反思
看了很久的书踩了不少的坑,也得到了结果,但是…
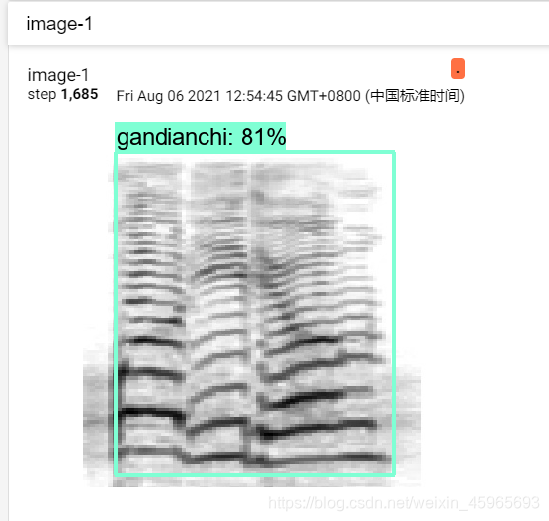
原来的想法是用目标检测模型实现语音谱图的实时检测,我总结下实际用起来的问题:
1.没找到合适的预模型,小数据集多采用迁移学习但目前我还没找到语谱图识别的模型
2.tensorflow1.x书中的很多东西已经过时了而它的目标读者还是刚入门步骤都是集成化的,面多很多细节我还不会调
3.后续,加更多的语音数据,以及呈现的方式,不知道在哪学习。
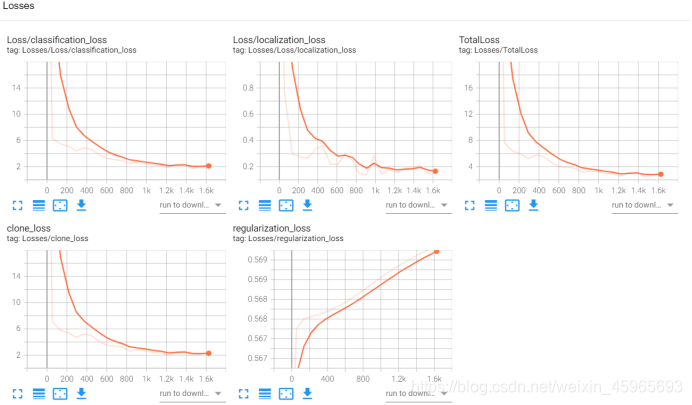
不过通过这个案例学习了一些tensorflow的基础知识提升了debug的能力,但是我得找些更实用的方法了。
新的解决方法
Seth Adamshttps://www.youtube.com/user/seth8141
githubhttps://github.com/seth814/Audio-Classification
kapre(keras audio preprocessors)https://github.com/keunwoochoi/kapre
kerashttps://keras.io/zh/
keras文档精读https://www.bilibili.com/video/BV1eJ411n728