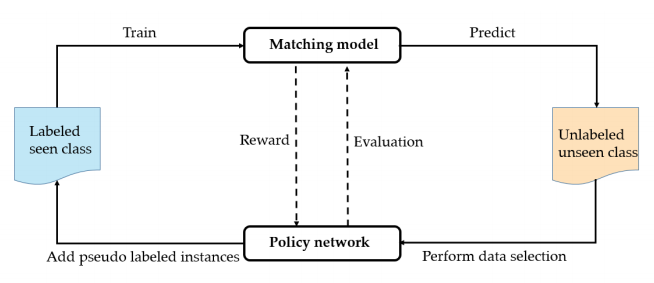
该模型算法如下(可结合模型图):
- (步骤1) 构建带标数据集Ds 与 不带标数据Du,初始化带标验真集Ds-dev 与 伪标签集Dp(初始化是空集).
- (步骤2-7) 在N1次iteration中,每次迭代用Ds与Dp训练模型,并在Du上预测,并根据预测置信度排序得到最高置信度的子集Ω
- (步骤8-22.) 每个episode开始时打乱Ω内部的各个batch顺序,在每个batch(Bk) 中,为每个实例打伪标签得到Bkp,用打伪标签Bkp训练模型并在Ds-dev与Du-dev(刚开始这个是空集,之后随着伪标加入会扩充)上训练,分别得到两个F1分数Fs与Fu,并计算reward rk:
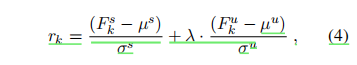
- (步骤23-27) 用reward更新policy network,让它更好的进行data selection,同时policy network计算梯度更新模型 f,一次迭代完成。
- (步骤28-32) 将打好伪标的数据Dpi更新Dp中,原本的Du中除去Dpi的数据,最后用Dp更新Du-dev
对比基线:
- Word2vec:通过计算其表示的余弦相似度来衡量标签与文本的匹配程度。文本和标签的表示都是他们单词嵌入的平均值。
- label similarity:通过单词嵌入来计算语义相似性,计算类标签与文本的每个n-gram (n=1,2,3)之间的余弦相似性,取最高者为该标签与文本的相似性,最终再取各类别最高分数的为该文本类别;
- FC和RNN+FC :分别取自这篇文章(Pushp和Srivastava,2017)中提出的架构1和2
- bert:基础的bert base
- bert+self traing:应用传统的self traing,与加入RL不同,他的选择高度一致,每次选择打伪标的实例数量固定位前k个。
- bert+RL:为本文方法,如上。
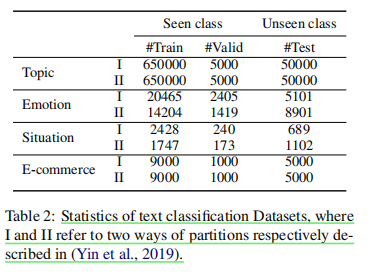
dataset
数据集前三行(topic,emotion,situation)引用的上文数据集,它增加了一个E-co电商数据集,包含十个类每个类1000个实例数据,依旧是去多标签。
本文有两种ZSL设置:广义和非广义。在非广义ZSL中,在测试时,我们的目标是给每个实例分配unseen的类标签(Yu)。而在广义ZSL中,类标签来自看不见和可见的类(Ys∪Yu)。在我们的实验中没有采用上文严格的测试政策。
其中I和II分别指上一篇文章中描述的zeroshot 训练集的的划分方式,分成两组各五类。
result
1.两种设置在四个数据集中的实验分数:
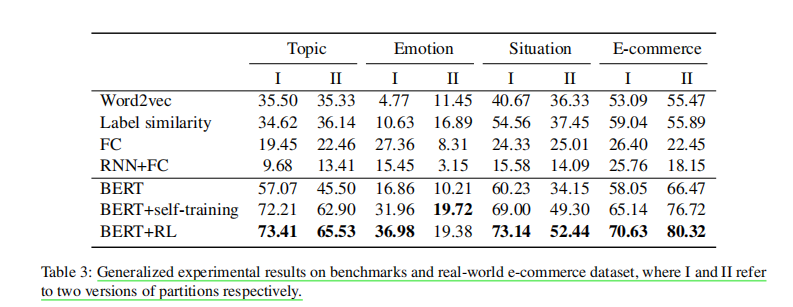
2.广义zsl中的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-140Zkxnb-1628257067541)(https://user-images.githubusercontent.com/60767110/128513473-52093ae2-1a29-4e30-affe-02e032b56075.png)]
3.非广义zsl的结果:
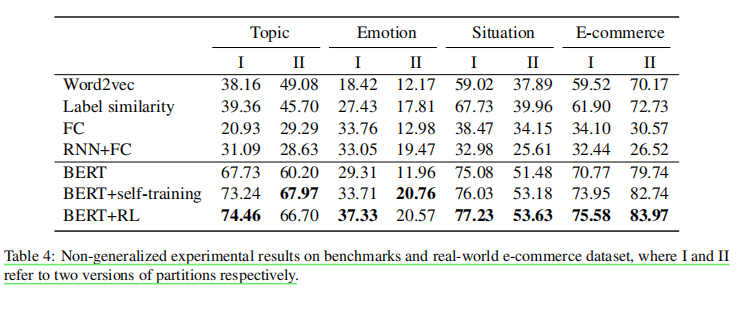
这里我有一些疑问,感觉这个和上一篇的完全不可见的设置有区别,因为他也有train集和II,说明他并不是像上一篇的完全不可见设置那样是无监督的。我理解本文两种都设置有训练集,只不过非广义的的test集和train集类别是不重叠,所以测试时打伪标时只能分配unseen的标签。
4.RL的data selection策略(虚线)与手动选择策略(折线)的性能对比

5.bert基线判断对的文本(左)与bert判断错,bert+RL判断对的文本(右)
