目录
1.1?自回归语言模型和自编码语言模型(AR:autoregressive)
3.2?排列语言模型(Permutation Language Modeling)
3.2?双流自我注意力结构(Two-Stream Self-Attention for Target-Aware Representations)
Paper:XLNet: Generalized Autoregressive Pretraining for Language Understanding
Code:XLNet code
1. 论文简介
18年底谷歌爸爸推出了bert,该模型一经问世就占据了nlp界的统治地位,如今CMU和google brain联手推出了bert的改进版xlnet。
Bert这种基于自编码的具有双向建模能力的模型性能比基于自回归建模的语言模型的性能要好。但是Bert因为采用了Mask的训练方式, 忽略了被Mask掉词之间的依赖关系;同时因为Bert是基于自编码的,所以和基于自回归的模型相比较的,在面对生成任务的时候有缺陷;而且因为Bert是基于transformer的,所以在序列长度方面有限制。所以作者就希望可以可以融合自编码和自回归的优点,然后设计出来一个模型。
1.1?自回归语言模型和自编码语言模型(AR:autoregressive)
其实就是指RNN这一类的模型,这一类的模型的优化目标是最大化概率??或者最大化概率?
自回归语言模型有以下的优点:(其实就是rnn的优点) 自回归语言模型的模型符合生成任务的需求,就是那种一个一个的生成我们需要的字符。类似人写字一样一个一个的写出来.
同时自回归语言模型可以学习要预测词之间的的关系,因为被预测的词是根据上一个词预测出来的。
例如,给定一个序列?, AR模型就是在计算其极大似然估计
?即已知
之前的序列,预测
的值.?
当然也可以反着来??即已知
之后的序列,预测
,?
看完之后相信你也能发现AR模型的缺点,没错该模型是单向的,我们更希望的是根据上下文来预测目标,而不单是上文或者下文,之前open AI提出的GPT就是采用的AR模式,包括GPT2.0也是该模式,那么为什么open ai头要这么铁坚持采用单向模型呢,看完下文你就知道了。
缺点::自回归语言模型难以并行计算,以及无法提供一些语言理解任务中需要的双向上下文信息。作者人为, 虽然有双线RNN的模型, 但是这些模型本身都是单向, 然后拼接成的双向.。
在xlnet中,最终还是采用了AR模型,但是怎么解决这个上下文的问题呢,这就是本文的一个重点。
?
2.2 自编码语言模型(AE:autoencoding)
AE模型采用的就是以上下文的方式,最典型的成功案例就是bert。我们简单回顾下bert的预训练阶段,预训练包括了两个任务,Masked Language Model与Next Sentence Prediction,Next Sentence Prediction即判断两个序列的推断关系,Masked Language Model采用了一个标志位[MASK]来随机替换一些词,再用[MASK]的上下文来预测[MASK]的真实值,bert的最大问题也是处在这个MASK的点,因为在微调阶段,没有MASK这就导致预训练和微调数据的不统一,从而引入了一些人为误差,我觉得这应该就是为什么GPT坚持采用AR模型的原因。
2.两个模型(AR与AE)的优缺点分别为:
2.1.?独立假设
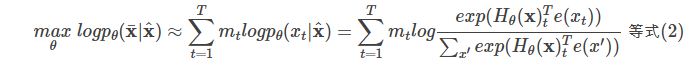 ?
?
注意等式(2)的约等号≈,它的意思是假设在给定x^的条件下被Mask的词是独立的(没有关系的),这个显然并不成立,比如”New York is a city”,假设我们Mask住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。而公式(1)没有这样的独立性假设,它是严格的等号。
2.2?输入噪声
BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tuning中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
2.3 双向上下文
语言模型只能参考一个方向的上下文,而BERT可以参考双向整个句子的上下文,因此这一点BERT更好一些。
ELMo和GPT最大的问题就是传统的语言模型是单向的――我们是根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子”The animal didn’t cross the street because it was too tired”。我们在编码it的语义的时候需要同时利用前后的信息,因为在这个句子中,it可能指代animal也可能指代street。根据tired,我们推断它指代的是animal,因为street是不能tired。但是如果把tired改成wide,那么it就是指代street了。传统的语言模型,不管是RNN还是Transformer,它都只能利用单方向的信息。比如前向的RNN,在编码it的时候它看到了animal和street,但是它还没有看到tired,因此它不能确定it到底指代什么。如果是后向的RNN,在编码的时候它看到了tired,但是它还根本没看到animal,因此它也不能知道指代的是animal。Transformer的Self-Attention理论上是可以同时attend to到这两个词的,但是根据前面的介绍,由于我们需要用Transformer来学习语言模型,因此必须用Mask来让它看不到未来的信息,所以它也不能解决这个问题的。注意:即使ELMo训练了双向的两个RNN,但是一个RNN只能看一个方向,因此也是无法”同时”利用前后两个方向的信息的。也许有的读者会问,我的RNN有很多层,比如第一层的正向RNN在编码it的时候编码了animal和street的语义,反向RNN编码了tired的语义,然后第二层的RNN就能同时看到这两个语义,然后判断出it指代animal。理论上是有这种可能,但是实际上很难。举个反例,理论上一个三层(一个隐层)的全连接网络能够拟合任何函数,那我们还需要更多层词的全连接网络或者CNN、RNN干什么呢?如果数据不是足够足够多,如果不对网络结构做任何约束,那么它有很多中拟合的方法,其中很多是过拟合的。但是通过对网络结构的约束,比如CNN的局部特效,RNN的时序特效,多层网络的层次结构,对它进行了很多约束,从而使得它能够更好的收敛到最佳的参数。我们研究不同的网络结构(包括resnet、dropout、batchnorm等等)都是为了对网络增加额外的(先验的)约束。
?
3. XLNet贡献或主要改进
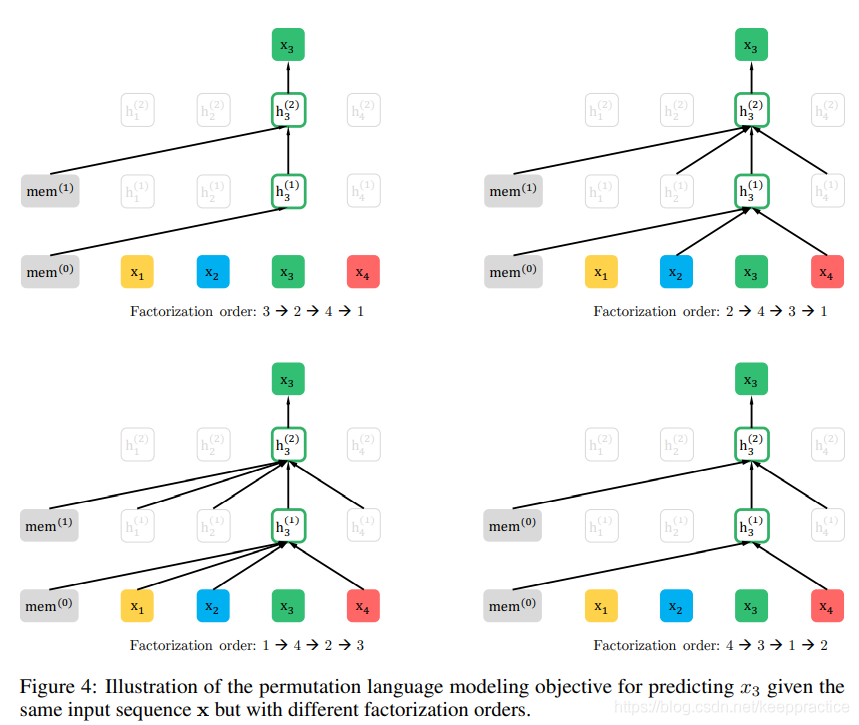
3.2?排列语言模型(Permutation Language Modeling)
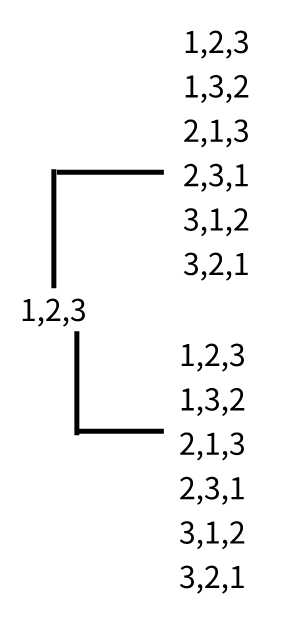
??为了引入自回归模型的优点,同时可以看到上下文,论文中提出了排列语言模型。例如序列[1,2,3,4],如果是为了预测3,那么我们怎么样才能使用自回归的方式让3看到上下文呢?
??如图3-1,打乱序列的顺序之后输入到模型里面,就可以发现,当我们需要预测3的时候,我们能看到的只能是3前面的单词,如果打乱序列顺序之后,我们可以看到下图(3->2->4->1)3什么看不到,(2->4->3->1)3可以看到2,4;(1->4->2->3)第二行3可以看到1,4,2;以此类推,那么要预测的词就可以看到上下文了。
3.2?双流自我注意力结构(Two-Stream Self-Attention for Target-Aware Representations)
3.2.1 why
?假设我们要求这样的一个对数似然??,如果采用标准的softmax的话,那么
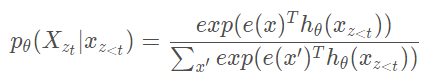
?其中?表示的是添加了mask后的transformer的输出值,可以发现
?并不依赖于其要预测的内容的位置信息,?因为无论预测目标的位置在哪里,因式分解后得到的所有情况都是一样的,并且transformer的权重对于不同的情况是一样的,因此无论目标位置怎么变都能得到相同的分布结果,如下图所示,假如我们的序列index表示为[1,2,3],对于目标2与3来说,其因式分解后的结果是一样的,那么经过transformer之后得到的结果肯定也是一样的。
?
这就导致模型没法得到正确的表述,
通俗的一个例子, 例如重排序列是3-2-4-1,在预测单词4的时候,模型用这种mask方式可以看到4自己的信息;如果把4也mask掉,那么在预测1的时候又看不到4的信息了。
注意:输入是保持不变的1-2-3-4.只有在Xlnet模型里才重排。
3.2.2?how
为了解决这个问题,论文中提出来新的分布计算方法,来实现目标位置感知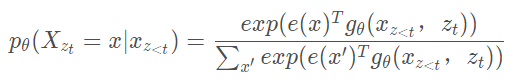
?其中?是新的表示形式,并且把位置信息
作为了其输入。
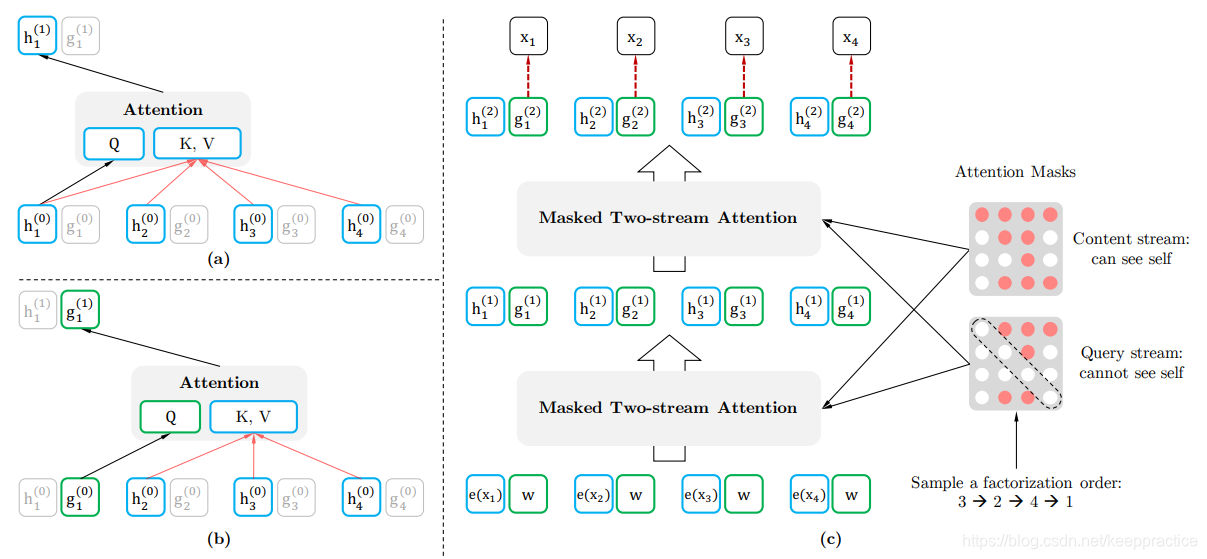
论文把该方法称为Two-Stream Self-Attention,双流自注意力,该机制需要解决了两个问题
- 如果目标是预测?
,? ?
?那么只能有其位置信息
,?而不能包含内容信息
.
- 如果目标是预测其他tokens即
,?那么应该包含
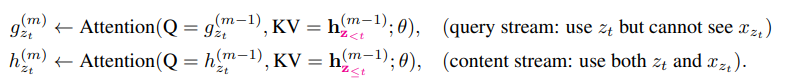
双流自注意力分为内容表征(content representation)与查询表征query representation
内容表征(content representation)
即,?下文用
表示,该表述和传统的transformer一样,同时编码了上下文和
自身
![]() ?
?
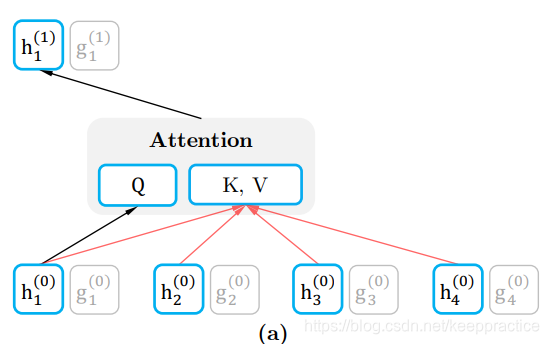
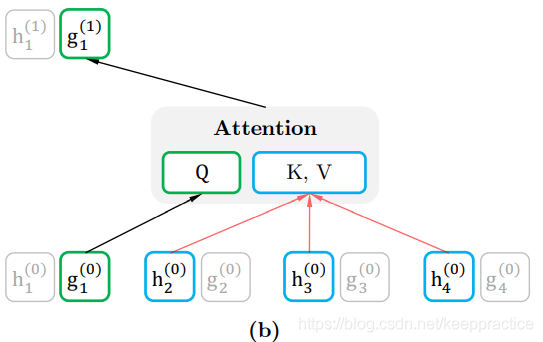
查询表征query representation,即下文用该表述包含上下文的内容信息
和目标的位置信息
,但是不包括目标的内容信息
,从图中可以看到,K与V的计算并没有包括Q,自然也就无法获取到目标的内容信息,但是目标的位置信息在计算Q的时候保留了下来,
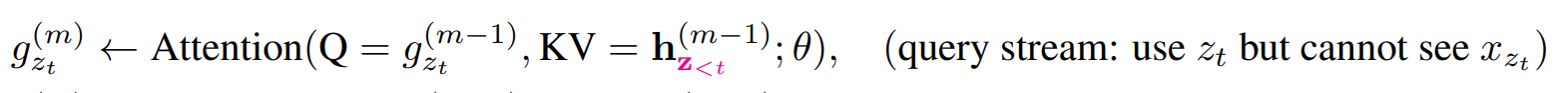
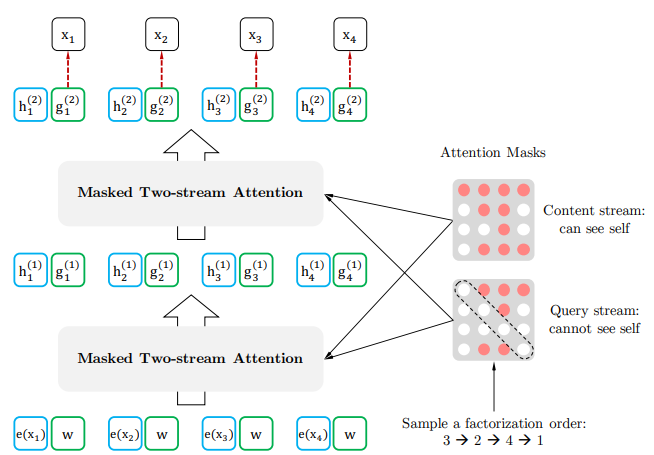
?最后我们看下总的计算过程,首先,第一层的查询流是随机初始化了一个向量即,内容流是采用的词向量即
,
self-attention的计算过程中两个流的网络权重是共享的,最后在微调阶段,只需要简单的把query stream移除,只采用content stream即可。
?
?
3.3?集成Transformer-XL
除了上文提到的优化点,作者还将transformer-xl的两个最重要的技术点应用了进来,即相对位置编码与片段循环机制。我们先看下片段循环机制。
1.片段循环机制
transformer-xl的提出主要是为了解决超长序列的依赖问题,对于普通的transformer由于有一个最长序列的超参数控制其长度,对于特别长的序列就会导致丢失一些信息,transformer-xl就能解决这个问题。我们看个例子,假设我们有一个长度为1000的序列,如果我们设置transformer的最大序列长度是100,那么这个1000长度的序列需要计算十次,并且每一次的计算都没法考虑到每一个段之间的关系,如果采用transformer-xl,首先取第一个段进行计算,然后把得到的结果的隐藏层的值进行缓存,第二个段计算的过程中,把缓存的值拼接起来再进行计算。该机制不但能保留长依赖关系还能加快训练,因为每一个前置片段都保留了下来,不需要再重新计算,在transformer-xl的论文中,经过试验其速度比transformer快了1800倍。
在xlnet中引入片段循环机制其实也很简单,只需要在计算KV的时候做简单的修改,其中![]() 表示的是缓存值。
表示的是缓存值。
?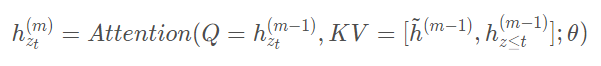
2.?相对位置编码
bert的position embedding采用的是绝对位置编码,但是绝对位置编码在transformer-xl中有一个致命的问题,因为没法区分到底是哪一个片段里的,这就导致了一些位置信息的损失,这里被替换为了transformer-xl中的相对位置编码。假设给定一对位置i与j,如果i和j是同一个片段里的那么我们令这个片段编码, 如果不在一个片段里则令这个片段编码为
,这个值是在训练的过程中得到的,也是用来计算attention weight时候用到的,在传统的transformer中attention weight =
,在引入相对位置编码后,首先要计算出
,,其中b bb也是一个需要训练得到的偏执量,最后把得到的
??与传统的transformer的weight相加从而得到最终的attention weight。
?
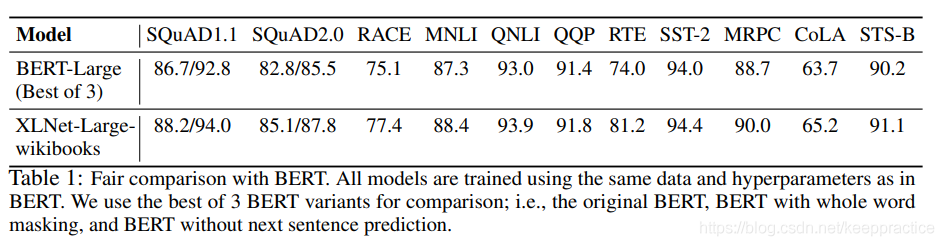
4. 实验结果