YOLOV2
论文地址:PDF
论文翻译:翻译
网上找的Pytorch版本:https://github.com/tztztztztz/yolov2.pytorch
按照论文的排版我来写下我的理解,如果不对地方,还请大佬们指出,共同进步,不甚感激~
一. Better
这个better里面包含了:
1.Batch Normalization
每层卷积之后使用 Batch Norm,丢弃了dropout和别的正则化。Batch Norm使得卷积后的数据都分布在0-1,这也使的数据不会分布太散,有利于模型收敛。其实这个并没有什么好讲的,但是在作者那个年代是一个提高。
2.High Resolution Classifier
这个就是指作者使用了高分辨率的分类图片进行训练,其实作者分两步,一是还是用224x224分辨率的分类图片进行训练(160个epoch)(参考),后面在训练好的模型上进行 fine tune,把模型的输入分辨率提高到 448x448 进行训练10个epoch(前面到这里都是在ImageNet上训练),接着作者再拿这个模型在检测数据集上进行fine tune 训练。
3.Convolutional With Anchor Box
这个个人感觉是重点,作者借鉴了Faster-RCNN,使用了 Anchor Box。作者根据规律发现,目标,尤其是大物体,其中心一般在图片的中央。作者还为了 feature extractor 后的 feature map 只有一个中心,基于这两点,作者把网络的图片输入调整为 416x416,且经过了 32 次下采样(这里用32次可能不是很标准说法),得到 13x13的 feature map,且中心只有一个。
对于 13x13 的feature map,作者根据 K-means (下面详细讲解)的方法在VOC和COCO数据集上进行划分,综合召回率和模型复杂度,选择了 K=5(见下图Figure 2)。就是 feature map 上的每个 cell 单元有 5 个 不同宽高的 anchor box,这5个anchor box 的宽高是怎么得到的?就是根据 k=5时对应的每个簇的中心box,这个中心box的宽高就作为anchor的宽高,共有5个簇,所以有5个中心box,也就有5个不同宽高。

下图是 13x13 的 feature map图,图上只画了一个cell的5个anchor box,比例只是我随意画的。

每个cell有5个anchor box,且每个anchor box所对应的predictor的预测是各自独立的(网上有很多博客说是anchor预测,在计算损失函数时前12800是需要anchor box预测的,但是个人感觉说anchor box预测不是很好,因为是利用了anchor box与ground truth来找最大的IOU,然后根据找到的第几个anchor box,找到对应的预测值,把这个预测值进行计算损失函数),yolov1之前每个cell有两个预测框,但是这两个预测框是共享预测类别,就是两个框的预测类别结果是一致的。对于预测图,如下,图片参考:

YoloV2就是每个anchor对应的pred各自预测各自的,所以每个anchor box对应的预测值有 4+1+20 = (x,y,w,h)+confidence + 20个类别(这是在VOC数据集,别的数据集就不是这个数)。
这里说下这个confidence,包含两部分:含有物体的概率以及预测框与ground truth的IOU(参考),
即:? ? ? ? ? confidence = P(Object)xIOU(pred与ground truth)
含有物体与20个种类不是一回事,含有物体只是代表这个框中有物体的概率,至于哪个物体,是20个种类做的。
这里讲下 anchor box 的作用,首先 416x416 的图片经过卷积,下采样为32,得到 13x13 的 feature map,与此同时,ground truth 的 box 也经过了 下采样,其实就是除以32,得到在feature map上的位置,但是要计算出是在第几个cell,因为需要对应cell的anchor box来进行就算 IOU,然后得到第几个anchor box对应的pred来进行计算损失函数。因为知道ground truth在第几个cell,以及用对应cell中的anchor box进行IOU,这个时候,x,y坐标产生的影响其实是很小的(x,y已经归一化到0-1之间)
3.Dimension Clusters
这个其实就是作者利用K-Means找到最合适的每个cell中anchor box的数量,以及anchor box的宽高。但是这里作者的创新点是不利用欧式距离来计算,作者说因为大物体的误差比小物体的错误(作者没有具体解释)。
个人认为:
1.因为作者参考的是Faster-Rcnn,其cell中的9个anchor box也就是宽高不同比例,所以作者把数据集中的图片利用k-means来进行分cluster,把宽高类似的放在一起,这样就找到5中不同的宽高(5是综合了召回率和模型复杂度而得到的,模型复杂度其实就是计算量)。
2.预测的框准不准,其实就是看anchor box与ground box 匹不匹配,如果刚开始误差就小,那模型训练起来很快就能收敛。训练集中每张图片目标的坐标都不一样,如果用欧式距离,那找到的k是根据坐标而得到的,但是这个似乎没什么用,因为在知道第几个anchor box对应的预测值进行与ground truth计算loss的时候,是看IOU,其x,y产生的差的平方是很小的(x,y已经归一化到0-1之间),这个时候,w,h就产生很大影响,当然,作者的loss还有关于IOU的loss。
第一点感觉很符合,第二点有点牵强,不过也有道理。
作者采用了一种新的计算方法:
Dist = 1 - IOU,Dist越小,说明IOU越大。
对于K-Means的理解,推荐这两个博客,他们一个是画出来cluster的分布,一个是计算出宽高,比较好,强烈推荐:
1.https://blog.csdn.net/Mr_health/article/details/94216654 画出cluster分布
2.https://blog.csdn.net/hrsstudy/article/details/71173305?utm_source=itdadao&utm_medium=referral 计算出宽高
当然,地址2这个博主没有把数据集放出来,我自己整理了个voc数据集,然后运行代码,从代码可以更清晰看到,对于每个族的宽高,作者是用的是这个族中所有标注框的平均值。从这就可以知道,yolov2作者也是这么计算的。yolov2有5个anchor,每个anchor的宽高就是作者用的voc或者coco数据集的k-mean后每个族的平均值。
统计数据集代码,用保存的txt运行地址2中的代码
# Script taken from https://pjreddie.com/media/files/voc_label.py
?import xml.etree.ElementTree as ET
?import pickle
?import os
?from os import listdir, getcwd
?from os.path import join
?from imutils import paths
?from tqdm import tqdm
??
?sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
??
?classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
??
??
?def convert(box):
? ? ?x = (box[0] + box[1])/2.0
? ? ?y = (box[2] + box[3])/2.0
? ? ?w = box[1] - box[0]
? ? ?h = box[3] - box[2]
? ? ?return (x,y,w,h)
??
?def convert_annotation(xml_file):
? ? ?in_file = open(xml_file)
? ? ?tree=ET.parse(in_file)
? ? ?root = tree.getroot()
? ? ?size = root.find('size')
? ? ?w = int(size.find('width').text)
? ? ?h = int(size.find('height').text)
??
? ? ?bbox = []
? ? ?for obj in root.iter('object'):
? ? ? ? ?difficult = obj.find('difficult').text
? ? ? ? ?cls = obj.find('name').text
? ? ? ? ?if cls not in classes or int(difficult) == 1:
? ? ? ? ? ? ?continue
? ? ? ? ?cls_id = classes.index(cls)
? ? ? ? ?xmlbox = obj.find('bndbox')
? ? ? ? ?box = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
? ? ? ? ?x = (box[0] + box[1]) / 2.0
? ? ? ? ?y = (box[2] + box[3]) / 2.0
? ? ? ? ?w = box[1] - box[0]
? ? ? ? ?h = box[3] - box[2]
? ? ? ? ?bbox.append([str(cls_id), str(x), str(y), str(w), str(h)])
??
? ? ?return bbox
??
??
??
?xml_root = r'D:\data\voc\VOCdevkit\VOC2007\Annotations'
?xml_all = list(paths.list_files(xml_root))
?all_box = []
?for xml_file in tqdm(xml_all):
? ? ?all_box += convert_annotation(xml_file)
??
?txt_path = r'D:\data\voc\box.txt'
?with open(txt_path, 'w') as f:
? ? ?for box in tqdm(all_box):
? ? ? ? ?str_box = ' '.join(box)
? ? ? ? ?f.write(str_box+'\n')4.Direct location prediction
什么叫位置的直接预测呢?这里作者是跟Faster-Rcnn对比的,因为Faster-Rcnn预测的是偏移量,作者这里根据公式可以直接得到坐标(怎么说呢,如果不加cell的坐标,那得到的是相对坐标)。作者为什么这么做呢?
首先先指出YoloV2论文中公式写错了,因为按照论文公式,我真的看不懂 tx=1会往右shift一个anchor box的宽度,明明是 w-xa,这个怎么成立?,所以作者写错了。参考 博主根据Faster-rcnn的位置预测,指出了yolov2作者公式应该为 “+”,个人认为还是有道理的,因为这样,才能对的上yolov2作者说tx=1,及那个向右偏移box的宽度。


回到YoloV2作者说这个公式会导致训练很不稳定,因为tx没有限制,会导致预测框的位置会出现在图片的任何地方,所以作者限制了这两个参数,不用offset,而改为直接预测坐标。因为已经知道第几个cell了,第几个cell的左上角坐标也是知道的,每个cell长宽为1,然后再知道 x,y,就可以知道坐标了,这就是直接预测坐标。
当 x, y 限制在 0-1,这样模型训练更稳定,更易收敛,个人感觉有点类似 Bacht Norm。
预测经典图如下:

参考 这个人说明还是蛮好的

预测结果转换:参考
?center_x=grid_x+sigmoid(x)
?center_y=grid_x+sigmoid(y)
?w=exp(w)*anchor_w
?h=exp(h)*anchor_h
?confidence=sigmoid(confidence)
?cls1=sigmoid(cls1)
?cls2=sigmoid(cls1)?xy_pred = torch.sigmoid(out[:, :, 0:2]) # 这一段代码写的很简单清晰,非常易理解
?conf_pred = torch.sigmoid(out[:, :, 4:5])
?hw_pred = torch.exp(out[:, :, 2:4])
?class_score = out[:, :, 5:]
?class_pred = F.softmax(class_score, dim=-1)
?delta_pred = torch.cat([xy_pred, hw_pred], dim=-1)5.Fine-Grained Featrues
字面意思是更细粒特征,卷积一般到最后,剩下的都是大物体的特征,一般小物体随着卷积层往下,会渐渐丢失掉(当然不是绝对哦)。作者增加了一个称为 passthrough layer,就是把卷积中为特征大小为 26x26 这层特征直接和最后的13x13 feature map 进行拼接,这里不是硬拼,而是把26x26的特征分为 4个 13x13,当然,作者的做法是每行隔一个像素点取一个,然后再隔行取,这样就得到4个13x13,然后再和卷积最后的13x13进行拼接。如下图所示:

意思其实很简单,但是当时看了作者源码和pytorch源码,当时看了很懵,也发现了对pytorch中tensor操作不熟的问题。
首先是C的源码
对于regorg的讲解比较好,参考
这个有 reorg 公式 参考,其实也不是很难,就是自己知道怎么来取值,然后用代码来实现,理解 w2,h2 怎么计算就可以了,别的就是位置了。但是刚开始看的时候很懵,而且花费了很长时间在这上面,其实读懂代码,理解就好,当然自己会实现更好。
// reorg_cpu(net.input, l.w, l.h, l.c, l.batch, l.stride, 0, l.output);
?void reorg_cpu(float *x, int w, int h, int c, int batch, int stride, int forward, float *out)
?{
? ? ?int b,i,j,k;
? ? ?int out_c = c/(stride*stride); // 512/4 = 128
?
? ? ?for(b = 0; b < batch; ++b){
? ? ? ? ?for(k = 0; k < c; ++k){
? ? ? ? ? ? ?for(j = 0; j < h; ++j){
? ? ? ? ? ? ? ? ?for(i = 0; i < w; ++i){
? ? ? ? ? ? ? ? ? ? ?int in_index ?= i + w*(j + h*(k + c*b)); // 采样保存在13×13*512的位置的index
? ? ? ? ? ? ? ? ? ? ?int c2 = k % out_c; // 第几个512的reshape,[0,1,2,3]
? ? ? ? ? ? ? ? ? ? ?int offset = k / out_c; // 偏移量,第几中reshape的第几个
? ? ? ? ? ? ? ? ? ? ?int w2 = i*stride + offset % stride;
? ? ? ? ? ? ? ? ? ? ?int h2 = j*stride + offset / stride;
? ? ? ? ? ? ? ? ? ? ?int out_index = w2 + w*stride*(h2 + h*stride*(c2 + out_c*b)); ?// 获取在26*26*512采样位置的index
? ? ? ? ? ? ? ? ? ? ?if(forward) out[out_index] = x[in_index]; // 梯度反传
? ? ? ? ? ? ? ? ? ? ?else out[in_index] = x[out_index]; // 前向传播
? ? ? ? ? ? ? ? }
? ? ? ? ? ? }
? ? ? ? }
? ? }
?} ?
?

?
如下是Pytorch实现,其实意思一样,但是需要理解transpose(i, j)的i,j 这才是深入理解了对tensor高维的操作。

def forward(self, x):
? B, C, H, W = x.data.size()
? ws = self.stride
? hs = self.stride
? x = x.view(B, C, int(H / hs), hs, int(W / ws), ws).transpose(3, 4).contiguous()
? x = x.view(B, C, int(H / hs * W / ws), hs * ws).transpose(2, 3).contiguous()
? x = x.view(B, C, hs * ws, int(H / hs), int(W / ws)).transpose(1, 2).contiguous()
? x = x.view(B, hs * ws * C, int(H / hs), int(W / ws))
? return x这个人的图片也比较好看,参考

6.Mulit-Scale Training
这个是多尺度训练,作者设定了一些尺寸,都是32的倍数,有如下:[(320, 320), (352, 352), (384, 384),(416, 416), ,(448, 448),(480, 480),(512, 512),(544, 544),(576, 576),(608, 608)]。
作者也提及了,其model只用了卷积和Pooling层,其后面没有全连接层,所以可以输入任何尺寸的图片(这里提及下,如果有全连接层,是需要一开始就确定好最后卷积的size,以及filter数量,因为全连接是跟每一个channel上的每个像素都连接,那w参数就要事先确定好,如果不事先确定好,那就连不了,这就是为啥后来SPP-Net用 Spatial Pyramid Pooling了)。
作者是每10个epoch就改变一下输入尺寸。
7.Further Experiments
此处不需要写
三.Faster
1.Darknet-19
作者这个网络就只有卷积和Max Pooling
2.Training for classification / Training for detection
首先作者训练yolo9000是先在分类数据集上进行训练,然后用分类数据集上得到的model进行fine tune,然后在检测数据集上进行训练。
具体过程是,
1.先用 Darknet-19在Image Net分类数据上进行训练160个epoch,网络输入图片大小为224x224,使用随机梯度下降法,学习率=0.1,还有一些数据增强方法。
2.接着把网络输入改为448x448,继续在Image Net分类数据上训练10个epoch
3.然后去除网络的最后的卷积层和池化层以及softmax层,增加了3个3x3,channel为1024的卷积,最后再跟上一个1x1的卷积,channel数为我们需要输出的大小,比如VOC数据集,一个cell需要输出:5x(4+1+20)=125,然后比如是13x13,那么数量是 13x13x125(对于 13x13x125 这一点,我不是很确定,但是又觉的应该是这样,还请网友来指正)下图描述比较好,参考

4.接着作者拿这个fine tune的网络在检测数据集上进行训练160个epoch,分别在第60和90 epoch的时候进行学习率除以10,用的是类似YoloV1和SSD的数据增强方式。
对于作者修改了网络最后几层,那之前训练好的模型怎么用呢?这里我的理解是,作者加载了前面没有修改的网络层的权值(就是用训练好的模型的前面几层权重来赋值给新的网络前面对应的几层权重),然后后面增加的几层可以随机初始化,然后在检测数据集上训练,得到这些权重。
四.Stronger
这一节也看的,原理就是把分类数据集拿来训练,经过作者的设计,就可以达到训练要求,我没怎么看,wordtree理解起来有点难,大家可以参考别人的。
五.损失函数
这个才是关键,但是作者论文似乎就没提,而且网上的写法分两种,这里我都列举出来。
1.12800版本,就是损失函数中有迭代次数

以下第几行用的是上图中第一个图
1.第一行是计算没有目标的anchor的置信度损失,也有说预测背景的anchor的置信度损失(参考),如:“ 但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。 ”
对于加粗的这段话,讲的不详细,我有点要补充,应该是先找到ground truth落在哪个cell中,然后这个cell中5个anchor box哪个与ground truth的IOU最大,最大的这个anchor box来预测目标,但是剩下的4个anchor box计算与ground truth的IOU,找到4个中IOU最大的那个 anchor box,然后看它的iou是否小于设定的阈值(0.6),如果小于,那么这个框就计算置信度损失,如果大于设置的阈值,那么这个框不参与任何损失计算,直接忽略。
2.第二行是预测框与anchor box的误差,只有前128000次迭代才计算,这里是为了让预测框能更快的学习到能够预测出和anchor box差不多大小的能力,包含了 x,y, w, h的损失。
3.第三行是找到的第几个cell中第几个anchor box对应的预测值与ground truth的损失计算。
4.第四行是计算预测的pred的confidence损失,confidence 的计算如下,
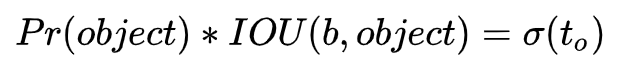
作者就是让这个confidence等于预测box与ground truth的IOU,上面delta(to)就是无限接近IOU,那Pr(object)就要接近1。但是我不是很能理解,如果是confidence接近IOU,那为啥还要有Pr(object)? Pr(object)其实表示的是这个框有物体的概率,但是在计算 IOU 损失的时候i,已经明确表示有物体,所以Pr(object)=1,然后就只有IOU。当然,这是我个人理解,还请大家指正。如果对照图二第四行,其后面有个 ’0‘ ,那这个0怎么来的呢,就是Pr(object)=0,那我的这个说法就很讲的通了。
5.第五行是计算分类误差,作者用的是L2损失,把分类用回归做了(难道L2是专用于回归损失,一旦用了L2就是当作回归分析了?),这里理解回归就是直接连续的,分类是离散的点。
Question
1.anchor通过聚类得到,那么每个cell中anchor的个数怎么得到,以及每个anchor的尺寸定义怎么得到的?
我突然想到,因为作者是使用K-Means的方法得到5个anchor,为什么选5,是作者综合了速度和复杂性。那这5个anchor的avg iou尺寸应该就是作者得到的每个anchor的尺寸,我是这么理解的,如果有不对,还请大家指正。
2.对于K-mean的原理
参考:https://blog.csdn.net/xiaomifanhxx/article/details/81215051
首先假设有 A ,B , C, D, E 这五个点,但是我需要把这五个点分为两个族,那这里的 k=2,然后先随机指定 k1,k2的位置。
(1)然后依次计算 A 到 k1 的距离 D_A_k1, 到 k2 的距离 D_A_k2,然后比较 D_A_k1与 D_A_k2的大小,假设 D_A_k1 < D_A_k2,那么 A 属于K1族;同理,依次计算 B, C, D, E 到 k1, k2 的距离;假设 A, B, C 与 k1 距离最近,C, D 与 k1 距离最近,那么,把 k1移到 A, B, C, k2 移到 C, D 中心;
接着重复步骤(1),直到 k1, k2没有需要移动的,然后就划分好了两个族。如下图(图片来自上面的参考)

3.为什么anchor只有 width,height?
参考:https://blog.csdn.net/xiaomifanhxx/article/details/81215051
“卷积神经网络具有平移不变性,且anchor boxes的位置被每个栅格固定,因此我们只需要通过k-means计算出anchor boxes的width和height即可,即object-class,x,y三个值我们不需要。 ”
博主说每个 anchor 被固定在每个栅格,这也就解释了为啥yolov2源码中anchor只有 width, height。而且每个cell都有5个anchor,且5个anchor宽高不一样,所以根本就与 x, y 没有半毛钱关系。
这里看到一个作者用代码实现了计算 anchor 的尺寸,还是蛮厉害的,
参考:https://blog.csdn.net/hrsstudy/article/details/71173305?utm_source=itdadao&utm_medium=referral
当然,这个博主没有把数据集放出来,我自己整理了个voc数据集,然后运行代码,从代码可以更清晰看到,对于每个族的宽高,作者是用的是这个族中每个标注框与中心族的iou的平均值,就是这族的所有标注框与中心族的iou之和的平均值。从这就可以知道,yolov2作者也是这么计算的。yolov2有5个anchor,每个anchor的宽高就是作者用的voc或者coco数据集的k-mean后每个族的平均值。
4.yolov2预测的啥,就是faster-rcnn用的是RPN推荐的位置,把这个位置对应的图片给网络进行训练,哪yolov2是不是就只用了最后feature map 13x13 进行训练,就是没有找对应位置图片进行训练?
permute(2, 0, 1) 转换维度,刚刚以为是 RGB->BGR,但是怎么看不通,是 HXWXC->CXHXW后记:
看了不少博客,时间拖了也很久,论文三到四天就看完了,找别人写的好的框架和读代码费了好久时间,然后一些知识点理解又费时间,这样前前后后大概一个月时间(非工作时间)。
刚开始写不知道该怎么写,YoloV2作者写的其实也乱,后来就干脆根据论文各个组题来写,虽然自己理解了,但是真正写的时候还是感觉在挤墨水一样,还有种东拼西凑的感觉,都是网上各个博客的,知识来源于网络,也反馈于网络,应该更青于蓝。
当真正写出来后,感觉其实也就那么点东西,但是深入理解各个点才是王道。
参考:
1.?https://github.com/tztztztztz/yolov2.pytorch 这个仓库看看 2.?https://gitee.com/yangdashi/yolov2_pytorch 这个仓库看看
3.?https://blog.csdn.net/weixin_40227656/article/details/116018040?4.https://blog.csdn.net/u011974639/article/details/78208896 https://blog.csdn.net/weixin_39627455/article/details/111230328
9.?https://machinethink.net/blog/object-detection/ 还没看 10.?https://www.cnblogs.com/winslam/p/13792684.html 讲的还不错
11.?https://zhuanlan.zhihu.com/p/44331837 讲passthrough图画的不错 12.?https://blog.csdn.net/qq_17550379/article/details/78948839 这个有 reorg 公式,但是没看懂 13.?https://blog.csdn.net/YMilton/article/details/117282846 这个reorg图画的也还不错,参数设置也不错
14.?https://www.pianshen.com/article/5469908747/ 这个darknet训练160个epoch,后面检测网络也有,对比的网络修改图比较好,比较清晰
15.?https://blog.csdn.net/xiaomifanhxx/article/details/81215051 k-means原理讲解不错 16.?https://blog.csdn.net/Mr_health/article/details/94216654 k-means画出来
以下四个可以对照着看讲loss部分
17.?https://blog.csdn.net/w55100/article/details/89069079 大致看了下,还没仔细看,感觉讲loss比较不错
18.?https://www.cnblogs.com/Henry-ZHAO/p/12725294.html 这个人的博客讲损失函数也还不错 19.?https://www.jianshu.com/p/517a1b344a88 https://zhuanlan.zhihu.com/p/40659490?
20.?https://blog.csdn.net/xiaohu2022/article/details/80666655 可以看看这篇文章,看看这个人的map是怎么计算的,然后看看他的参考
21.?https://blog.csdn.net/w55100/article/details/89083776 Pytorch快速搭网络 22.?https://blog.csdn.net/u013289254/article/details/98785869 卷积之后,如果要接BN操作,最好是不设置偏置,因为不起作用,而且占显卡内存