文章目录
一、Cost function/Loss function/Objective function
借用知乎上面 @WuchangI 的回答:
(1) 损失函数(loss function):针对单个样本,衡量单个样本的预测值
y
^
(
i
)
\hat{y}^{(i)}
y^?(i)与真实值
y
^
(
i
)
\hat{y}^{(i)}
y^?(i)之间的差距。
(2)代价函数/成本函数(Cost function):针对多个样本,衡量多个样本的预测值
∑
i
=
1
n
y
^
(
i
)
\sum_{i=1}^{n}\hat{y}^{(i)}
∑i=1n?y^?(i)与真实值
∑
i
=
1
n
y
(
i
)
\sum_{i=1}^{n}y^{(i)}
∑i=1n?y(i)的差距。
(3)目标函数(Objective function):梯度下降等优化算法就是针对目标函数来进行的。其实代价函数就可以是一种目标函数,换句话说,目标函数可以直接选用代价函数。但是,我们经常给代价函数添加一个正则项,最终作为模型的目标函数。
二、归一化(nomalization)、标准化(normalization)和正则化(regularization)
- 归一化和标准化英文翻译应该是相同的,但是根据其用途的不同去理解。
(1) 归一化一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。常见的映射范围有[0,1]和[-1,1],最常见的归一化方法是min-max归一化。
x
n
e
w
=
x
?
x
m
i
n
x
m
a
x
?
x
m
i
n
x_{new}=\frac{x-x_{min}}{x_{max-x_{min}}}
xnew?=xmax?xmin??x?xmin??
比如说,我们判断一个人身体状况是否健康,那么我们就会采集人体的很多指标,比如说:身高,体重,血压,白细胞数量等。一个人身高170cm,体重59kg,白细胞计数
7.50
×
1
0
9
/
L
7.50\times 10^9/L
7.50×109/L,衡量两个人的状况时,白细胞计数就会起到主导作用而遮盖住其他的特征,归一化后就不会有这样的问题。
(2) 标准化
- 主要有Z-Score标准化
x n e w = x ? μ σ x_{new}=\frac{x-\mu}{\sigma} xnew?=σx?μ?

上图则是一个散点序列的标准化过程:原图->减去均值->除以标准差。显而易见,变成了一个均值为 0 ,方差为 1 的分布,下图通过 Cost 函数让我们更好的理解标准化的作用。
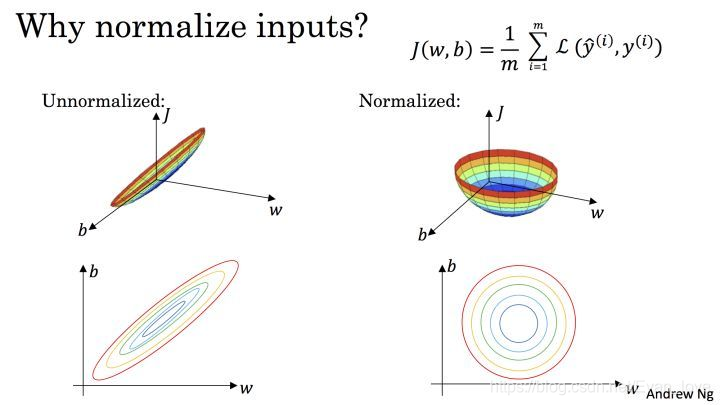
机器学习的目标无非就是不断优化损失函数,使其值最小。在上图中,
J
(
w
,
b
)
J(w,b)
J(w,b)就是我们要优化的目标函数,不难看出,标准化后可以更加容易得出最有参数
ω
\omega
ω和
b
b
b以及算出
J
(
ω
,
b
)
J(\omega, b)
J(ω,b)的最小值,从而达到加速收敛的效果。
(3) 正则化
正则化主要用于避免过拟合的产生和减少网络误差;正则化是指修改学习算法, 使其降低泛化误差而训练误差。
正则化一般具有如下形式:
J
(
ω
,
b
)
=
1
m
∑
i
=
1
m
L
(
f
(
x
)
,
y
)
+
λ
R
(
f
)
J(\omega, b)=\frac{1}{m}\sum_{i=1}^{m}L(f(x),y)+\lambda R(f)
J(ω,b)=m1?i=1∑m?L(f(x),y)+λR(f)
其中,第一项数经验风险,第二项是正则项,
λ
≥
0
\lambda \ge 0
λ≥0为调整两者之间关系的系数。常见的有正则项有 L1 正则 和 L2 正则 以及 Dropout ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。
三、 层归一化(layer normalization)和批归一化(batch normalization)
1 、batch normalization
引用知乎用户 @天雨粟 的回答。
在神经网络做标准化可以加速收敛,还有如下好处:
- 具有一定的正则化的效果
- 提高模型的泛化能力‘
- BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
- 允许网络使用饱和性激活函数(tanh,sigmoid等),缓解梯度消失的问题。
- BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定。
其原理是利用正则化减少内部相关变量分布的偏移,从而提高了算法的鲁棒性。
首先是关于Internal Covariate Shift现象。随着训练的进行,网络的参数也随着梯度下降在不停更新。一方面, 当底层网络中参数发生微弱变化时,由于每一层中的线性变换与非线性激活映射,这些微弱变化随着网络层数的加深而被放大;另一方面,参数的变化导致每一层的输入分布会发生改变,进而上层的网络需要不停地去适应这些分布变化,使得我们的模型训练变得困难的现象。
一个较为规范的定义:在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程称为Internal Covariate Shift。
-
什么是Internal Covariate Shift?
我们定义每一层的线性变换为
Z [ l ] = W [ l ] × i n p u t + b [ l ] Z^{[l]}=W^{[l]}\times input + b^{[l]} Z[l]=W[l]×input+b[l]其中 l l l代表层数;非线性变换为 A [ l ] = g [ l ] ( Z [ l ] ) A^{[l]}=g^{[l]}(Z^{[l]}) A[l]=g[l](Z[l]),其中 g [ l ] ( ? ) g^{[l]}(\cdot) g[l](?)为第 l l l层的激活函数。
随着梯度下降的进行,每一层的参数 W [ l ] W^{[l]} W[l]与 b [ l ] b^{[l]} b[l]都会被更新,那么 Z [ l ] Z^{[l]} Z[l]的分布也就发生了改变,进而 A [ l ] A^{[l]} A[l]也同样出现分布的改变。而 A [ l ] A^{[l]} A[l]作为第 l + 1 l+1 l+1层的输入,意味着 l + 1 l+1 l+1层就需要去不停适应这种数据分布的变化,这一过程~ -
Internal Covatiate Shift会带来的问题
①上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低。
② 网络的训练过程容易陷入梯度饱和区,减缓网络收敛速度。
随着模型训练的进行,参数 W [ l ] W^{[l]} W[l]会逐渐更新并变大,此时 Z [ l ] = W [ l ] A [ l ? 1 ] + b [ l ] Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]} Z[l]=W[l]A[l?1]+b[l]也会随之变大,并且 Z [ l ] Z^{[l]} Z[l]还受到更底层网络参数 W [ 1 ] , W [ 2 ] , . . . , W [ l ? 1 ] W^{[1]},W^{[2]},...,W^{[l-1]} W[1],W[2],...,W[l?1]的影响,随着网络层数的加深, Z [ l ] Z^{[l]} Z[l]很容易陷入梯度饱和区,此时梯度会变得很小甚至接近于0,参数的更新速度就会减慢,进而会放慢网络的收敛速度。
2、 BN

参数相关 -
l l l: 网络中的层标号
-
L L L:网络中的最后一层或总层数
-
d l d_l dl?:第 l l l层的维度,即神经元结点数
-
W [ l ] W^{[l]} W[l]: 第 l l l层的维度,即神经元结点数。
-
b [ l ] b^{[l]} b[l]: 第 l l l层的偏置向量, b [ l ] ∈ R d l × 1 b^{[l]} \in \mathbb{R}^{d_l\times 1} b[l]∈Rdl?×1
-
Z [ l ] Z^{[l]} Z[l]: 第 l l l层的线性计算结果, Z [ l ] = W [ l ] × i n p u t + b Z^{[l]}=W^{[l]}\times input + b Z[l]=W[l]×input+b
-
g [ l ] ( ? ) g^{[l]}(\cdot) g[l](?):第 l l l层的激活函数
-
A [ l ] A^{[l]} A[l]: 第 l l l层的非线性激活函数, A [ l ] = g [ l ] ( Z [ l ] ) A^{[l]}=g^{[l]}(Z^{[l]}) A[l]=g[l](Z[l])
样本相关 -
M M M: 训练样本的数量
-
N N N:训练样本的特征数
-
X X X: 训练样本集, X = [ x ( 1 ) , x ( 2 ) , . . . , x ( M ) ] X= [x^{(1)},x^{(2)},...,x^{(M)}] X=[x(1),x(2),...,x(M)], X ∈ R N × M X\in \mathbb{R}^{N\times M} X∈RN×M(这个X的一列是一个样本)
-
m m m: batch_size
-
χ ( i ) : 第 i 个 m i n i b a t c h \chi^{(i)}: 第i个minibatch χ(i):第i个minibatch的训练数据, X = [ χ ( 1 ) , χ ( 2 ) , χ ( 3 ) , . . . , χ ( k ) ] X={[\chi^{(1)},\chi^{(2)},\chi^{(3)},...,\chi^{(k)}]} X=[χ(1),χ(2),χ(3),...,χ(k)] 其中, χ ( i ) ∈ R N × m \chi ^{(i)}\in \mathbb{R}^{N\times m} χ(i)∈RN×m:
算法步骤:
设定对每个特征进行独立的normalization;考虑一个batch的训练,传入m个训练样本,并关注网络中的每一层,忽略上标 l l l。
Z ∈ R d j × m Z\in \mathbb{R}^{d_j\times m} Z∈Rdj?×m,关注当前层的第j个维度,也就是第j个神经元结点,则有 Z j ∈ R 1 × m Z_j\in \mathbb{R}^{1\times m} Zj?∈R1×m。对当前维度进行规范化:
μ j = 1 m ∑ i = 1 m Z j ( j ) \mu_j=\frac{1}{m}\sum_{i=1}^{m}Z_j^{(j)} μj?=m1?i=1∑m?Zj(j)?
σ j 2 = 1 m ∑ i = 1 m ( Z j ( i ) ? μ j ) 2 \sigma_j^2=\frac{1}{m}\sum_{i=1}^{m}(Z_{j}^{(i)}-\mu_j)^2 σj2?=m1?i=1∑m?(Zj(i)??μj?)2
Z ^ j = Z j ? μ j σ j 2 + ? \hat{Z}_j=\frac{Z_j-\mu_j}{\sqrt{\sigma_j^2+\epsilon}} Z^j?=σj2?+??Zj??μj??
下图只关注第 l l l层的计算结果,左边的矩阵是 Z [ l ] = W [ l ] A [ l ? 1 ] + b [ l ] Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]} Z[l]=W[l]A[l?1]+b[l]线性计算结果,还未进行激活函数的非线性变换。此时每一列是一个样本,图中可以看到共有8列,代表当前训练样本的batch中共有8个样本,每一行代表当前 l l l层神经元的一个节点,可以看到当前 l l l层共有4个神经元结点,即第 l l l层维度为4,可以看到每行的数据分布不同。
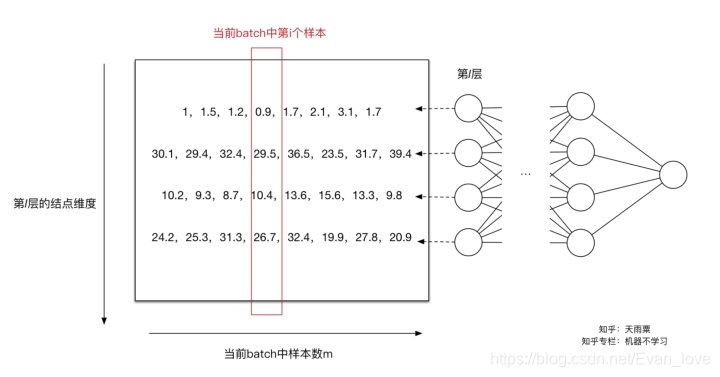
对于第一个神经元,我们求得 μ 1 = 1.65 , σ 1 2 = 0.44 \mu_1=1.65,\sigma_1^2=0.44 μ1?=1.65,σ12?=0.44,此时我们利用 μ 1 , σ 1 2 \mu_1,\sigma_1^2 μ1?,σ12?对第一行数据(第一个维度)进行normalization得到新的值![[公式]](https://img-blog.csdnimg.cn/42a992e695b544b7b90fb43450c83c5c.png)
。同理我们可以计算出其他输入维度归一化后的值。如下图:
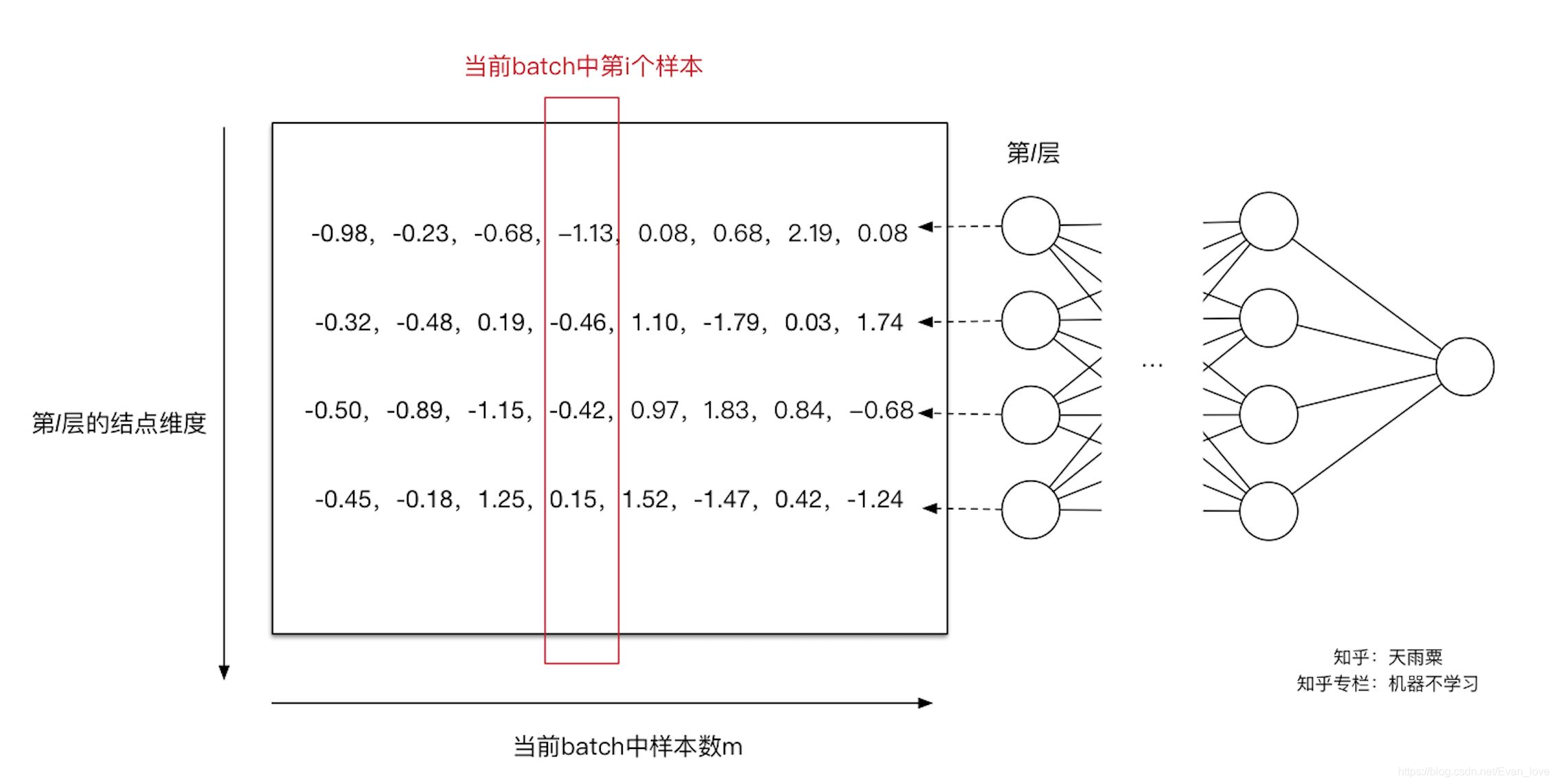
至此,我们可以使得第l层的输入每个特征的分布均值为0,方差为1.但是还会遇到数据表达能力缺失的问题,通过变换操作改变了原有数据信息表达,使得底层网络学习到的参数信息丢失,同时容易陷入非线性激活函数的线性区域。
于是,引入两个可学习的参数 γ \gamma γ和 β \beta β,可以一定程度上保证输入数据的表达能力。即:
Z ~ j = γ j Z ^ j + β j \tilde{Z}_j=\gamma_j \hat{Z}_j+\beta_j Z~j?=γj?Z^j?+βj?特别地,当 γ 2 = σ 2 , β = μ \gamma^2=\sigma^2,\beta=\mu γ2=σ2,β=μ时,可以实现等价变换并且保留了原始输入特征的分布信息。
在进行normalization的过程中,由于我们的规范化操作会对减去均值,因此,偏置项 b b b可以被忽略掉或可以被置为0,即 B N ( W u + b ) = B N ( W u ) BN(Wu+b)=BN(Wu) BN(Wu+b)=BN(Wu)。 -
总结
(是对同一维度(神经层中的单个神经元)进行归一化处理)
对于神经网络中的第 l l l层,我们有:
Z [ l ] = W [ l ] A [ l ? 1 ] + b [ l ] Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]} Z[l]=W[l]A[l?1]+b[l]
μ = 1 m ∑ i = 1 m Z [ l ] ( i ) \mu = \frac{1}{m}\sum_{i=1}^{m}Z^{[l](i)} μ=m1?i=1∑m?Z[l](i)
σ 2 = 1 m ∑ i = 1 m ( Z [ l ] ( i ) ? μ ) 2 \sigma^2 = \frac{1}{m}\sum_{i=1}^{m}(Z^{[l](i)}-\mu)^2 σ2=m1?i=1∑m?(Z[l](i)?μ)2
Z ~ [ l ] = γ ? Z [ l ] ? μ σ 2 + ? + β \tilde{Z}^{[l]}=\gamma \cdot \frac{Z^{[l]}-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta Z~[l]=γ?σ2+??Z[l]?μ?+β
A [ l ] = g [ l ] ( Z ~ [ l ] ) A^{[l]}=g^{[l]}(\tilde{Z}^{[l]}) A[l]=g[l](Z~[l]) -
测试阶段如何使用BN?
BN的每一层计算的 μ \mu μ和 σ 2 \sigma^2 σ2都是基于当前batch中的训练数据,但是在预测阶段,有可能只需要预测一个样本或很少的样本,没有像训练样本中那么多数据,此时 μ \mu μ和 σ 2 \sigma^2 σ2的计算一定是有偏估计,这个时候的计算方法如下:
利用BN训练好模型后,保留的每组mini-batch训练数据在网络中每一层的 μ b a t c h \mu_{batch} μbatch?与 σ b a t c h 2 \sigma^2_{batch} σbatch2?,此时我们使用整个样本的统计量来对Test数据进行归一化,具体来说是使用均值与方差的无偏估计:
μ t e s t = E ( m u b a t c h ) \mu_{test}=\mathbb{E}(mu_{batch}) μtest?=E(mubatch?)
σ t e s t 2 = m m ? 1 E ( σ b a t c h 2 ) \sigma_{test}^2=\frac{m}{m-1}\mathbb{E}(\sigma_{batch}^2) σtest2?=m?1m?E(σbatch2?)得到每个特征的均值与方差的无偏估计后,对test数据采用同样的normalization方法:
B N ( X t e s t = γ ? X t e s t ? μ t e s t σ t e s t 2 + ? + β BN(X_{test}=\gamma \cdot \frac{X_{test}-\mu_{test}}{\sqrt{\sigma_{test}^2}+\epsilon}+\beta BN(Xtest?=γ?σtest2??+?Xtest??μtest??+β
另外,除了采用整体样本的无偏估计外。吴恩达在Coursera上的Deep Learning课程指出可以对train阶段每个batch计算的mean/variance采用指数加权平均来得到test阶段mean/variance的估计。
3、层归一化
BN是对一个中间层的单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息。和BN不同的是,层归一化是对某一层的所有神经元进行归一化
假设某一层有M个神经元,那么改层输入 z l z^l zl为: { z 1 l , z 2 l , . . . , z M l } \{z_1^l,z_2^l,...,z_M^l \} {z1l?,z2l?,...,zMl?}
其均值为:
μ = 1 M ∑ m = 1 M z m l \mu=\frac{1}{M}\sum_{m=1}^{M}z_m^l μ=M1?m=1∑M?zml?
方差为:
σ
2
=
1
M
∑
m
=
1
M
(
z
m
l
?
μ
)
2
\sigma^2=\frac{1}{M}\sum_{m=1}^{M}(z_m^l-\mu)^2
σ2=M1?m=1∑M?(zml??μ)2
NOTE:批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化.
四、参考文献
[1] 知乎:Batch Normalization原理与实战
[2] 输入归一化、批量归一化(BN)与层归一化(LN)
[3] 深度学习中代价函数、损失函数和目标函数是一个概念吗?