梯度消失,爆炸产生原因:
求和操作其实不影响,主要是是看乘法操作就可以说明问题



所以,总结一下,为什么会发生梯度爆炸和消失:
本质上是因为神经网络的更新方法,梯度消失是因为反向传播过程中对梯度的求解会产生sigmoid导数和参数的连乘,sigmoid导数的最大值为0.25,权重一般初始都在0,1之间,乘积小于1,多层的话就会有多个小于1的值连乘,导致靠近输入层的梯度几乎为0,得不到更新。梯度爆炸是也是同样的原因,只是如果初始权重大于1,或者更大一些,多个大于1的值连乘,将会很大或溢出,导致梯度更新过大,模型无法收敛。
梯度消失,爆炸解决方案:


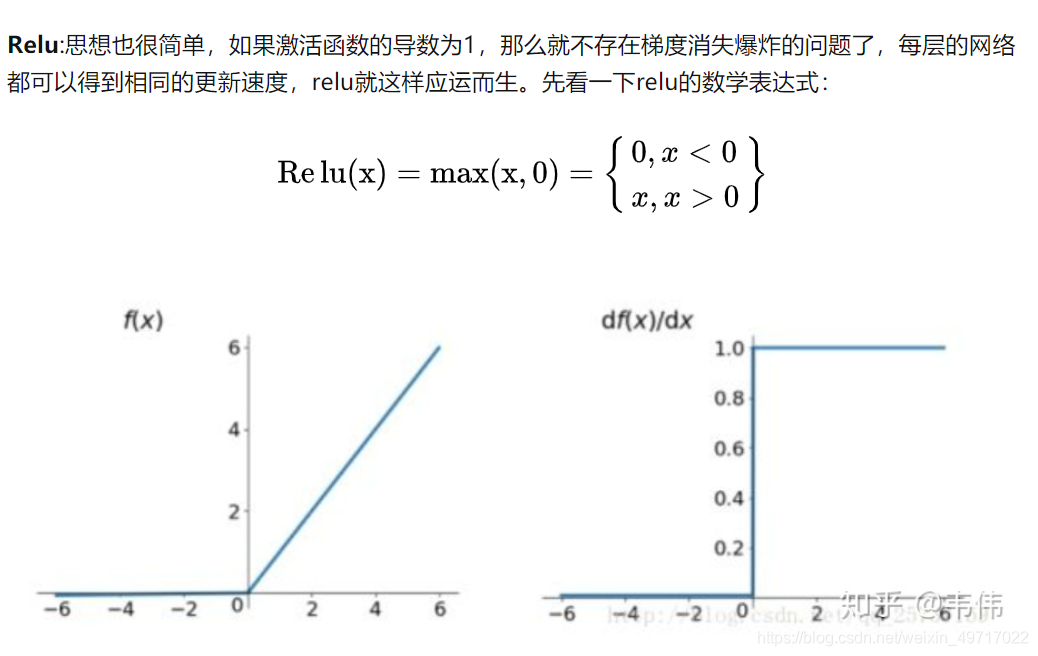
从上图中,我们可以很容易看出,relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
relu的主要贡献在于:
- 解决了梯度消失、爆炸的问题计算方便,计算速度快加速了网络的训练
同时也存在一些缺点:
- 由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)
- 输出不是以0为中心的



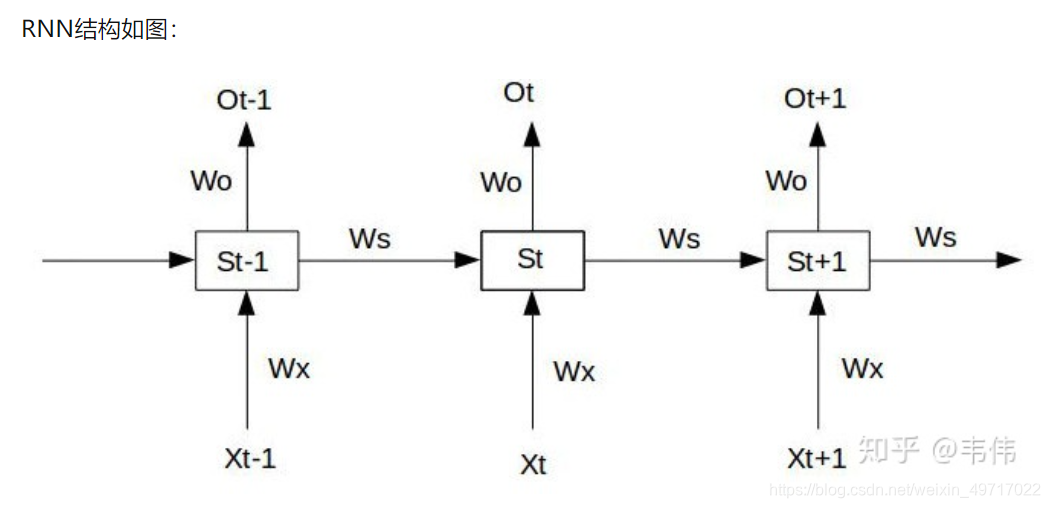

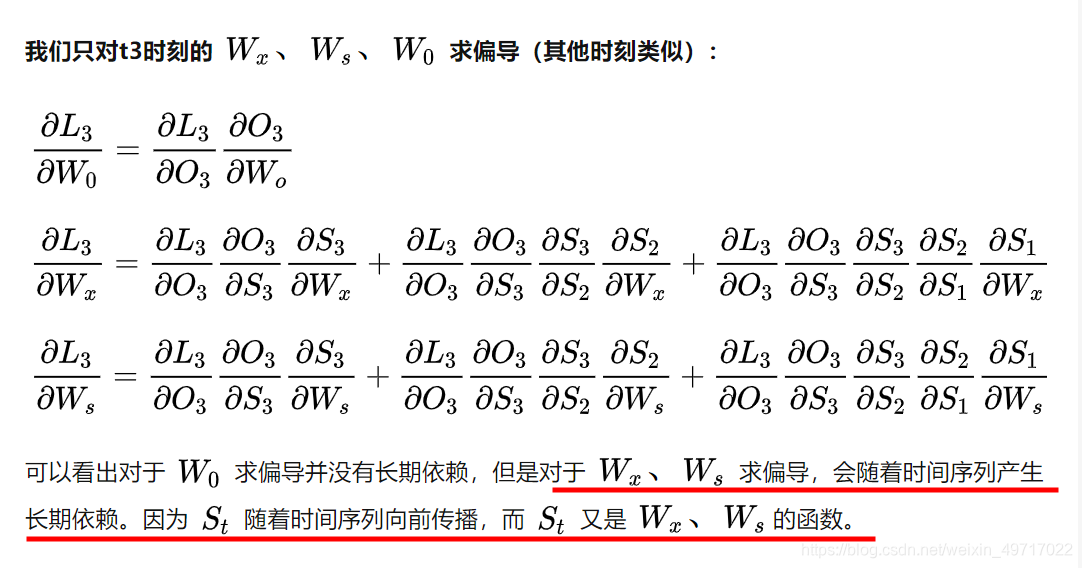

为什么说RNN和DNN的梯度消失问题含义不一样?
1.先来说DNN中的反向传播:
在上文的DNN反向传播中,我推导了两个权重的梯度,第一个梯度是直接连接着输出层的梯度,求解起来并没有梯度消失或爆炸的问题,因为它没有连乘,只需要计算一步。第二个梯度出现了连乘,也就是说越靠近输入层的权重,梯度消失或爆炸的问题越严重,可能就会消失会爆炸。一句话总结一下,DNN中各个权重的梯度是独立的,该消失的就会消失,不会消失的就不会消失。
2.再来说RNN:
**RNN的特殊性在于,它的权重是共享的。**抛开W_o不谈,因为它在某时刻的梯度不会出现问题(某时刻并不依赖于前面的时刻),但是W_s和W_x就不一样了,每一时刻都由前面所有时刻共同决定,是一个相加的过程,这样的话就有个问题,当距离长了,计算最前面的导数时,最前面的导数就会消失或爆炸,但当前时刻整体的梯度并不会消失,因为它是求和的过程,当下的梯度总会在,只是前面的梯度没了,但是更新时,由于权值共享,所以整体的梯度还是会更新,通常人们所说的梯度消失就是指的这个,指的是当下梯度更新时,用不到前面的信息了,因为距离长了,前面的梯度就会消失,也就是没有前面的信息了,但要知道,整体的梯度并不会消失,因为当下的梯度还在,并没有消失。
3.一句话概括:
RNN的梯度不会消失,RNN的梯度消失指的是当下梯度用不到前面的梯度了,但DNN靠近输入的权重的梯度是真的会消失。
从反向传播推导到梯度消失and爆炸的原因及解决方案(从DNN到RNN,内附详细反向传播公式推导) - 韦伟的文章 - 知乎
https://zhuanlan.zhihu.com/p/76772734