K均值聚类的核心目标是将给定的数据集划分为K个簇,并给出每个数据对应的簇中心点。()
正确答案: A ??你的答案: A (正确)
正确
其次,根据原文,这个图的纵坐标是该层的梯度向量的模,越大表示学习速率越快,即图上写的speed of learning。
因此,梯度消失导致前面的隐藏层比后面的隐藏层学习得慢,因此,最下面的曲线学习速率最慢,是第一层隐藏层,以此类推。
由于反向传播算法进入起始层,学习能力降低,这就是梯度消失。换言之,梯度消失是梯度在前向传播中逐渐减为0, 按照图标题所说, 四条曲线是4个隐藏层的学习曲线, 那么第一层梯度最高(损失函数曲线下降明显), 最后一层梯度几乎为零(损失函数曲线变成平直线). 所以D是第一层, A是最后一层。
?平方损失函数适合输出为连续的场景,而交叉熵损失则更适合二分类或多分类的场景
假设把整数关键字K Hash到有N个槽的散列表,以下哪些散列函数比较合适()
正确答案: B ??你的答案: B (正确)
H(K)=k/NH(k)=k mod NH(k)=1H(k)=(k+Random(N))mod N,其中Random(N)返回0到N-1的整数D是错误的,Random(N)返回0-N的整数,在查找的时候会出现问题,再次使用Random(N)不一定和上次存储产生的数字一样,这样子就会发生找不到的情况,而且题库还有道题与这个题目一样的,答案是B
Precision= tp / (tp + fp), Recall = tp / (tp + fn)链接:https://www.nowcoder.com/questionTerminal/5a4a4d5e20c14176bc51f0beaf59e0e9
来源:牛客网
?
已知表t
est(name)的记录如下,
tom
tom_green
tomly
lily
代码select?*?from?test?where?name?rlike?'tom.*'的结果有几条记录
-
1 -
2 -
3 -
0
rlike和like差不多,但它支持正则,.*表示匹配n个字符
批规范化(Batch Normalization)的好处都有啥?
让每一层的输入的范围都大致固定它将权重的归一化平均值和标准差【是对数据进行归一化,而不是权重】它是一种非常有效的反向传播(BP)方法这些均不是一幅数字图像是()
正确答案: B ??你的答案: C (错误)
一个观测系统一个有许多像素排列而成的实体一个2-D数组中的元素一个3-D空间的场景容斥原理(先容后斥):至少甲+至少 乙 + 至少 丙-(至少甲乙+至少甲丙+至少乙丙 )+至少甲 乙丙 = 50-X
40+36+30-(28+26+24)+20=50-X
X = 2;
现在在hadoop集群当中的配置文件中有这么两个配置,请问假如集群当中有一个节点宕机,主节点namenode需要多长时间才能感知到?
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
26秒34秒30秒20秒dfs.heartbeat.interval意思是:datanode会按照此间隙(单位是s)向namenode发送心跳,默认发送10次。
heartbeat.recheck.interval意思是:namenode按照此间隙(单位是ms)检查datanode的相关进程,默认检查2次
HDFS集群的datnaode掉线超时时长的计算公式为: timeout = 10 * dfs.heartbeat.interval + 2 * heartbeat.recheck.interval,不过heartbeat.recheck.interval的单位是ms,dfs.heartbeat.interval的单位是s? (10*3)s+(2*2000)ms=34s
基于统计的分词方法为()
正确答案: D ??你的答案: A (错误)
正向最大匹配法逆向最大匹配法最少切分条件随机场1)正向最大匹配法(由左到右的方向);?
2)逆向最大匹配法(由右到左的方向);?
3)最少切分(使每一句中切出的词数最小)。?
以上三种是机械分词方法:
条件随机域(场)(conditional random fields,简称 CRF,或CRFs),是一种判别式概率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
条件随机场(CRF)由Lafferty等人于2001年提出,结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,基于统计学,可以作为一种分词方法
目前的分词方法归纳起来有3 类:
第一类是基于语法和规则的分词法。其基本思想就是在分词的同时进行句法、语义分析, 利用句法信息和语义信息来进行词性标注, 以解决分词歧义现象。因为现有的语法知识、句法规则十分笼统、复杂, 基于语法和规则的分词法所能达到的精确度远远还不能令人满意, 目前这种分词系统还处在试验阶段。
第二类是机械式分词法(即基于词典)。机械分词的原理是将文档中的字符串与词典中的词条进行逐一匹配, 如果词典中找到某个字符串, 则匹配成功, 可以切分, 否则不予切分。基于词典的机械分词法, 实现简单, 实用性强, 但机械分词法的最大的缺点就是词典的完备性不能得到保证。据统计, 用一个含有70 000 个词的词典去切分含有15 000 个词的语料库, 仍然有30% 以上的词条没有被分出来, 也就是说有4500 个词没有在词典中登录。
第三类是基于统计的方法。基于统计的分词法的基本原理是根据字符串在语料库中出现的统计频率来决定其是否构成词。词是字的组合, 相邻的字同时出现的次数越多, 就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映它们成为词的可信度。
最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描,这是基于词典分词的方法
1.正向最大匹配法?
2.逆向最大匹配法
3.最少切分法:使每一句中切出的词数最小,这也是基于词典分词的方法
条件随机场是一个基于统计的序列标记和分割的方法,属于基于统计的分词方法范畴。它定义了整个标签序列的联合概率,各状态是非独立的,彼此之间可以交互,因此可以更好地模拟现实世界的数据.
下列哪个不属于CRF模型对于HMM和MEMM模型的优势( )
正确答案: B ??你的答案: D (错误)
特征灵活速度快可容纳较多上下文信息全局最优CRF 的优点:特征灵活,可以容纳较多的上下文信息,能够做到全局最优
CRF 的缺点:速度慢
链接:https://www.nowcoder.com/questionTerminal/88228d860ec54e0cba0abb528b797767
来源:牛客网
?
Apriori算法在机器学习和数据挖掘中被广泛使用,已知有1000名球迷看奥运会,分为AB两队,每队各500人,其中A队有500人看了乒乓球比赛,同时又有450人看了羽毛球比赛;B队有450人看了羽毛球比赛,如下表所示:
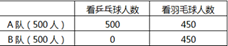
那么 乒乓球→羽毛球的支持度、置信度和提升度分别是( )
-
0.45 0.9 1 -
0.1 0.1 1 -
0.45 0.1 0 -
0.1 0.45 0

在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计()
正确答案: D ??你的答案: D (正确)
EM算法维特比算法前向后向算法极大似然估计EM算法: 只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计
前向后向:用来算概率
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数
故应选D
(参考李航博士《统计学习方法》)
书架上有编号为1-19的19本书,从中拿5本,问5本编号都不相邻的拿法有多少种?
正确答案: B ??你的答案: B (正确)
20023003知识点:相邻问题用隔板法+逆向思维
详细说明:考虑要吧5本新书放回14本旧书中,新书不可以相邻,显然用隔板发,15个空位,选择5个位插入即可,有C ? 15 ? 5 ? 种方法
半调输出技术可以()
正确答案: B ??你的答案: C (错误)
改善图像的空间分辨率改善图像的幅度分辨率利用抖动技术实现消除虚假轮廓现象半调输出技术牺牲空间分辨率以提高幅度分辨率。
解决隐马模型中预测问题的算法是?
前向算法后向算法Baum-Welch算法维特比算法评估问题:前向后向算法,是概率计算方式,即给定一个模型,通过求某固定观测序列的概率评估模型好坏选出最优模型;
学习问题:Baum-Welch算法,模型参数估计,主要通过EM无监督(只有观测序列,对数似然评估)方法训练;
解码问题:维特比算法,序列预测,给定模型和输出序列,求最可能产生该输出序列的输入状态序列。
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量,下面关于召回率描述正确的是( )
正确答案: C ??你的答案: A (错误)
衡量的是提取出的正确信息多少是准确的召回率 = 提取出的正确信息条数 / 提取出的信息条数召回率 = 提取出的正确信息条数 / 样本中相关的信息条数召回率 = 提取出的正确信息条数 / 样本中总的信息条数下列关于分类器的说法中不正确的是()
-
SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,属于结构风险最小化 -
Naive Bayes是一种特殊的Bayes分类器,其一个假定是每个变量相互条件独立。 -
Xgboost是一种优秀的集成算法,其优点包括速度快、对异常值不敏感、支持自定义损失函数等等 -
随机森林中列采样的过程保证了随机性,所以就算不剪枝,也不容易出现过拟合。
随机森林不需要剪枝,因为本类就很大方差,防止过拟合
GBDT核心在于每一棵树学的是之前所有树的结论和的残差,残差是一个加预测值后能得到真实值得累加量,xgboost和GBDT差不多,不过还支持线性分类器
xgboost可以自定损失函数,速度很快,但是对异常值很敏感
从使用的主要技术上看,可以把分类方法归结为哪几种类型?
正确答案: A B C D ??你的答案: B C D (错误)
规则归纳方法贝叶斯分类方法决策树分类方法基于距离的分类方法从使用技术上来分,可以分为四种类型:基于距离的分类方法、决策树分类方法、贝叶斯分类方法和规则归纳方法。基于距离的分类方法主要有最邻近方法;决策树方法有ID3、C4.5、VFDT等;贝叶斯方法包括朴素贝叶斯方法和EM算法;规则归纳方法包括AQ算法、CN2算法和FOIL算法。
假设我们有一个如下图所示的隐藏层。隐藏层在这个网络中起到了一定的降纬作用。假如现在我们用另一种维度下降的方法,比如说主成分分析法(PCA)来替代这个隐藏层
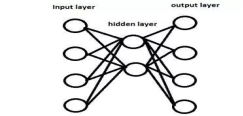
那么,这两者的输出效果是一样的吗?
正确答案: B ??你的答案: B (正确)
是否PCA降维的特点在于使用矩阵分解求特征值的方式,提取的是数据分布方差比较大的方向,提取的是主要成分;hidden layer主要是点乘+非线性变换,目的是特征的提取,转换
整数240有几个因数()
正确答案: C ??你的答案: C (正确)
36542028
先将240因式分解,得到
240=(2^4)*(3^1)*(5^1),
在选择因子的时候可采用x=2^m*3^n*5^k;
而m,n,k各有5(4+1),2(1+1),2(1+1)种选法,且相互独立,故一共有5*2*2=20个因子。
Zookeeper 对节点的 watch 监听通知是永久的吗?
正确答案: B ??你的答案: B (正确)
是不是zookeeper的监听是暂时的,每次监听发生变化后,都得重新进行监听。
一个watch事件是一个一次性的触发器,当被设置了watch的数据发生了改变的时候,服务器会讲这个改变发送给客户端。如果是永久监听,那么数据的频繁变动会使得服务器压力变大
下面关于支持向量机(SVM)的描述错误的是( )?
正确答案: C ??你的答案: 空 (错误)
是一种监督式学习的方法可用于多分类的问题是一种生成式模型支持非线性的核函数判别式模型(Discriminative Model)是直接对条件概率p(y|x;θ)建模。
常见的判别式模型有 线性回归模型、线性判别分析、支持向量机SVM、神经网络等。
生成式模型(Generative Model)则会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得p(yi|x),然后选取使得p(yi|x)最大的yi,
常见的生成式模型有 隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等。
判别式模型:
线性回归,逻辑回归,线性判别分析,SVM,CART,神经网络,高斯过程,条件随机场
生成式模型:
朴素贝叶斯,K近邻,混合高斯模型
下面哪项操作能实现跟神经网络中Dropout的类似效果?
正确答案: B ??你的答案: D (错误)
BoostingBaggingStackingMappingAI面试必备/深度学习100问1-50题答案解析
典型的神经网络其训练流程是将输入通过网络进行正向传导,然后将误差进行反向传播,Dropout就是针对这一过程之中,随机地删除隐藏层的部分单元,进行上述过程。步骤为:1)随机删除网络中的一些隐藏神经元,保持输入输出神经元不变;2)将输入通过修改后的网络进行前向传播,然后将误差通过修改后的网络进行反向传播;3)对于另外一批的训练样本,重复上述操作。他的作为从Hinton的原文以及后续的大量实验论证发现,dropout可以比较有效地减轻过拟合的发生,一定程度上达到了正则化的效果。A:Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。B:bagging同样是弱分类器组合的思路,它首先随机地抽取训练集(training set),以之为基础训练多个弱分类器。然后通过取平均,或者投票(voting)的方式决定最终的分类结果。因为它随机选取训练集的特点,Bagging可以一定程度上避免过渡拟合(overfit)。C:stacking:它所做的是在多个分类器的结果上,再套一个新的分类器。这个新的分类器就基于弱分类器的分析结果,加上训练标签(training label)进行训练。一般这最后一层用的是LR。D:Sammon Mapping降维算法。
- Bagging:独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果;
- Boosting(增强集成学习):集成多个模型,每个模型都在尝试增强(Boosting)整体的效果;
- Stacking(堆叠):集成 k 个模型,得到 k 个预测结果,将 k 个预测结果再传给一个新的算法,得到的结果为集成系统最终的预测结果;
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
5)bagging是减少variance,而boosting是减少bias
假设你需要调整超参数来最小化代价函数(cost function),会使用下列哪项技术?
正确答案: D ??你的答案: D (正确)
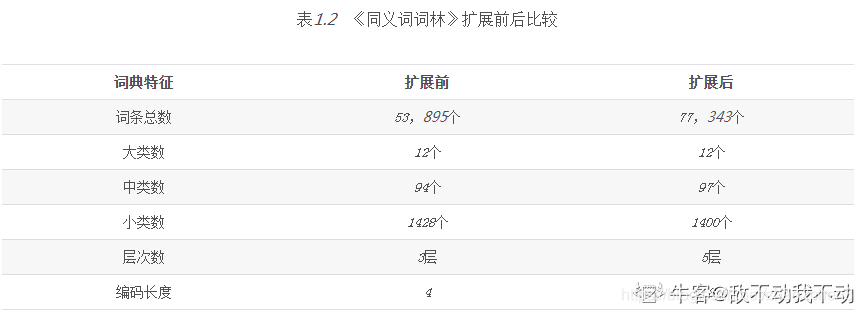
穷举搜索随机搜索Bayesian优化都可以《同义词词林》的词类分类体系中,将词分为大类、种类、小类,下列说法正确的是()
正确答案: D ??你的答案: D (正确)
大类以小写字母表示小类以大写字母表示中类以阿拉伯数字表示中类有94个大类用大写字母表示,中类用小写字母表示,小类用阿拉伯数字表示。
?京东仓库中对某种商品进行合格性检验,已知这种商品的不合格率为0.001,即1000件商品中会有一件次品。现有现有一种快速检验商品方法,它的准确率是0.99,即在商品确实是次品的情况下,它有99%的可能抽检显示红色。它的误报率是5%,即在商品不是次品情况下,它有5%的可能抽检显示红色。现有有一件商品检验结果为红色,请问这件商品是次品的可能性有多大?
已知 : P(次品)= 0.001, P(红|次品)= 0.99, P(红|正品) = 0.05
则,
P(正品)=1 - 0.001 = 0.999,
P(红色且次品) = P(红|次品) x P(次品)
P(红色且正品) = P(红|正品) x P(正品)
P(红) = P(红色且次品) + P(红色且正品)=0.99x0.001 + 0.05x0.999=0.05094
根据贝叶斯公式,
P(次品|红)= P(红|次品) x P(次品) / P(红)= 0.99 x 0.001 / 0.50094 = 0.02
图像中虚假轮廓的出现就其本质而言是由于()
正确答案: A ??你的答案: B (错误)
图像的灰度级数不够多造成的图像的空间分辨率不够高造成图像的灰度级数过多造成的图像的空间分辨率过高造成

五个球从盒子里拿出来,打乱顺序放回去,均不在原位的排列数是多少()
正确答案: B ??你的答案: B (正确)
364432错排公式:
D(n) = (n-1) * ( D(n-1) + D(n-2) ),n>=3
且:D(1) = 0 , D(2) = 1?
已知中国人的血型分布约为A型:30%,B型:20%,O型:40%,AB型:10%,则任选一批中国人作为用户调研对象,希望他们中至少有一个是B型血的可能性不低于90%,那么最少需要选多少人?

下面的颜色空间表示中,能较好的分离图像亮度和色度信息的是( )?
正确答案: A ??你的答案: 空 (错误)
LabRGBHSVCMY- lab的l为亮度,ab为两种不同的色度,前者是明度通道,后者是色彩通道,可以分离色度和亮度。
- RGB基于颜色的加法混色原理,从黑色不断叠加Red,Green,Blue的颜色,最终可以得到白色光。
- CMY颜色空间是基于光反射定义的(CMY对应了绘画中的三原色:Cyan,Magenta,Yellow),是一种基于颜色减法混色原理的颜色模型。
- HSV、HSL两个颜色空间都是从人视觉的直观反映而提出来的(H是色调,S是饱和度,I是强度)。
硬币游戏:连续扔硬币,直到 某一人获胜,A获胜条件是先正后反,B获胜是出现连续两次反面,问AB游戏时A获胜概率是?
F 考虑先抛两次,共4种情况:正正,正反,反正,反反;
正反 A胜,反反 B胜;
正正 情况下,接着抛,如果是正,游戏继续;如果是反,A胜。所以这种情况下最终也是A胜。
反正 情况下也是类似的,最终也是A胜。
所以A得胜率是3/4.
链接:https://www.nowcoder.com/questionTerminal/20ea182d3b824467bac9b273aec54ff0
来源:牛客网
?
现有一 1920*1080 的单通道图像,每个像素用 float32 存储,对其进行 4 个 3*3 核的卷积(无 padding),卷积核如下:
| 1 2 3 |
|
若原图像由于量化问题出现了 100 个 INFINITY,而其他的值都在(-1,1)区间内,则卷积的结果至少有多少个 NaN?()
-
256 -
284 -
296 -
324
四个角落,每个角落25个inf对称着贴着边,那么第一个filter的map无nan,第二个25+25+21+21,第三个同第二个,第四个25+25+25+25,共100+92+92
你有一个3X3X3的立方体。你现在在正面左上的顶点,需要移动到对角线的背面右下的顶点中。每次移动不限距离,但只能从前至后、从左至右、从上至下运动,即不允许斜向或后退。有多少种方法?
总共需要走9步,其中选择三步为从前至后,三步为 从左至右、三步为从上至下。即为C(9,3)*C(6,3)
假如你用logistic Regression 算法去预测用户在网上的购买项目,然而,当你在新的用户集上验证你的假设时,你发现预测值有很大的偏差。并且你的假设在训练集上表现也很差,下面那些步骤你应该采纳,选择出正确的选项()
正确答案: A B ??你的答案: A B (正确)
尝试着减小正则项 λ尝试增加交叉特征减小样本量尝试更小的测试集或者特征欠拟合:训练误差和验证误差都很大。
解决:增加特征项;增加模型复杂度,如使用核函数;减小正则化系数;集成学习方法。
欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况;
过拟合是指模型在训练集上表现很好,到了验证和测试阶段就大不如意了,即模型的泛化能力很差
解决过拟合(高方差)的方法
1. 增加训练数据数
??? 发生过拟合最常见的现象就是数据量太少而模型太复杂
??? 过拟合是由于模型学习到了数据的一些噪声特征导致,增加训练数据的量能够减少噪声的影响,让模型更多地学习数据的一般特征
??? 增加数据量有时可能不是那么容易,需要花费一定的时间和精力去搜集处理数据
??? 利用现有数据进行扩充或许也是一个好办法。例如在图像识别中,如果没有足够的图片训练,可以把已有的图片进行旋转,拉伸,镜像,对称等,这样就可以把数据量扩大好几倍而不需要额外补充数据
??? 注意保证训练数据的分布和测试数据的分布要保持一致,二者要是分布完全不同,那模型预测真可谓是对牛弹琴了
2. 使用正则化约束
??? 在代价函数后面添加正则化项,可以避免训练出来的参数过大从而使模型过拟合。使用正则化缓解过拟合的手段广泛应用,不论是在线性回归还是在神经网络的梯度下降计算过程中,都应用到了正则化的方法。常用的正则化有l1正则和l2正则,具体使用哪个视具体情况而定,一般l2正则应用比较多
3. 减少特征数
??? 欠拟合需要增加特征数,那么过拟合自然就要减少特征数。去除那些非共性特征,可以提高模型的泛化能力
4. 调整参数和超参数
??? 不论什么情况,调参是必须的
5. 降低模型的复杂度
??? 欠拟合要增加模型的复杂度,那么过拟合正好反过来
6. 使用Dropout
??? 这一方法只适用于神经网络中,即按一定的比例去除隐藏层的神经单元,使神经网络的结构简单化
7. 提前结束训练
??? 即early stopping,在模型迭代训练时候记录训练精度(或损失)和验证精度(或损失),倘若模型训练的效果不再提高,比如训练误差一直在降低但是验证误差却不再降低甚至上升,这时候便可以结束模型训练了
以下哪些学科和数据挖掘有密切联系()
正确答案: C D ??你的答案: C D (正确)
计算机组成原理矿产挖掘统计人工智能Zookeeper 都有哪些功能
正确答案: A B C D ??你的答案: A B (错误)
集群管理主节点选举分布式锁命名服务zookeeper提供的服务主要有以下几点:
1.统一命名服务:
? ? 在分布式环境下,经常需要对应用/服务进行统一命名,便于识别
2.统一配置管理
? ? (1)分布式环境下,配置文件同步非常常见
????? ? a.一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群
????? ? b.对配置文件修改后,希望能够快速同步到各个节点上
? ? (2)配置管理可以交由zookeeper实现
????? ? a.可将配置信息写入zookeeper上的一个Znode
????? ? b.各个客户端服务器监听这个Znode
????? ? c.一旦Znode中的数据被修改,Zookeeper将通知各个客户端服务器
3.统一集群管理
? ? (1)分布式环境中,实时掌握每个节点的状态是必要的
????? ? a.可根据节点实时状态做出一些调整
? ? (2)Zookeeper可以实现实时监控节点状态变化
????? ? a.可将节点信息写入Zookeeper上的一个Znode
????? ? b.监听这个Znode可获取它的实时状态变化
4.服务器节点动态上下线
? ? 客户端实时洞察到服务器上下线的变化
5.软负载均衡
? ? 在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器处理最新的客户端请求
关于Word2vec,下列哪些说法是正确的()
正确答案: A B C D E ??你的答案: B E (错误)
Word2vec是无监督学习Word2vec利用当前特征词的上下文信息实现词向量编码,是语言模型的副产品Word2vec能够表示词汇之间的语义相关性Word2vec没有使用完全的深度神经网络模型Word2vec可以采用负采样的方式来节省计算开销在统计模式识分类问题中,当先验概率未知时,可以使用()?
正确答案: B C ??你的答案: B C D (错误)
最小损失准则N-P判决最小最大损失准则最小误判概率准则在贝叶斯决策中,对于先验概率p(y),分为已知和未知两种情况。
1. p(y)已知,直接使用贝叶斯公式求后验概率即可;
2. p(y)未知,可以使用聂曼-皮尔逊决策(N-P决策)来计算决策面。
而最大最小损失规则主要就是使用解决最小损失规则时先验概率未知或难以计算的问题的
下列层次聚类算法中,哪些更适合处理大数据?(? ? ? )
正确答案: A B C D ??你的答案: B D (错误)
CURE算法ROCK算法Chameleon算法BIRCH算法
关于线性回归的描述,以下正确的有:
正确答案: B C E ??你的答案: A B F (错误)
基本假设包括随机干扰项是均值为0,方差为1的标准正态分布基本假设包括随机干扰项是均值为0的同方差正态分布在违背基本假设时,普通最小二乘法估计量不再是最佳线性无偏估计量在违背基本假设时,模型不再可以估计可以用DW检验残差是否存在序列相关性多重共线性会使得参数估计值方差减小一元线性回归的基本假设有
1、随机误差项是一个期望值或平均值为0的随机变量;
2、对于解释变量的所有观测值,随机误差项有相同的方差;
3、随机误差项彼此不相关;
4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
6、随机误差项服从正态分布
违背基本假设的计量经济学模型还是可以估计的,只是不能使用普通最小二乘法进行估计。
当存在异方差时,普通最小二乘法估计存在以下问题: 参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
杜宾-瓦特森(DW)检验,计量经济,统计分析中常用的一种检验序列一阶 自相关 最常用的方法。
所谓多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。影响
(1)完全共线性下参数估计量不存在
(2)近似共线性下OLS估计量非有效
多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF)
(3)参数估计量经济含义不合理
(4)变量的显著性检验失去意义,可能将重要的解释变量排除在模型之外
(5)模型的预测功能失效。变大的方差容易使区间预测的“区间”变大,使预测失去意义。
关于正态分布,下列说法错误的是:
正确答案: C ??你的答案: C (正确)
正态分布具有集中性和对称性
正态分布的均值和方差能够决定正态分布的位置和形态
正态分布的偏度为0,峰度为1[正态分布的偏度和峰度均为0.]
标准正态分布的均值为0,方差为1
链接:https://www.nowcoder.com/questionTerminal/09a31793e4394dfa9bf5d0f0fff6cc71
来源:牛客网
?
下列的哪种方法可以用来降低深度学习模型的过拟合问题?
1 增加更多的数据
2 使用数据扩增技术(data augmentation)
3 使用归纳性更好的架构
4 正规化数据
5 降低架构的复杂度
-
1 4 5
-
1 2 3
-
1 3 4 5
-
所有项目都有用
防止过拟合的几种方法
- 引入正则化
- Dropout
- 提前终止训练
- 增加样本量
在下面哪种情况下,一阶梯度下降不一定正确工作(可能会卡住)?
正确答案: B ??你的答案: B (正确)
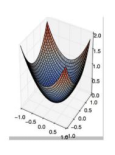
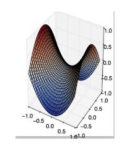
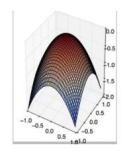
B对于深度学习模型的优化来说,鞍点比局部极大值点或者极小值点带来的问题更加严重