小tips
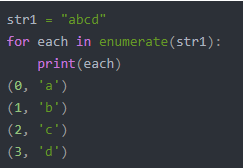
enumerate()函数,迭代器函数,生成由每个元素索引值和元素组成的元组。
列表操作,append函数,在列表末尾添加新的对象,extend函数,用于在列表末尾一次性追加另一个序列中的多个值。
列表索引[-1]

明确比如一个列表或者字符串长度是51,正向索引索引范围就是0到50,负值索引,索引范围就是-51到-1,-1表示最后一个值,取最后一个元素。
4.1 模型构造
继承module类来构造模型,module类是nn模块里提供的一个模型构造类,是所有神经网络的基类,可以继承module类,然后重载__init__函数和forward函数,这两个函数分别创建模型参数也就是初始化过程和定义前向计算。

构建网络的具体过程
生成类的实例化对象,net(X),就会调用module类的 __call__函数 ,这个函数将调用MLP类定义的forward函数来完成前向计算。
module的子类:sequential类 modulelist类 moduledict类
sequential类:可以以更加简单的方式定义模型,可以接收一个子模块的有序字典,或者一系列子模块(也可以说列表)作为参数来逐一添加mudule的实例,包括了前向计算的过程,按照添加顺序进行前向计算。

modulelist类:接收一个子模块的列表作为输入,可以进行append和extend操作,来扩展列表。

但是和sequential相比,modulelist就是一个存储各种模块的列表,模块之间没有顺序和联系,没有实现forward功能,还需自己实现。modulelist可以使网络定义前向传播时更加灵活。就是说可以随意定义前向传播的连接关系。
不同于一般的列表,加入进modulelist模块中的网络参数会自动添加进整个网络中。


moduledict类:接收一个子模块的字典作为输入,也可以类似字典那样进行添加或者访问操作。

同样的,没有forward函数,需要自己定义,写进去的参数会自动添加进网络中。
构造复杂模型
定义类时可以创建不被迭代的参数

先自己定义了一个fancymlp类,然后fancymlp类和sequential类都是module类的子类,可以嵌套调用构建新的网络。

4.2 模型参数的访问 初始化和共享
nn中的init模块包括多种模型初始化方法
定义一个多层感知机:

定义网络时会自动进行默认初始化操作,针对不同的层有不同的策略。使用nn.module模块。
输出为:

注意各层的编号,两个线性层是0,2
访问模型参数
sequential类是module类的继承,所以可以使用module类的parameters()函数和named_parameters方法来访问模型的所有参数(以迭代器的形式返回),有name的那个可以返回名字和参数。

输出

返回的名字自动加上了层数的索引。
也可以访问网络单层的参数,对于使用sequential类构造的网络,可以通过[]访问任一层。

输出

这里只设置了一层就没有层数索引了。可以看到网络参数param的类型是torch.nn.parameter.Parameter,这是一个张量的子类,也就是说它也是一个张量tensor,具有张量的所有属性,可以用data访问参数值,用grad访问参数梯度。

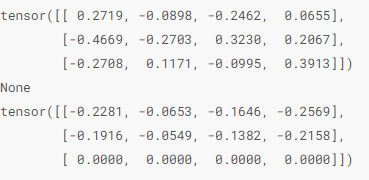
初始化模型参数
除了module模块默认的初始化策略外,常使用init模块初始化模型参数。
例如将模型参数初始化为均值为0,标准差为0.01的正态分布随机数,偏差设置为0.


还可以自定义初始化方法
另外,我们可以改变参数的data值,来改变模型参数值,同时不影响梯度。

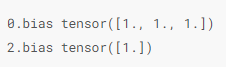
共享模型参数
可以在多个层之间共享梯度,如果forward函数里多次调用同一个层,那么这个层的参数就是共享的。
4.3 模型参数的延后初始化
4.4 自定义层
自定义层,设计复杂的神经网络,就是常在代码里看到的各种堆叠构成最终的神经网络。
不含模型参数的自定义层
继承module类,自定义层,将层的计算写在前向计算函数里。


输出:

用它构造更复杂的模型

含有模型参数的自定义层 模型参数可以通过训练学习出来
我们已经知道了模型参数也是一个张量,因为它是tensor的子类,当一个张量是Parameter时就会自动被添加进模型的参数列表里,所以自定义有模型参数的层时,要定义成Parameter类。
可以直接定义成Parameter类,也可以使用Parameterlist和parameterdict分别定义参数的列表和字典。

下图这种其实就是定义了全连接模块

定义参数字典

下图其实也是定义的全连接层,然后前向计算时只使用了第一层。

然后可以使用自定义的层构造模型

4.5 读取和存储
读取和存储训练好的模型
读取tensor,可以直接使用save函数和load函数存储和读取张量,这个过程是将对象序列化,然后保存在磁盘中,读取时再将文件反序列化为内存。
save函数可以保存各种对象,文件后缀为.pt,包括模型 张量 列表 字典等。

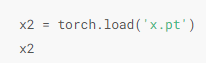

读写网络模型
模型的可学习参数,也就是权重和偏差,可以通过model.parameters()访问,模型也包括在参数中了。
state_dict是一个从参数名称映射到参数tensor的字典对象,可以调用这个操作,返回一个有序字典列表。

输出

只有具有可学习参数的层才会在输出中展示。
优化器也有一个state_dict,包括了优化器状态和超参数的信息,也是一个字典。

输出

保存和加载模型
有两种方式分别是保存和加载模型参数(state_dict)和保存和加载整个模型(包括网络结构)
保存和加载state_dict
保存

以字典形式保存了模型参数
加载

先实例化模型,然后通过保存路径加载模型参数。
保存和加载整个模型
保存

直接保存模型
加载

直接加载模型,不用实例化模型的结构
4.6 GPU计算
使用nvidia-smi来查看显卡信息
默认情况下数据会创建在内存,然后用CPU运算,一些计算操作。
查看GPU是否可用

查看GPU数量

查看当前GPU索引号

根据索引号查看GPU名字

tensor的GPU计算
默认数据在CPU上,输出时不显示标识。

输出

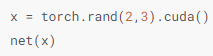
使用 .cuda() 将数据转换到GPU上,有多块GPU时使用 .cuda(i)来表示第i块GPU ,默认从0开始,cuda(0)和cuda()等价。

输出

还可以通过张量的device属性查看张量所在的设备

输出

可以直接在创建的时候指定设备

如果在GPU上进行了运算,结果还是存放在GPU上,存储在不同位置的数据不能进行计算。
模型的GPU运算
可以通过 .cuda()将网络模型转换到GPU上 ,还可以通过检查模型参数device属性查看其存放的设备。
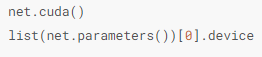
输出

注意:要保证模型的输入和模型都在同一设备上,否则会报错,就是要把输入和模型都转换到GPU上。