1. Motivation
few shot 本身存在的意义:
-
In other words, we are unable to alleviate the situation of scarce cases by simply spend- ing more money on annotation even big data is accessible.
-
Therefore, the study of few-shot learning is an imperative and long-lasting task.
-
长尾分布在真实世界中也是一个的问题,数据缺少data scarcity。
-
long-tail distribution is an inherent characteristic of the real world.
-
Its performance is largely affected by the data scarcity of novel classes
FSOD(Few Shot Obejct Detection)中包含novel classes以及base classes,base classes是指包含大量标注信息的数据集,而novel classes则是只有少部分标注信息的数据集。
- In FSOD, there are base classes in which suffi-cient objects are annotated with bounding boxes and novel classes in which very few labeled objects are available.
FSOD的目标在于通过base classes的协助,来学习novel classes中优先的数据,从而在测试中能够检测出所有的novel objects。
- The few-shot detectors are expected to learn from limited data in novel classes with the aid of abundant data in base classes and to be able to detect all novel objects in a held-out testing set
目前大部分的方法采用meat-learning以及metric learning,然后将他们应用于全监督的检测器中。
- To achieve this, most recent few- shot detection methods adopt the ideas from meta-learning and metric learning for few-shot recognition and apply them to conventional detection frameworks, e.g. Faster R-CNN [35], YOLO [34].
在本文中,对于explicit shots自己implicit shots的定义:
其中explicit shots指的就是FSOD中novel classes的k-shot;而implicit shots则是只预训练模型的数据集。
- The explicit shots refer to the available labeled objects from the novel classes.
- In terms of implicit shots, initializing the backbone net- work with a model pretrained on a large-scale image clas- sification dataset is a common practice for training an ob- ject detector.
但是对于implicit shots来说,有可能大规模的预训练的数据集中的类别会和novel classes重复。因此,如果去除了explict shots,如图1所示,大部分的方法在同等的shot的情况下,expilict以及implicit shots相比,就会有性能的下降。
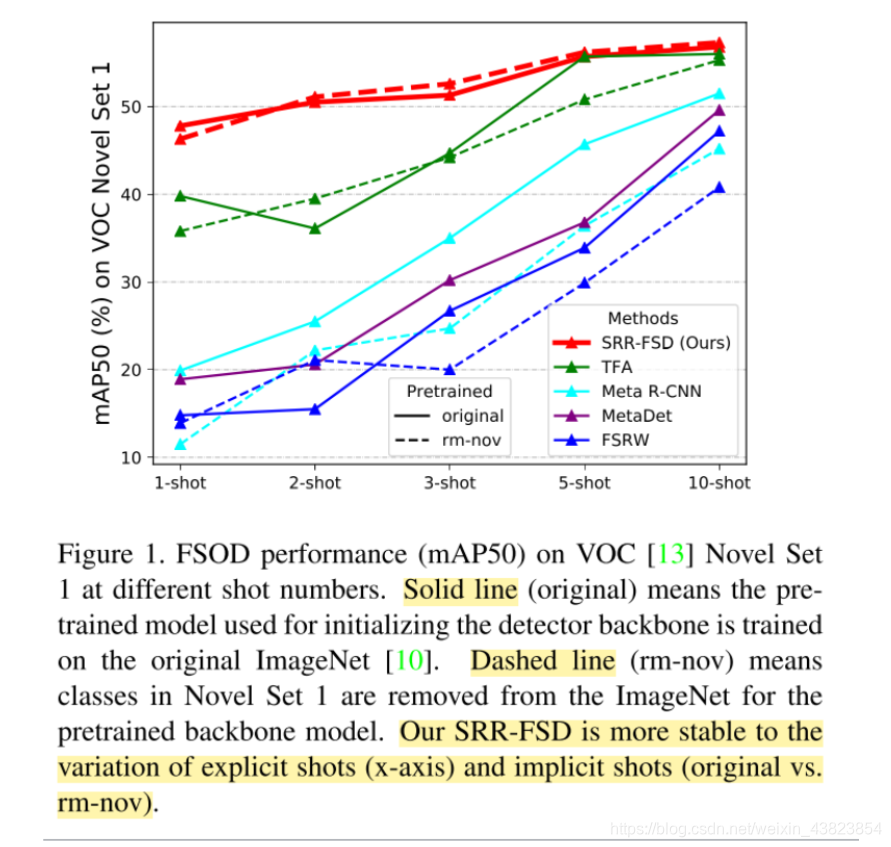
作者认为出现这个问题的原因在于视觉信息的独立。随着训练数据的减少,视觉信息会越来越局限。
- We believe the reason for shot sensitivity is due to exclusive dependence on the visual information.
- As a result, visual information becomes limited as image data becomes scarce.
但是作者指出,有一项是不变的常数,那就是base classes和novel classes中的semantic relation。
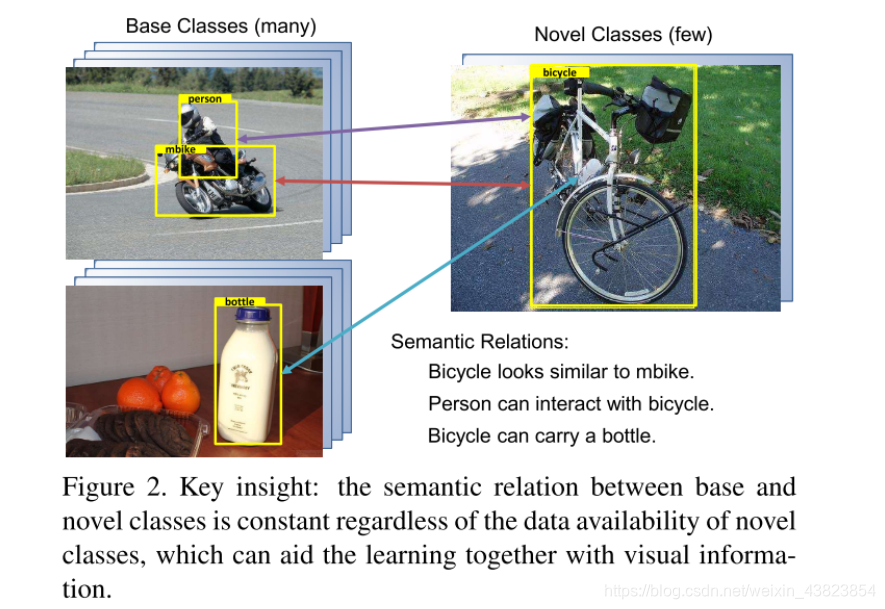
2. Contribution
-
To our knowledge, our work is the first to investigate semantic relation reasoning for the few-shot detection task and show its potential to improve a strong baseline.
-
Our SRR-FSD achieves stable performance w.r.t the shot variation, outperforming state-of-the-art FSOD methods under several existing settings especially when the novel class data is extremely limited.
-
We suggest a more realistic FSOD setting in which implicit shots of novel classes are removed from the classification dataset for the pretrained model, and show that our SRR-FSD can maintain a more steady performance compared to previous methods if using the new pretrained model.
3. Method
3.1 FSOD Preliminaries
base classes Cb, Db, Db中包含 x i , y i {x_i, y_i} xi?,yi?,xi是图片,yi是label+bounding box,而novel class set Dn 以及 Cn, C n ∩ C n = ? C_n \cap C_n = \emptyset Cn?∩Cn?=?。则是只包含了Cn中的label,以及对于每一个类别Cn,都只有K个object。
FSOD的目的在于通过学习Db来泛化Dn,从而能够见得 D b ∪ D n D_b \cup D_n Db?∪Dn?的测试集。
FSOD中有two stage的方法,首先在Db数据集集上训练,然后fine-tune到Dn和Dn并集的数据集上。当然,在第一个阶段,为了避免Db数据集的dominance,训练样本要保持一定平衡,第二阶段才会使用total images。
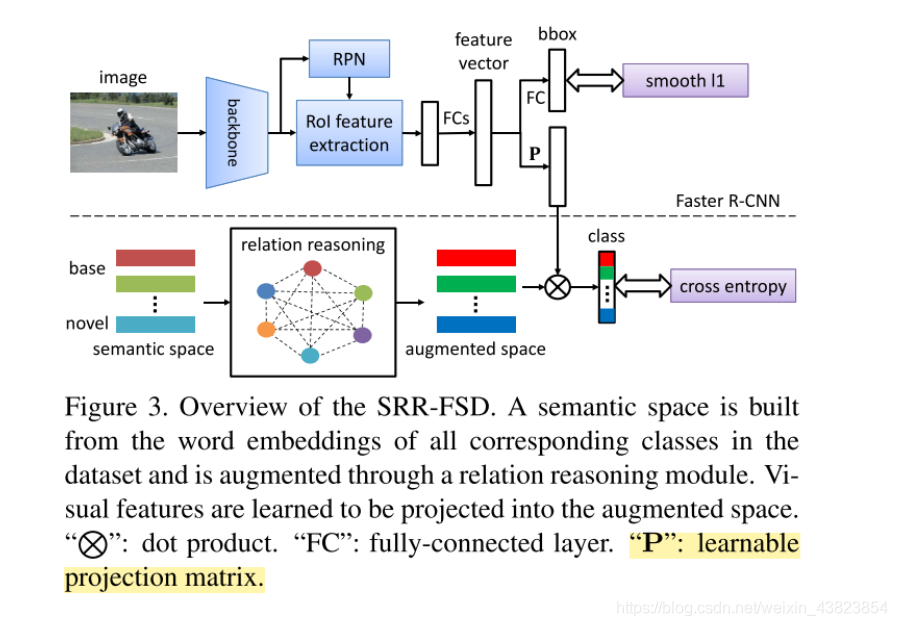
3.2 Semantic Space Projection
本文基于Faster R-CNN,传统的Faster R-CNN在分类分支经过FC得到的
v
∈
R
d
v \in R^d
v∈Rd, 和本文提出的learnable weight matrix
w
∈
R
N
×
d
w \in R^{N \times d}
w∈RN×d,相乘得到一个概率分布:
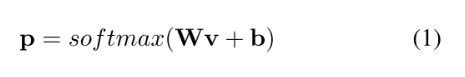
其中,N是classes的数量, b ∈ R N b \in R^N b∈RN。训练期间使用了交叉熵loss。
在本文中,为了同时学习物体的视觉和语义信息,本文首先构建了语义空间semantic space并且投影视觉特征v 到语义空间上。
首先使用 word embedding W e ∈ R N × d e W^e \in R^{N \times d_e} We∈RN×de?,其中 d e d_e de?代表word embedding的d-dimension ,其中N是包括背景类的classes 数量。检测器在分类分支上来学一个linear projection P ∈ R d e × d P \in R^{d_e \times d} P∈Rde?×d。
预测的概率分布由公式1转变为公式2:
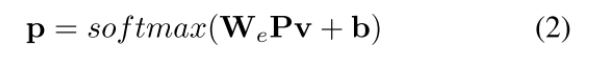
在训练中 W e W_e We? 是固定的,P是learnable variable。
Domain gap between vision and language
word embedding 对于FSOD来说有gap,原因在于不同于zero shot,zero shot中的都是unseen classes,没有来自于任何的已知的images,但是FSOD可以依赖原有图片以及embedding学习novel classes,因此novel class的多少则会影响泛化的方向以及性能。
因此,本文提出需要加强语义空间从而来减少vison以及language的gap。
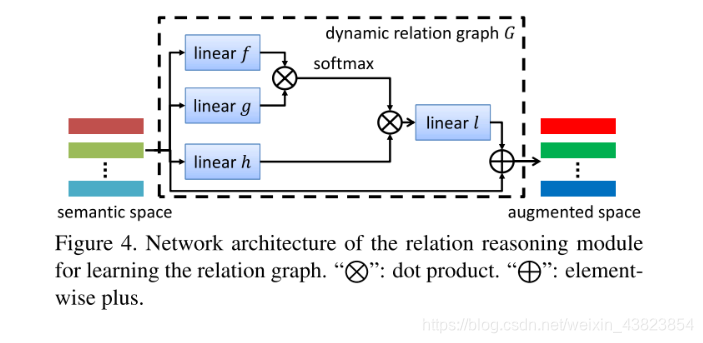
3.3. Relation Reasoning
本文认为,对于word embedding来说,vector的表示是N x d,但这类与类之间是没有联系的,独立的,因此本小节提出了一个knowledge graph G $G \in N \times N $来建模类别之间的关系,具体来说G在分类分支,通过一个图卷积的方法,来获得,因此公式2可以继续更新为公式3:
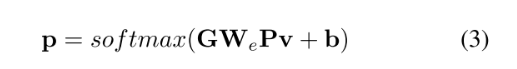
The heuristic definition of the knowledge graph
构造dynamic relation graph。
- Instead of predefining a knowledge graph based on heuristics, we propose to learn a dynamic relation graph driven by the data to model the relation reasoning between classes.
通过transformer来实现,relation reasoning module来实现,
- Inspired by the concept of the transformer, we implement the dynamic graph with the self- attention architecture [37] as shown in Figure 4