机器学习用来干嘛?
在李宏毅老师的描述中,机器学习其实就是在为很多问题寻找一个方程式从而得到一个机器预测的答案。而这些方程式中又对应两大类不同的问题。
第一种:
Regression(回归): 这一类的函数最后会输出一个scalar(标量)。
这里有一个非常简单的例子:
在上面这个例子中,我们的任务是预测明天的PM2.5的值,而我们现在手头有的数据是今天PM2.5的值,今天的温度还有其他的一些影响因素。我们将已有的数据输入到函数f中,而函数f会输出一个标量,这个标量就是对明天PM2.5的预测值。
第二种
Classification(分类): 在这一类问题里面,我们通常都是让我们的计算机去做一道选择题。
再举一个例子:
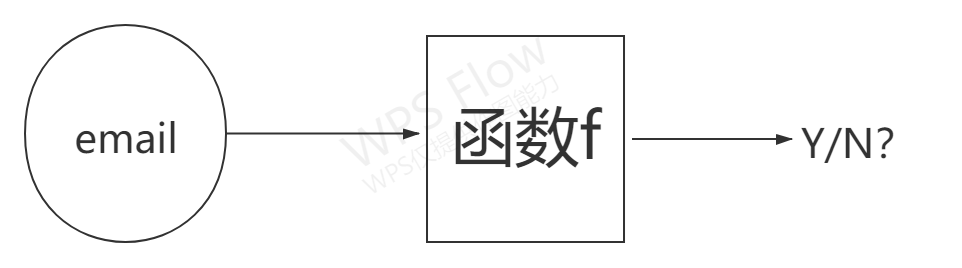
在上面这个例子里,我们这个f的作用是,当我们收到一封邮件时,我们的机器可以自己帮我们判别这是否是一篇垃圾邮件。
可能我们大部人对机器学习处理问题类别的了解也就止于此,但是其实在Regression和classification两大类问题之外,机器学习还会处理到一种非常折磨的问题,这类问题的名字叫做――Structured Learning(结构性学习)。在结构性学习中,我们通常会让我们的机器去做一些我们一直是由人类在做的事,比如去写一篇演讲稿,或者直接让它帮我写完这篇文章。所以如果我们用一个更加拟人的方法来修饰结构性学习,其实我们就是让机器去学会创造,这可是一件非常了不起的事情了。
说到这里,让我们再次回归到我们一开始给机器学习的定义,我们是通过让机器寻找一个方程式来获得我们想要的结果,那么究竟怎么找我们要的这个方程呢?
一般来说,找到这个方程机器会通过三个大的步骤,这里我会拿李宏毅老师课上所举的Youtube播放量的例子来进行讲解。

首先我们的第一步就是要先根据已有的数据去设出我们的函数,那么我们要怎么去设呢,答案是便随设。不过因为我们也是第一次设,所以我们可以先直接设出一个最简单的线性函数,在这个函数中,X1代表的是前一天的视频播放总量(我们目前这个函数的功能就是用前一天的播放量来预测后一天的播放量),而w我们叫做权重(weight),为什么要乘上一个w呢,因为两天的播放量总不会完全一样吧,总归是有些出入,所以我们这里乘上一个w,那么可能我们在乘上w之后还是有些出入,那么为了预测更接近实际,我们再加上一个b,b叫做偏置(bias)。这样一个最简单的预测函数我们就设好了,那么接下来我们就可以用他来对第二天的播放量进行预测了。这也就到了我们的第二步。
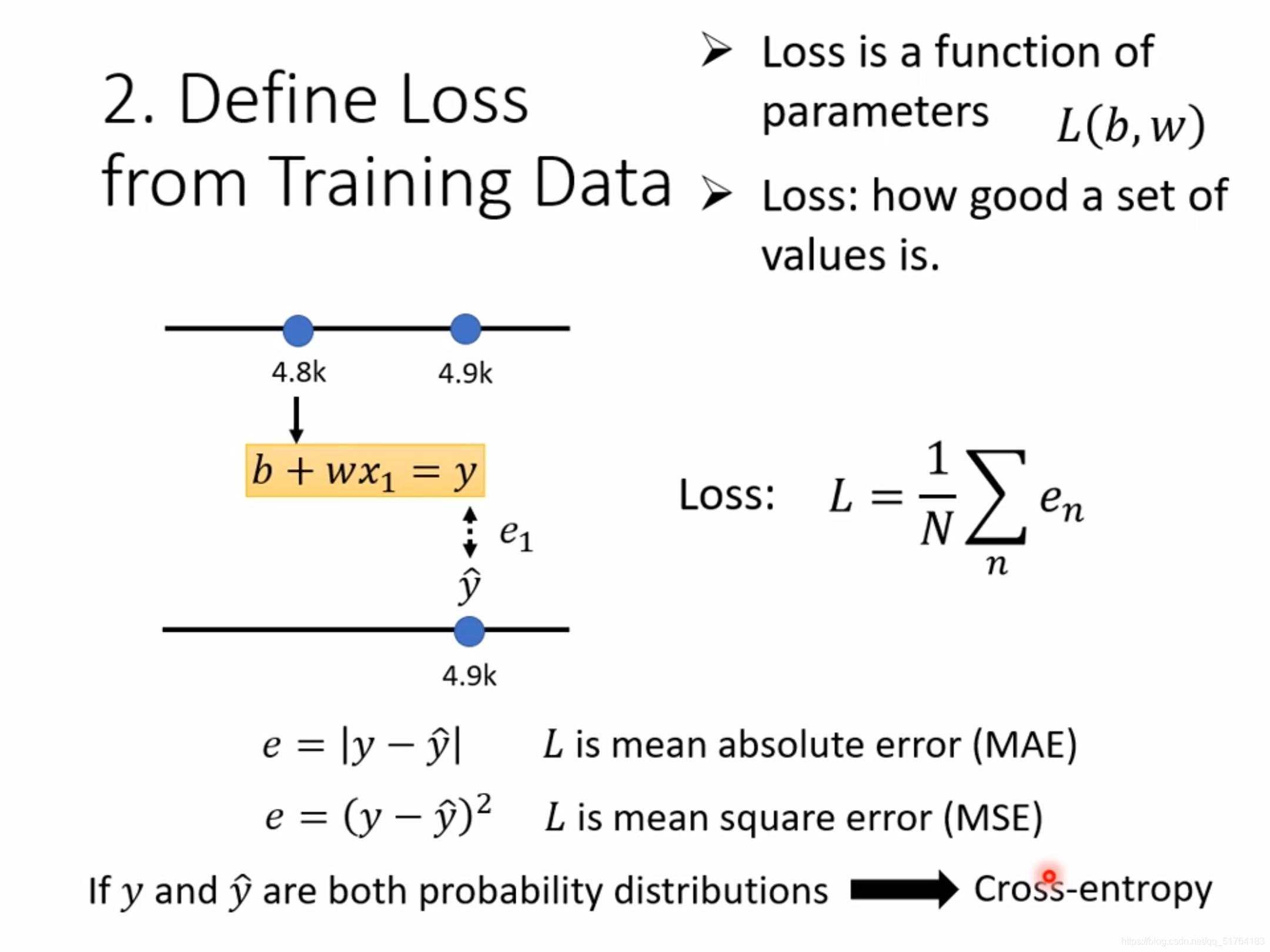
在第二步中,我们将前一天的数据4.8k(这里k代表的1000的意思,并不是未知数的意思)代入函数中,之后函数会计算出一个y值(这里李宏毅老师的课件中好像有点问题,我们的预测值应该是y-hat,而实际值应该是y,在他的课件中这两个好像弄反了,大家理解就行,文章后半部分就直接按照李宏毅的课件为准),而这个y值和我们实际上第二天的播放量y-hat之前肯定是会有一个误差的,如果预测的非常准那误差就为0。那如果我们现在是用这个函数去预测了一整个月的播放量,那如果我们把每天的预测值和真实值之前做一个差,再求和,我们就得到这一整个月的误差,我们把这个误差叫做损失(loss),而损失这个指标就是用来判断我们设出来的这个模型好不好的,损失越大说明函数的预测能力越差,越小则说明函数预测能力越强。
那么到这里我们就会有个问题了,如果我设出来的模型和真实值差了十万八千里怎么办?这里就到了我们的第三步,优化(Optimization)。那么我们该对谁优化,正如我们所说,X1代表的是前一天的播放量,这是不能改变的,那我们自然就要对我们的权重和偏置进行优化。
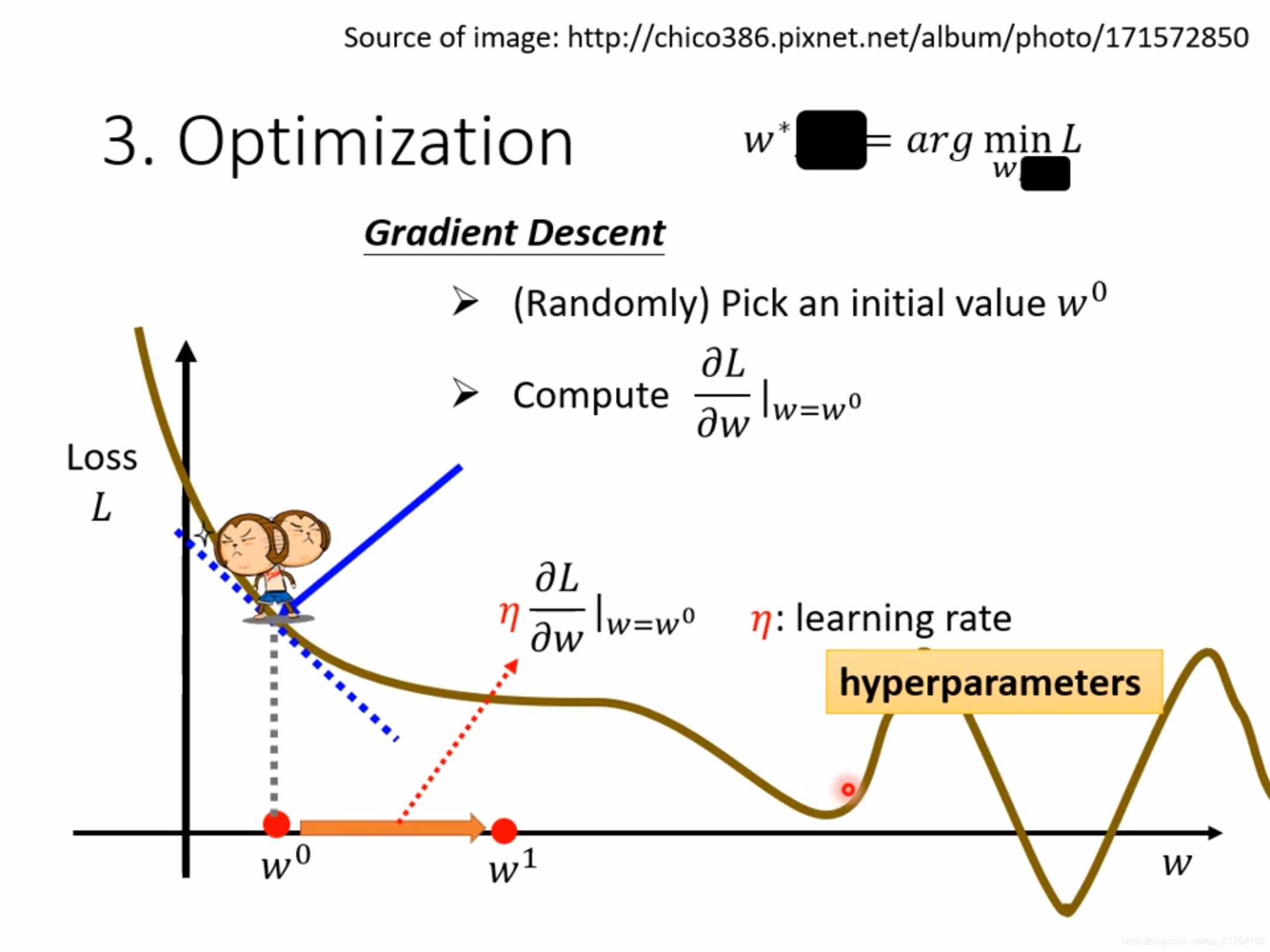
在上面这幅图中,我们的优化方式叫做梯度下降法(之后会专门讲一讲优化的常见方法),我们通过这个方法可以不断地将我们地偏置进行优化,直到我们找到一个最小的loss。
到这里,机器学习的框架就结束了,而深度学习作为机器学习这几年才火起来的一种学习方式,框架和机器学习大同小异,只不过在在第一步设出函数方面更加复杂,还多了很多复杂的优化方法罢了。