图像识别(无参模型)― KNN分类器
图像识别的机器学习方法介绍:
第一阶段:
1.收集大量数据,以及对应的类别(label)
2.利用机器学习方法,训练出一个图像分类器F
第二阶段:
1.对新的图像x,用分类器F预测出类别y=F(x)
引入KNN分类器:
KNN Classifier(K近邻分类):
训练阶段:只需要记录每一个样本的类别即可
测试阶段:计算新图像x与每一个训练样本x(i)的距离d(x,x(i))
找出与x距离最近的k个训练样本
用这k个训练样本中最多数类别作为x的类别
大概流程说完了,接下来看一个示例:
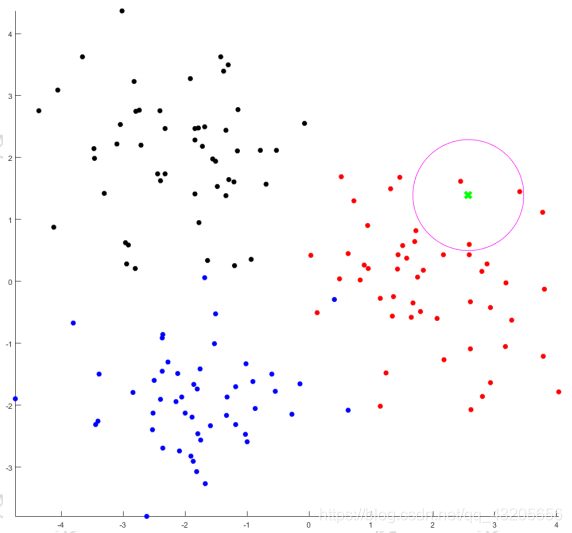 图中在训练阶段记住了哪些是红色的,哪些是黑色以及蓝色,接着在预测时输入的绿色点,则计算与之最近的k个距离的类别,图中选的是k=3,此时发现于绿色点最近的3个样本都是红色,则判定输入的类别和红色的相同。
图中在训练阶段记住了哪些是红色的,哪些是黑色以及蓝色,接着在预测时输入的绿色点,则计算与之最近的k个距离的类别,图中选的是k=3,此时发现于绿色点最近的3个样本都是红色,则判定输入的类别和红色的相同。
讲到这里,我觉得KNN算法应该都能被很好的理解了。
存在的三个问题:
1.如何表示图像x?
2.如何计算距离d(x,x(i))?
3.如何设置合适的k?
问题解答:
1.在计算机视觉中,我们一般使用原始像素值来表示图像。一般彩色图像是由RGB三通道的像素值叠加而成,黑白图片则是单通道的像素值。 输入原始图像假设为256 * 300 * 3,将其进行缩放(resize)为64 * 64 * 3:
输入原始图像假设为256 * 300 * 3,将其进行缩放(resize)为64 * 64 * 3:
 再对其进行拉直(flatten):
再对其进行拉直(flatten): 图像的表示就大概为这个方式。
图像的表示就大概为这个方式。
2.用欧氏距离来计算图像向量之间的距离。
3.k的选取这个问题其实不是太容易抉择,在李航的《统计学习方法》中写到:实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。