题目
Towards knowledge-based recommender dialog system
简介
这是一篇ACL-2019的文章,该论文提出了一个称为KBRD的框架,它是一个基于知识图谱的推荐对话系统,集成了推荐系统和对话生成系统。其中,对话系统可以通过引入基于知识的用户偏好信息来提高推荐系统的性能,而推荐系统可以通过提供推荐感知词汇偏差来提高对话生成系统的性能。实验结果表明,该模型在对话生成和推荐的评估上都比基线有显著的优势。而且一系列的分析表明,集成后的两个系统可以相互促进,除此之外,从知识图谱中引入的知识有助于提升两个系统的表现
why
理想的推荐对话系统是一个端到端的框架,它可以有效地集成这两个系统,来自推荐系统的信息可以提供维持多轮对话的重要信息,其中推荐感知词汇提高了生成对话的质量;而来自对话系统中包含用户偏好暗示的信息可以增强推荐的质量,有效地解决了推荐中的冷启动问题。此外,外部知识的融入可以加强系统之间的联系,有助于弥合系统之间的差距,提高系统的性能
具体地,对话生成系统向推荐系统提供item的上下文信息。例如,对于电影推荐系统,上下文信息可以是导演、演员/女演员和流派。因此,即使在对话中没有提到任何item,推荐系统仍然可以基于上下文信息执行高质量的推荐。同时,推荐系统提供推荐信息来促进对话,例如推荐感知词汇,而这些词汇可能是解释系统推荐决定的部分原因
what
推荐系统一般通过提供的用户信息,从所有项目中检索满足用户兴趣的项目子集。但是在冷启动环境中,推荐系统最初对用户一无所知。不过随着对话的进行,推荐系统可以逐渐积累用户信息并建立用户档案
对话系统一般负责用自然语言生成模型,通过递归地编码和解码先前的信息而生成多轮对话
为了进行端到端的训练,本文进行了推荐系统和会话系统的结合,具体地,推荐系统的输入是基于对话历史来构建的,对话历史是对话中提到的item表示。推荐系统的输出是item set的概率分布,可以与对话系统的输出组合。组合之后,利用switching mechanism控制解码器决定它应该在某个时间步长从词汇表中生成单词还是从推荐器输出中生成item
how
本文提出的框架KBRD通过知识传播有效地集成了推荐系统和对话系统
-
Dialog-Aware Recommendation with Knowledge
推荐一般仅基于对话历史中提到的项目。这种推荐忽略了对话中经常指示用户偏好的上下文信息。本文在推荐过程中利用对话内容,包括非项目信息。此外,为了有效地从非项目信息中推荐项目,我们将来自DBpedia (Lehmann等人,2015)的外部知识图引入到我们的系统中。这些知识可以在对话内容和项目之间建立联系-
Incorporating Dialog Contents
使用DBpedia,将对话中出现的items以及non-item entities与DBpedia中的实体链接起来。通过知识图谱,我们也许可以发现这些non-items的内容可能与某些items联系紧密,这样可以起到丰富对话内容的作用,起到更好的推荐效果这样一来就可以将用户表示为Tu={e1,e2,???,e|τu|}, ei∈ε, 其中ei代表了对话中链接到图谱的items以及non-item entities
-
Relational Graph Propagation
那么接下来的问题就是怎么来表示DBpedia中的实体呢?论文中采用了R-GCN算法来获得图中每个节点的特征表示,因为本文认为知识图中的相邻节点可能共享对推荐有用的相似特征
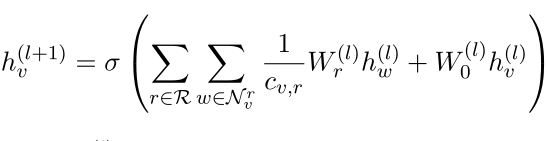
在最后一层L,对于每个v ∈ E,结构和关系信息被编码到实体表示中。我们将E中实体的知识增强隐藏表示矩阵表示为H(L)∈ R|E|×d(L)。为了简单起见,简化成(L) -
Entity Attention
下一步是基于知识增强的实体表示向用户推荐item。虽然一个item对应于知识图上的一个实体,但是用户可能已经与多个实体进行了交互,而且每个用户的对话内容大小不一,对应的|τu|也是不相同的,论文并没有采用简单线性相加的方式,而是采用了self-attention来将不同大小的Hu转换成固定大小的向量表示
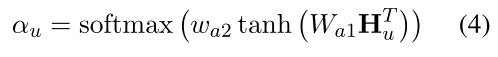
据此得到的αu是一个维度为|Tu|的向量,代表了对话中不同实体的权重,每个用户就可以用tu=αuHu来表示,其表示的内容就是用户的偏好

最后通过用户偏好与图谱中的实体做内积,越相似的话则内积越大,推荐的概率也就越高,即
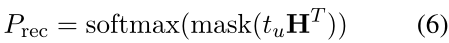
其中的mask的作用是将non-item的实体的分数置为?∞,因为最后要推荐的是item
-
-
Recommendation-Aware Dialog
对话模块在论文中采用的是transformer框架,根据收集到的推荐对话训练集对该模型进行训练,在decoder中每个时间步都会有结果o输出。于是在decoder的最后一层的每一个时间步,就可以输出词汇的概率分布,即
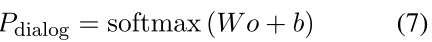
这里W∈R|V|×d,b∈R|V|,Pdialog是一个大小为|V|,即词汇表大小的向量然而,现在的对话系统完全依赖于对话内容的纯文本。进一步引入推荐系统中已经出现在对话中的item knowledge,可以引导对话系统生成的响应更符合用户兴趣
论文中的做法就是,首先经过一个前馈神经网络

其中F:Rd→R|V|,这里也是先将维度统一然后,概率输出变成
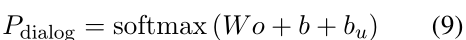
最后,确定在每一步应该输出vocabulary还是item
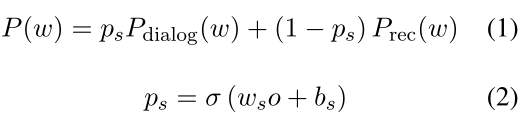
其中w代表的是vocabulary或者是item,o是transformer最后一层的输出,ws∈Rd,bs∈R
Result
-
Dataset
DIALOG(REDIRATE)是一个用于会话推荐的数据集 -
Evaluation Metrics
对话的评估包括自动评估和人工评估:
1)自动评估的标准是perplexity and distinct n-gram,perplexity是对自然语言流畅程度的衡量,较低的困惑是指较高的流畅性;Distinct n-gram是对自然语言多样性的度量
2)人工评价时,让10个具有语言学知识的注释者对候选人与对话历史的一致性进行评分推荐的评价是Recall@K,评价推荐系统选择的前k项是否包含真实推荐。具体使用了Recall@1,Recall@10, Recall@50进行评估
-
Baseline
REDIAL和Transformer -
Result
1)推荐效果
为了评估推荐系统的效果,本文对Recall@K进行了评估。从结果可以发现,本文提出的模型在Recall@1,Recall@10, Recall@50的评估中达到了最佳性能。此外,本文还进行了一项消融研究,以观察对话系统和引入的知识的贡献。可以发现,对话或知识都可以提高推荐系统的表现
 2)对话效果
2)对话效果- 自动评估
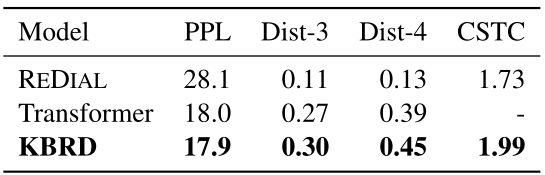
在对perplexity的评估中,Transformer和KBRD达到最佳表现
在distinct n-gram的评估中,KBRD在明显优于基线Transformer
这表明本文的模型可以在不降低流畅性的情况下生成更多样的内容
- 人工评估
baseline REDIAL在对话系统和用户信息没有很强的联系。而在本文的框架中,由于推荐系统向对话系统提供基于用户表示tu的推荐感知词汇偏向bu,对话系统可以获得关于用户偏好的知识,并生成与用户信息一致的响应
- 自动评估
Discussion

-
对话对推荐是否有帮助?
由于大部分的对话中只包含少量items,且推荐问题中也会经常面临冷启动问题,从图中可以看出:
1)在items为零时,baseline和ours(K)表现最差,ours(D)和ours表现明显更好
2)随着items的增加,kg的贡献变得比对话更为显著。平均而言,具有kg和dialog的系统表现最好 -
推荐对对话是否有帮助?
在KBRD中,推荐系统和对话系统之间的联系是推荐系统中的词汇偏差bu。为了进一步研究推荐系统对对话生成的影响,我们从词汇偏向性的角度来显示最偏向的词
具体来说,我们在对话中计算推荐感知偏差,并选择前8个最大值的组件,如下图所示,推荐系统向对话系统传达重要信息。此外,这些带有偏见的词语也可以作为对推荐结果的明确解释。从这个角度来看,这显示了我们模型的可解释性

Conslusion
本文提出了一种新的端到端框架――KBRD,它通过知识传播来弥合推荐系统和对话系统之间的鸿沟
首先对话模块将内容与知识图谱联系起来,将更丰富的内容提供给了推荐模块,使得它可以给出更加符合用户偏好的推荐;当在冷启动的情况下,知识的引入还可以增强推荐性能
同时推荐模块可以将学到的用户偏好和相关知识传递给对话模块,使之可以生成更符合用户偏好的对话,同时增强生成的对话的一致性和多样性