二分类:
数据集:共生成两个数据集。 两个数据集的大小均为10000且训练集大小为7000,测试集大小为3000。 两个数据集的样本特征x的维度均为200,且分别服从均值互为相反数且方差相同的正态分布。 两个数据集的样本标签分别为0和1。0:(7000+3000)1:(7000+3000)
导入库:
import torch
import numpy as np
import random
from IPython import display
from matplotlib import pyplot as plt
import torch.utils.data as Data 数据集的定义:
#自定义数据---训练集
num_inputs = 200
#1类
x1 = torch.normal(2,1,(10000, num_inputs))
y1 = torch.ones(10000,1) # 标签1
x1_train = x1[:7000]
x1_test = x1[7000:]
#0类
x2 = torch.normal(-2,1,(10000, num_inputs))
y2 = torch.zeros(10000,1) # 标签0
x2_train = x2[:7000]
x2_test = x2[7000:]
#合并训练集
# 注意 x, y 数据的数据形式一定要像下面一样 (torch.cat 是合并数据)---按行合并
trainfeatures = torch.cat((x1_train,x2_train), 0).type(torch.FloatTensor)
trainlabels = torch.cat((y1[:7000], y2[:7000]), 0).type(torch.FloatTensor)
#合并测试集
# 注意 x, y 数据的数据形式一定要像下面一样 (torch.cat 是合并数据)---按行合并
testfeatures = torch.cat((x1_test,x2_test), 0).type(torch.FloatTensor)
testlabels = torch.cat((y1[7000:], y2[7000:]), 0).type(torch.FloatTensor)
print(trainfeatures.shape,trainlabels.shape,testfeatures.shape,testlabels.shape)
读取数据:
#读取数据
batch_size = 50
# 将训练数据的特征和标签组合
dataset = Data.TensorDataset(trainfeatures, trainlabels)
# 把 dataset 放入 DataLoader
train_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # 是否打乱数据 (训练集一般需要进行打乱)
num_workers=0, # 多线程来读数据, 注意在Windows下需要设置为0
)
# 将测试数据的特征和标签组合
dataset = Data.TensorDataset(testfeatures, testlabels)
# 把 dataset 放入 DataLoader
test_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # 是否打乱数据 (训练集一般需要进行打乱)
num_workers=0, # 多线程来读数据, 注意在Windows下需要设置为0
)
参数(weight,bias)初始化:
#初始化参数
num_hiddens,num_outputs = 256,1
W1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens,num_inputs)), dtype=torch.float32)
b1 = torch.zeros(1, dtype=torch.float32)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs,num_hiddens)), dtype=torch.float32)
b2 = torch.zeros(1, dtype=torch.float32)
params =[W1,b1,W2,b2]
for param in params:
param.requires_grad_(requires_grad=True)
激活函数Relu定义,定义模型:
def relu(x):
x = torch.max(input=x,other=torch.tensor(0.0))
return x
#定义模型
def net(X):
X = X.view((-1,num_inputs))
H = relu(torch.matmul(X,W1.t())+b1)
return torch.matmul(H,W2.t())+b2 loss,SGD:
#定义交叉熵损失函数
loss = torch.nn.BCEWithLogitsLoss()
#定义随机梯度下降法
def SGD(paras,lr,batch_size):
for param in params:
param.data -= lr * param.grad/batch_size定义模型训练:
#定义模型训练函数
def train(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):
train_ls = []
test_ls = []
for epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期
train_l_sum, train_acc_num,n = 0.0,0.0,0
# 在每一个迭代周期中,会使用训练数据集中所有样本一次
for X, y in train_iter: # x和y分别是小批量样本的特征和标签
y_hat = net(X)
l = loss(y_hat, y.view(-1,1)) # l是有关小批量X和y的损失
#梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward() # 小批量的损失对模型参数求梯度
if optimizer is None:
SGD(params,lr,batch_size)
else:
optimizer.step()
#计算每个epoch的loss
train_l_sum += l.item()*y.shape[0]
#train_acc_num += (y_hat.argmax(dim=1)==y).sum().item()
n+= y.shape[0]
test_labels = testlabels.view(-1,1)
train_ls.append(train_l_sum/n)
test_ls.append(loss(net(testfeatures),test_labels).item())
print('epoch %d, train_loss %.6f,test_loss %.6f'%(epoch+1, train_ls[epoch],test_ls[epoch]))
return train_ls,test_ls
训练:
lr = 0.01
num_epochs = 50
train_loss,test_loss = train(net,train_iter,test_iter,loss,num_epochs,batch_size,params,lr) 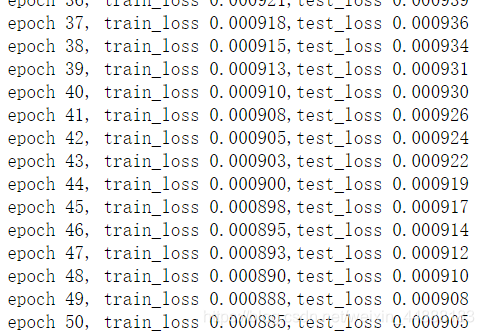
?loss绘图:
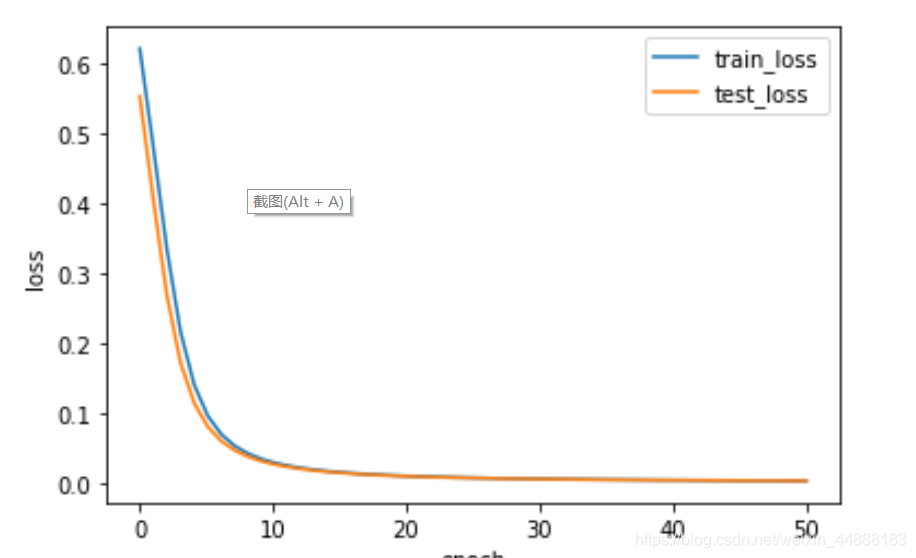
x = np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()
?
?
多分类:
MNIST手写体数据集-----该数据集包含60,000个用于训练的图像样本和10,000个用于测试的图像样本。 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784(28 * 28)个特征的一维numpy数组。
import torch
import numpy as np
import random
from IPython import display
from matplotlib import pyplot as plt
import torchvision
import torchvision.transforms as transforms 下载数据集:
train_dataset=torchvision.datasets.MNIST(root="./Datasets/MNIST",train=True,transform=transforms.ToTensor(),download=True)
test_dataset=torchvision.datasets.MNIST(root="./Datasets/MNIST",train=False,transform=transforms.ToTensor())读数据:
train_loader=torch.utils.data.DataLoader(train_dataset,batch_size=32,shuffle=True)
test_l=torch.utils.data.DataLoader(test_dataset,batch_size=32,shuffle=False)初始化参数weight,bias:
#定义模型参数
num_inputs,num_outputs,num_hiddens=784,10,256
W1=torch.tensor(np.random.normal(0,0.01,(num_hiddens,num_inputs)),dtype=torch.float)
b1=torch.zeros(num_hiddens,dtype=torch.float)
W2=torch.tensor(np.random.normal(0,0.01,(num_outputs,num_hiddens)),dtype=torch.float)
b2=torch.zeros(num_outputs,dtype=torch.float)
params=[W1,b1,W2,b2]
for param in params:
param.requires_grad_(requires_grad=True)激活函数,loss,SGD同上:
# define function(ReLU)
def relu(X):
return torch.max(input=X,other=torch.tensor(0.0))
#define Loss function
loss=torch.nn.CrossEntropyLoss()
#define Module
def net(X):
X=X.view((-1,num_inputs))
H=relu(torch.matmul(X,W1.t())+b1)
return torch.matmul(H,W2.t())+b2
def SGD(params,lr):
for param in params:
param.data-=lr*param.grad多分类计算准确率:
def evaluate_accuracy(data_iter,net,loss):
acc_sum,n=0.0,0
test_l_sum=0.0
for X,y in data_iter:
acc_sum+=(net(X).argmax(dim=1)==y).float().sum().item()
l=loss(net(X),y).sum()
test_l_sum+=l.item()
n+=y.shape[0]
return acc_sum/n,test_l_sum/n训练函数:
def train(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):
train_loss=[]
test_loss=[]
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n=0.0,0.0,0
for X,y in train_iter:
y_hat=net(X)
l=loss(y_hat,y).sum()
#zero grad
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
SGD(params,lr)
else:
optimizer.step()
train_l_sum+=l.item()
train_acc_sum+=(y_hat.argmax(dim=1)==y).sum().item()
n+=y.shape[0]
test_acc,test_l=evaluate_accuracy(test_iter,net,loss)
train_loss.append(train_l_sum/n)
test_loss.append(test_l)
print('epoch %d,loss%.4f,train acc%.3f,test acc%.3f'
%(epoch+1,train_l_sum/n,train_acc_sum/n,test_acc))
return train_loss,test_loss训练:
num_epochs=50
lr=0.1
#train(net,train_loader,test_l,loss,num_epochs,32,params,lr)
train_loss,test_loss=train(net,train_loader,test_l,loss,num_epochs,32,params,lr)
?
绘图:
import matplotlib.pyplot as plt
x=np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()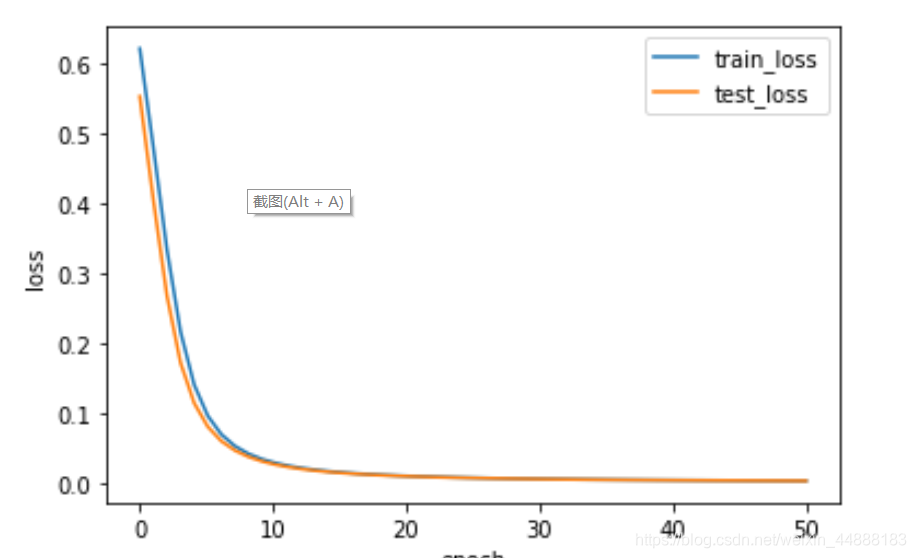
?