01 Mini-batch �ݶ��½���
- X����ѵ�������ļ���,�������ܹ���ԽϿ�ش�������m������,�������m����,�����ٶ���Ȼ�������ڶ�����ѵ����ִ���ݶ��½���ʱ,ԭ������Ҫ��������������,���ܽ���һ���ݶ��½���,Ȼ�������´�����������,���ܽ�����һ���ݶ��½�,��������ڴ�������������֮ǰ,�����ݶ��½�������һ����,��ô�㷨�ٶȽ�����졣������ǿ��Խ�ѵ�����ָ�ΪСһ����Ӽ�(�Ӽ��ͽ�Mini-batch ),������X^ {t}������t���Ӽ�,��ȻYҲ��Ҫ�ָ

- ��ʹ��Mini-batch �ݶ��½���ʱ,ͬ��Ҫ����һ��ѭ��,���ѭ���DZ������е���ѵ����,ͬ����ҲҪ����ǰ�������ۺ���J��ִ�к���������J^ {t}���ݶ�,ֻʹ��X^ {t}��Y^ {t},Ȼ�����Ȩֵ����ֻ�DZ�����һ��ѵ����,��������α�����Ҫʹ��for����while��

02 ���� mini-batch �ݶ��½���
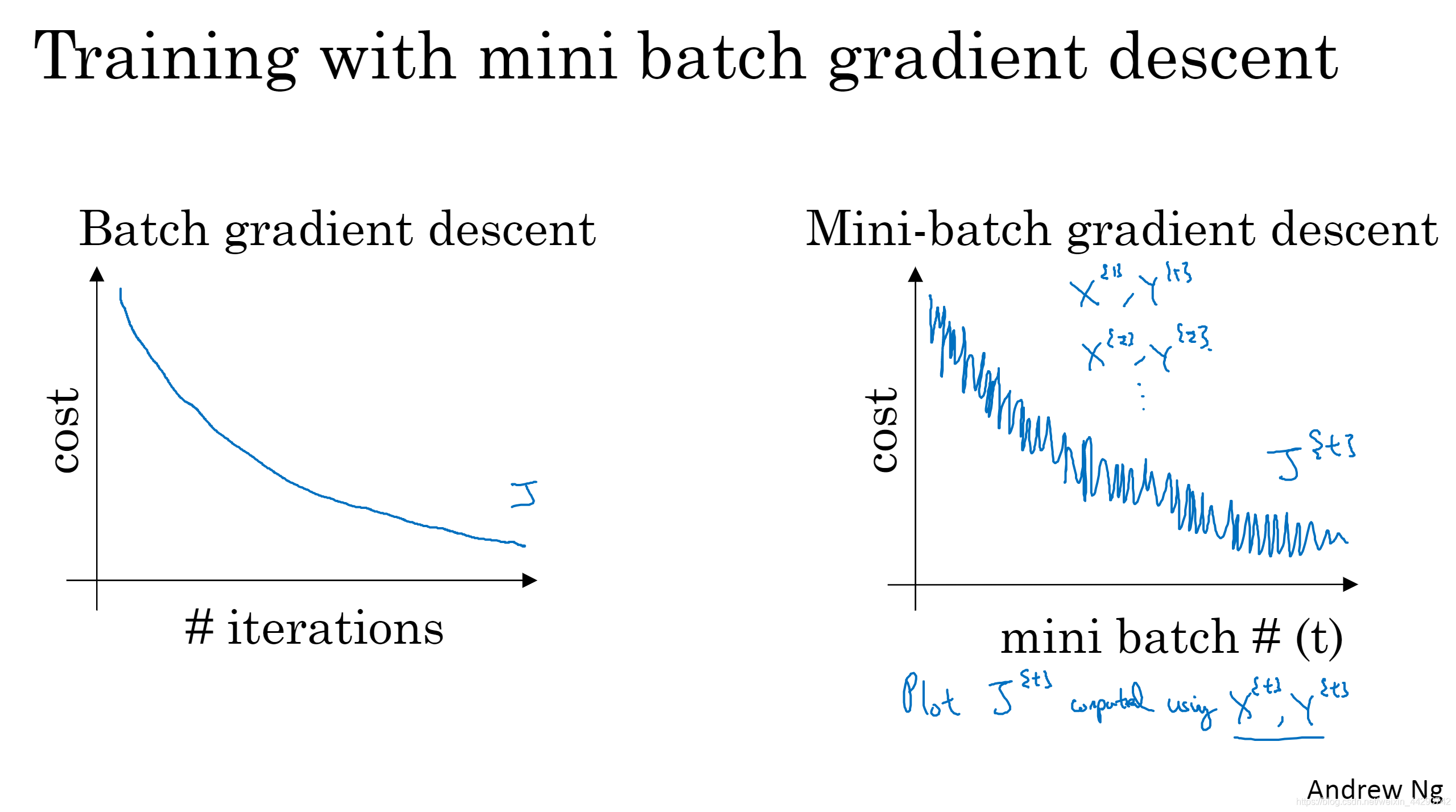
- Batch�ݶ��½���:�ɱ�����J������ÿ�ε�������С;mini-batch �ݶ��½���:����ÿ�ε�������ѵ����ͬ��������(X^ {t}��Y^ {t}),���Գɱ�����J���������,���������������½��ġ�
-
����mini-batch�Ĵ�С�����ּ��˵����:
- mini-batch = m(����ѵ����)�C>Batch�ݶ��½���(���m�ܴ�,�ε�����ʱ̫��)
- mini-batch = 1�C>����ݶ��½���(��ʧȥ���������������ļ���,Ч�ʹ��ڵ���,���ҽ����Զ����������,��һֱ����Сֵ�����ǻ�)
-
�������ּ��������,�ɱ��������Ż����:��ɫ(Batch�ݶ��½���),��ɫ(����ݶ��½���)
-
����Ҫѡ��С��mini-batch�ߴ�,ʵ����ѧϰ���ʴﵽ���:һ����õ�����������,��һ���治��Ҫ�ȴ�����ѵ������������,�Ϳ��Կ�ʼ���к��������ˡ���Ȼmini-batch �ݶ��½����Ľ��Ҳ����������,��һֱ����Сֵ�����ǻ�,��ʱ����������Сѧϰ�ʡ�

- ��ô�����ѡ��mini-batch�ߴ���:���ѵ������С,ֱ��ʹ��batch�ݶ��½�(m<2000);���ѵ�����ϴ�,mini-batch�ߴ�һ��ѡ����64~512,������mini-batch�ߴ����2�η�,������������еıȽϿ졣���Ҫע�������mini-batch��X^ {t}��Y^ {t}Ҫ����CPU/GPU�ڴ�,������������ʹ��ʲô����,�㷨������ֵü�תֱ�¡�

03 ָ����Ȩƽ��
- ���������¶�ɢ��ͼ�����ƻ������¶ȵľֲ�ƽ��ֵ����˵�ƶ�ƽ��ֵ:����V_0=0,Ȼ�����ù�ʽ:ij���V����ǰһ���V��0.9�����ϵ����¶ȵ�0.1��,����������ú�����ͼ�͵õ����ƶ�ƽ��ֵ/ÿ���¶ȵ�ָ����Ȩƽ��ֵ��
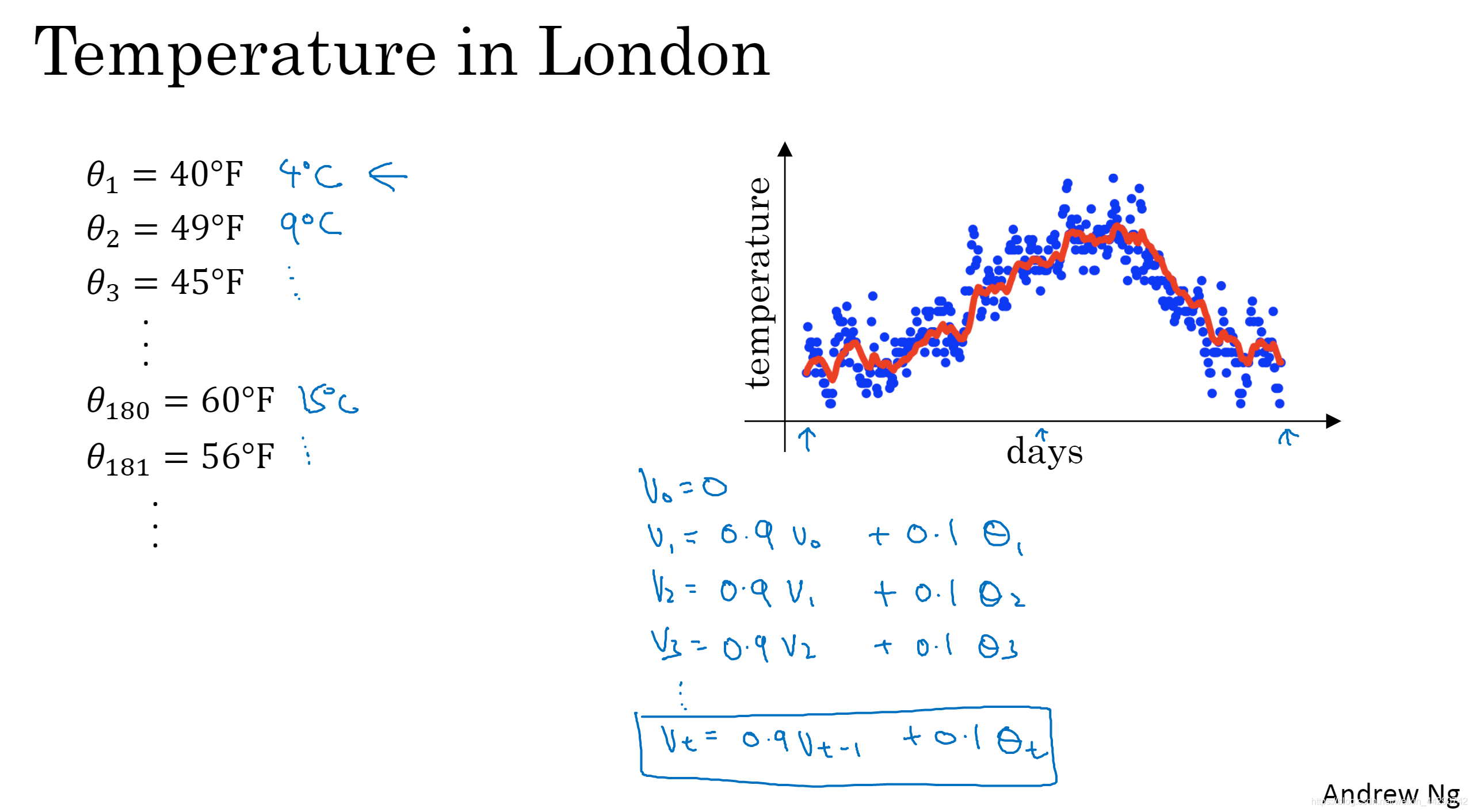
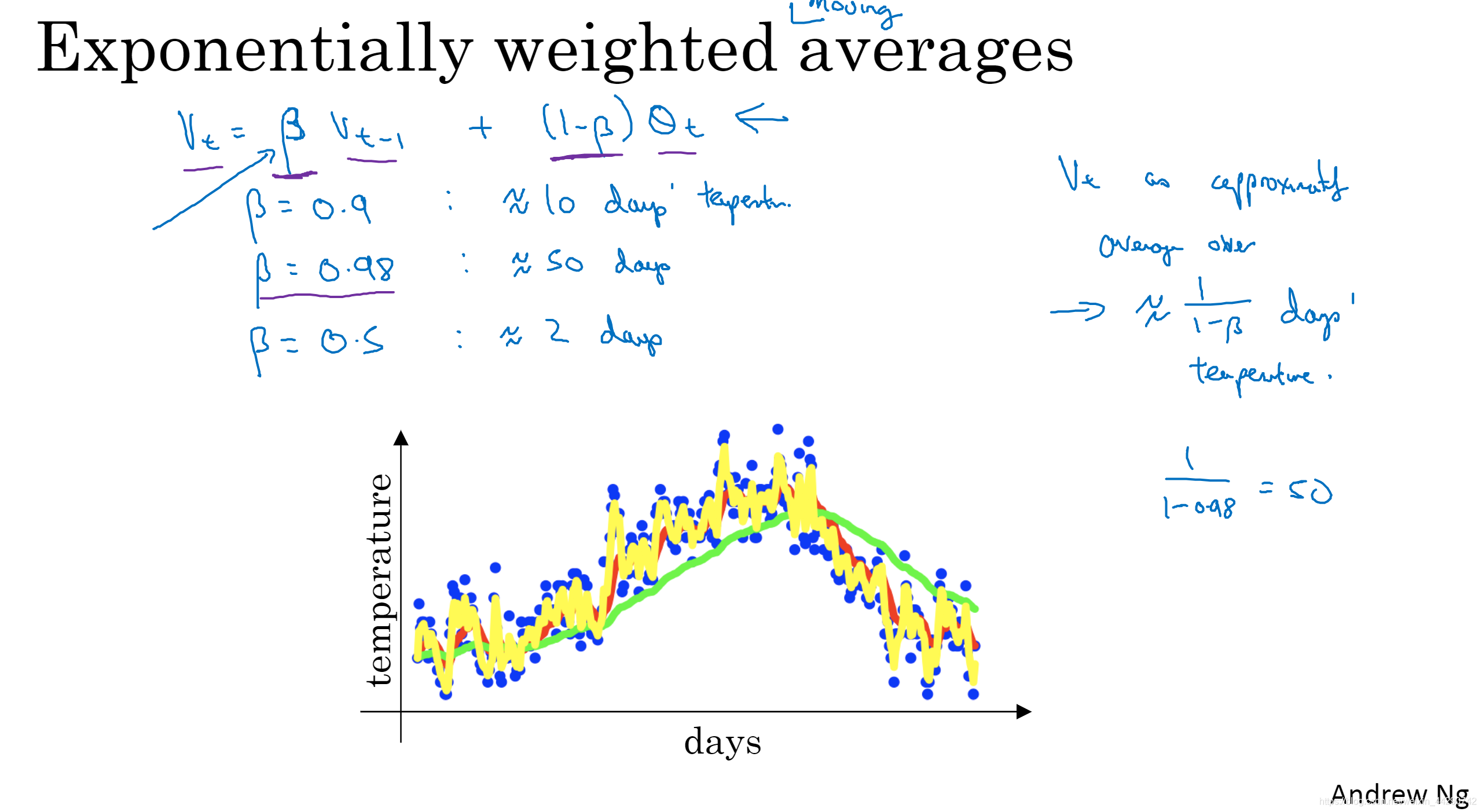
- ���幫ʽ������ʾ:�ڼ���ƽ���������¶�ʱ��1/(1-b)������,���b=0.9��������ʽ��,�ɵ�10Ҳ����ʮ���ƽ��ֵ,���bΪ0.98������ɫ����Ϊ50(ƽ����ȥ50����¶�),���bΪ0.5�õ���ɫ�ߡ�b��������Ĵ�С��������һ��ֵ��Ȩ�ء�
04 ����ָ����Ȩƽ��
-
�������Ȼ�һ��ÿ���¶ȵ�ͼ(���ϵ�һ��),Ȼ��һ��ָ��˥������(���ϵڶ���)��sita��ϵ��,sita99����0.1��0.9��sita98����0.1��(0.9)^ 2,�Դ����ƻ���ͼ������V_100���ǽ�����ͼ��Ӧ��Ԫ�����Ȼ����͡�sita��ϵ��������Ϊ1���߱ƽ�1,���dz�֮Ϊƫ������,������Ϊ��ƫ������,�����ָ����Ȩƽ������
-
��ô������Ҫƽ������������:���ǿ������Ȩ���½�����������Ȩ�ص�����֮һ(��b����һ����,����Ҫ���ٴη����ܴﵽ1/e,���ٴη���1/(1-b)������)
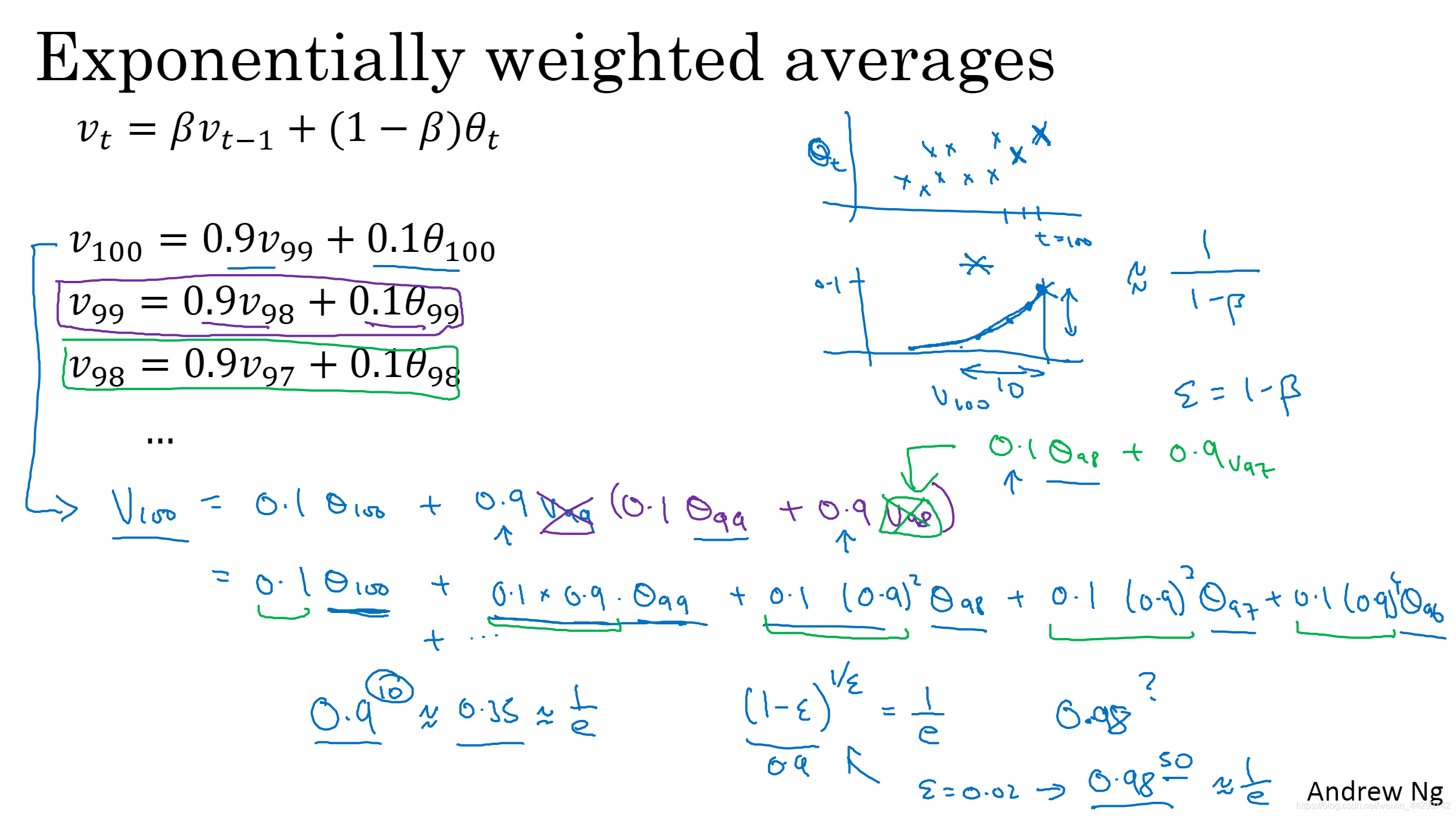
- �����ʵ����ִ��:����ͼ���dz�ʼ��v,Ȼ��ֱ�ӽ����v���빫ʽ�������µ�v,���ϵظ��¡�ע��:��ͼ��=,��ͼ��:=

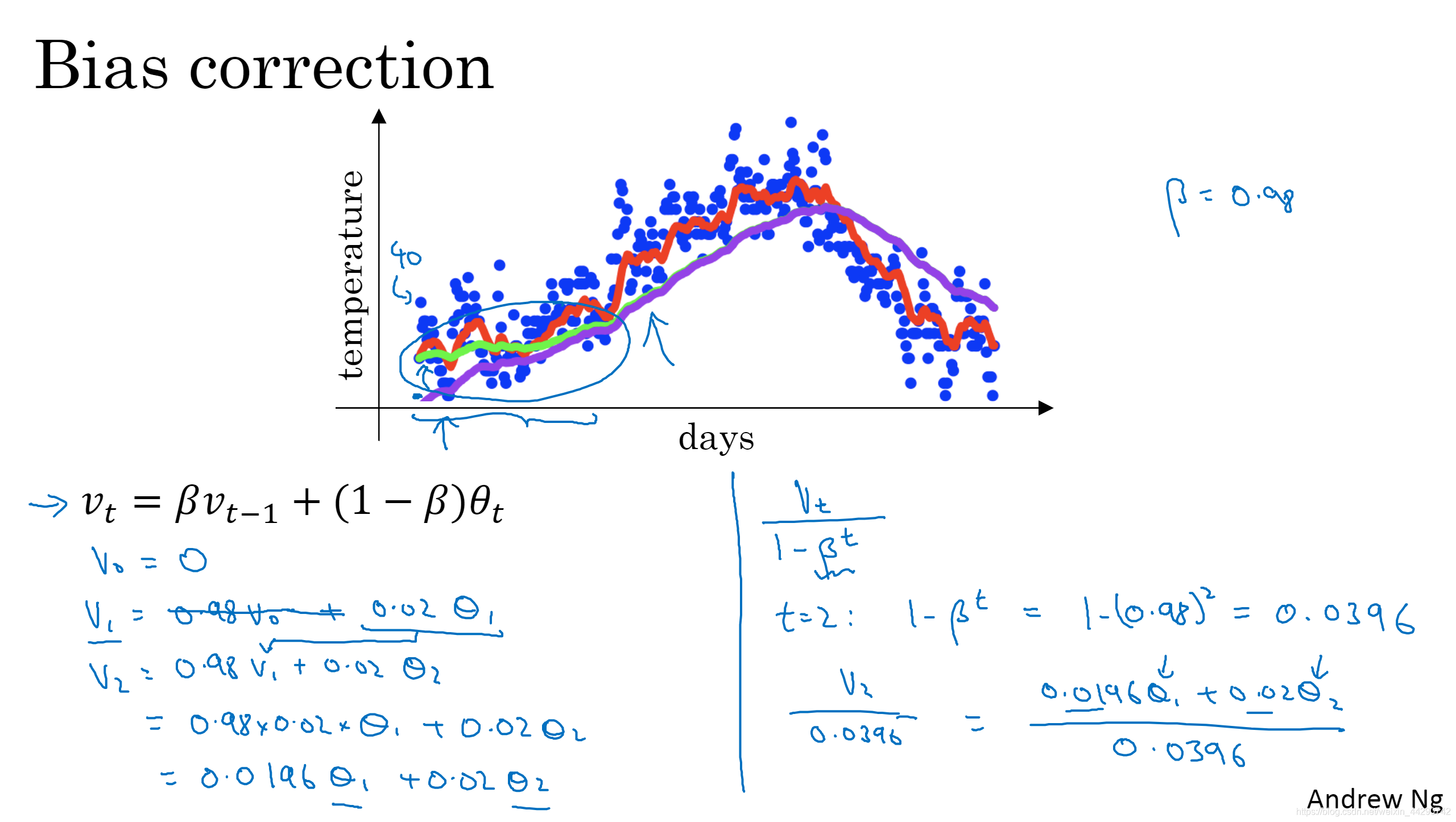
05 ָ����Ȩƽ����ƫ������
- �����������bΪ0.98ʱ������ɫ���߶������͵���ɫ������,��ô���ǾͲ�Ҫ��V_t,������V_t/(1-b^t)������t=2,�����������1�ź�2�����ݵļ�Ȩƽ��������ȥƫ��,����t������,b��t�η��ӽ�0,���Ե�t�ܴ�ʱ,ƫ����������û������,��˵�t�ܴ�ʱ��ɫ��������ɫ���غ��ˡ�������ij�ʼʱ�ڵ�ƫ��,��ô�ڸտ�ʼ����ָ����Ȩ�ƶ�ƽ������ʱ��,ƫ�������ܰ��������ڻ�ø��õĹ��⡣
06 �����ݶ��½���
����һ���㷨��Momentum�ݶ��½���,�����ٶȼ������ǿ��ڱ����ݶ��½��㷨������˼����:�����ݶȵ�ָ����Ȩƽ����,���ø��ݶȸ���Ȩ�ء�
- Momentum�ݶ��½����ڵ�t�ε���������,�����е�Mini-batch����dW��db ��Ȼ��ͨ��ָ����Ȩƽ������õ�dw��db���ƶ�ƽ����,������¸�ֵȨ��,�����Ϳ��Լ����ݶ��½��ķ���(�����᷽��İڶ�С��),Ҳ�������Ӻ��᷽����˶��ٶ�(��ɫ��)�����Ҫ��С����װ����,����dW��db�൱��Ϊ���ɽ�����¹������ṩ�˼��ٶ�,V_dW��V_db�൱���ٶȡ����ڦ���С��1,�൱����Ħ����,���������ļ�����ȥ��

- ������ǿ���������μ���:������ߵĹ�ʽ����1-��,��Ϊ�ұߵĹ�ʽ,��������Ҫ������������,��ô�ͻ�Ӱ��V_dW��V_db,Ҳ����Ҫ��ѧϰ�ʦ�(��Ҫ����1/(1-��)��Ӧ�仯)��

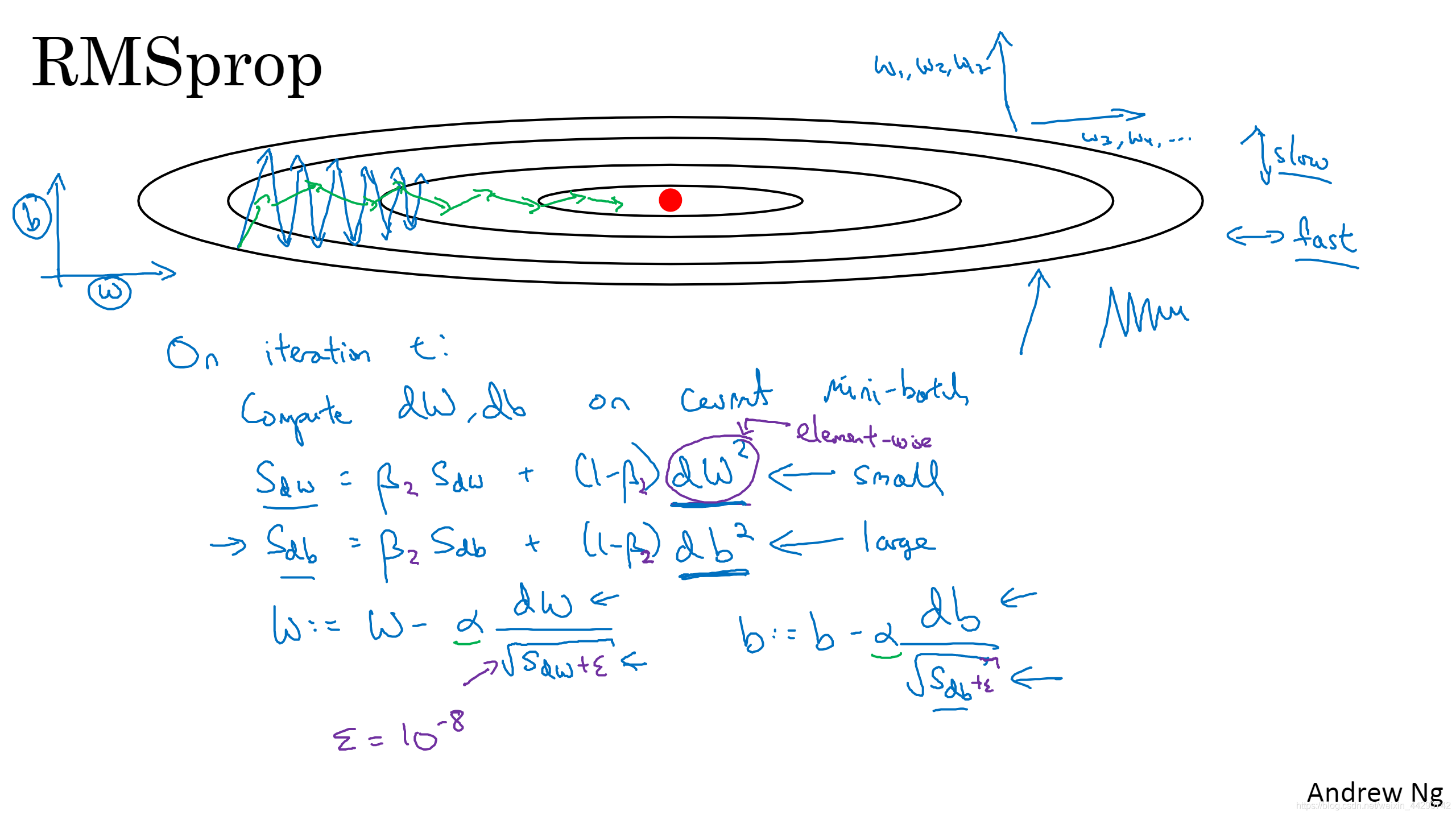
07 RMSprop(������)
RMSpropҲ���Լ����ݶ��½�,��Ϊ���ֽ���ƽ��,���ʹ����ƽ�������Խо�����
- �������������ȴ�,������ǰ�ƽ�������,���������������b,�����������w,��Ҫ����b�����ѧϰͬʱ�ƽ����᷽���ѧϰ,RMSprop�㷨���Խ���ʵ�֡�ͬ����RMSpropҲ���ڵ�t�ε����м��㵱��mini-batch����dW��db,����ͨ������õ�(dw)^ 2��(db)^ 2�ļ�Ȩƽ����,�ڸ��²���ʱҲ����Щ���Ķ�,��ʽ����:��б�ʿ��Կ��������б�ʱȺ���Ĵ�(dW>db)����ͱ�Ϊ��ɫ�ߡ�ͬ����������һ���ϴ��ѧϰ�ʦ����ӿ�ѧϰ,�������������ϴ�ֱ����ƫ�롣Ϊ�˱�֤��ֵ���ȶ�һЩ,��Ҫȷ����ĸ��Ϊ0,��Ҫ�ڷ�ĸ�ϼ�һ����С��С�Ħš�
08 Adam�㷨
Adam�㷨�������ǽ�Momentum��RMSprop�����һ��
- ʹ��Adam�㷨,����Ҫ��ʼ��,�����ڵ�t�ε������õ�ǰ��mini-batch����dW��db,����������momentumָ����Ȩƽ����,Ȼ����RMSprop���и���,�൱��momentum�����˳�������_1,RMSprop�����˦�_2��һ��ʹ��Adam�㷨ʱҪ����ƫ������,���Ϳ��Ը���Ȩ���ˡ�

- �������������:
- ѧϰ�ʦ����Գ���һϵ�е�ֵ���ĸ���Ч
- ��_1����ֵΪ0.9,����dW / db���ƶ�ƽ��ֵҲ���Ǽ�Ȩƽ����
- ��_2����ֵΪ0.999,����(dW)^ 2 / (db)^ 2���ƶ�ƽ��ֵҲ���Ǽ�Ȩƽ����
- �Ž�����10^ -8,����û�б�Ҫ����

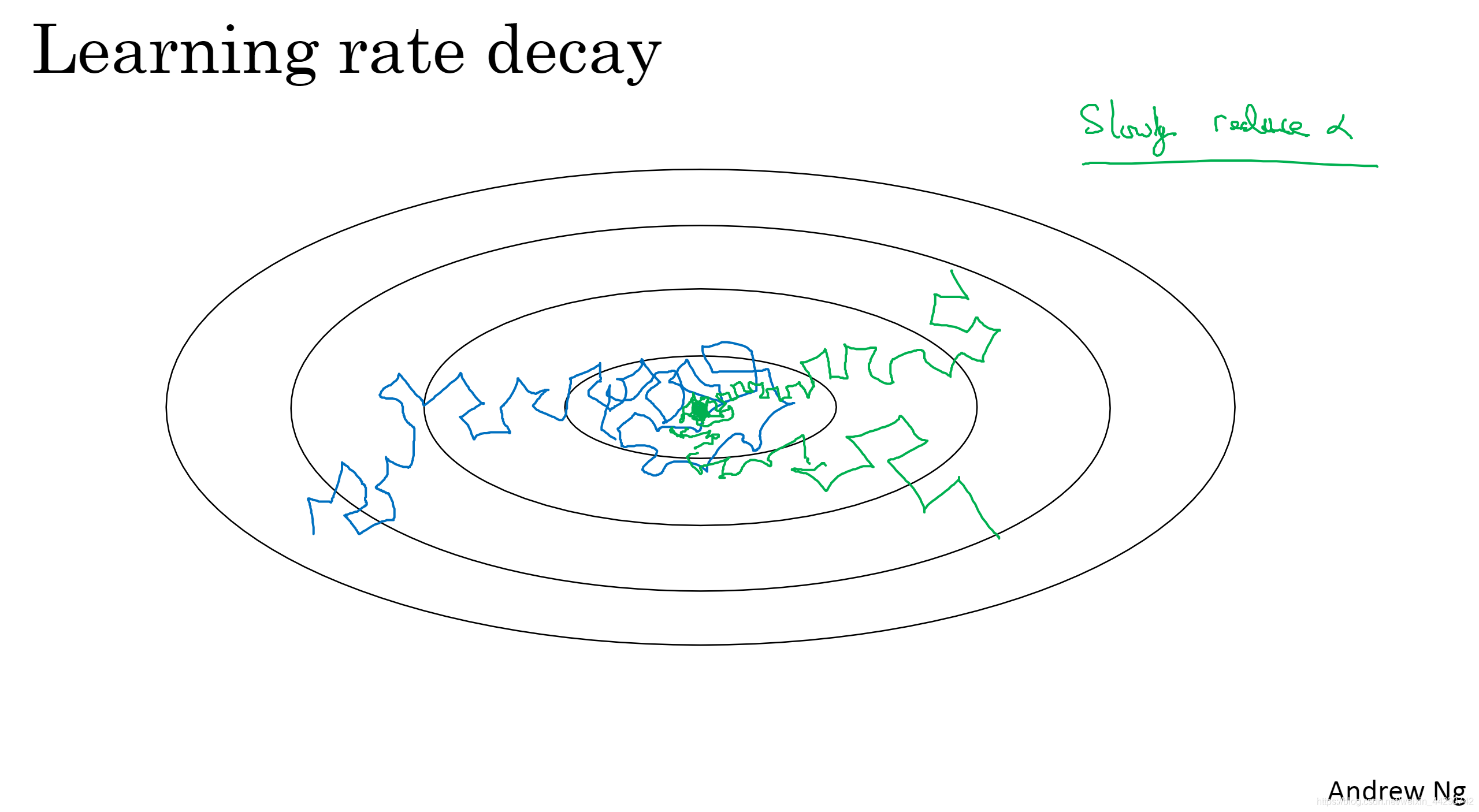
09 ѧϰ��˥��
�ӿ�ѧϰ�㷨��һ���취��������ʱ��������Сѧϰ��,���dz�֮Ϊѧϰ��˥��
- ��ɫ����ʹ��ͬһѧϰ��,����ɫ��������ʱ��������Сѧϰ�ʡ�������Сѧϰ�ʵı�������:��ѧϰ�������ܳ��ܽϴ�IJ���,������ʼ����ʱ,С��ѧϰ�����ò���СһЩ,��������Сֵ��Χ�ڴ���Ȱڶ���
- ��������������ѧϰ��˥��:��һ�α���ѵ��������һ��,�ڶ��ξ��Ƕ��������Խ�ѧϰ����Ϊ(1/(1+˥����* �ڼ���)*��_0,��_0Ϊ��ʼѧϰ�ʡ������ʹ��ѧϰ��˥�˾���Ҫ���ϵس��Բ�������������˥����,�ҵ����ʵ�ֵ��
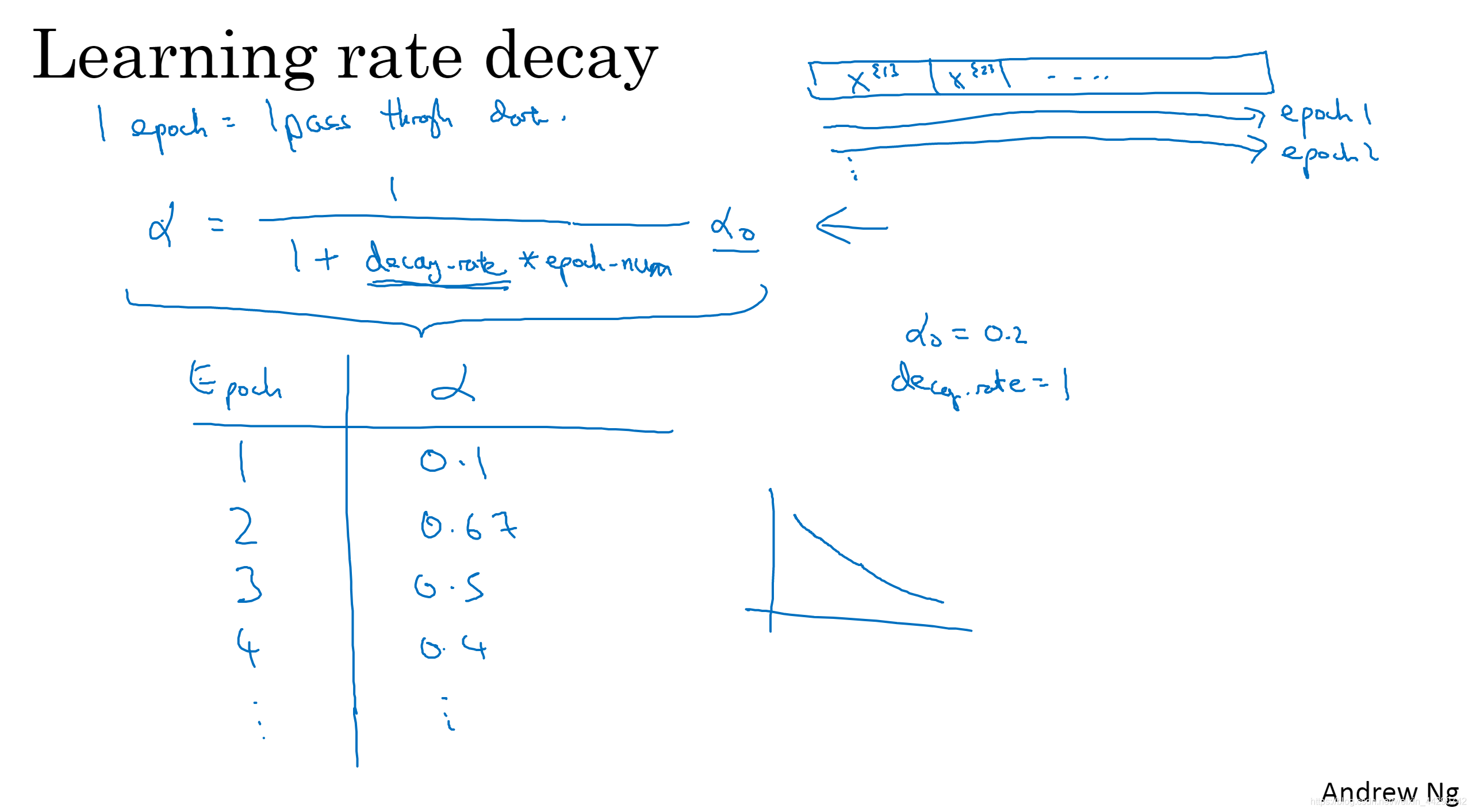
- ����ѧϰ��˥���Ĺ�ʽ,���ǻ�ʹ��ָ��˥����������ʽ:����t����mini-batch�����֡���������ɢ�½�,ѧϰ��һ���һ��һ���һ�롣��Ȼ�������ֶ�����ѧϰ��(��ѵ����С��ʱ��)

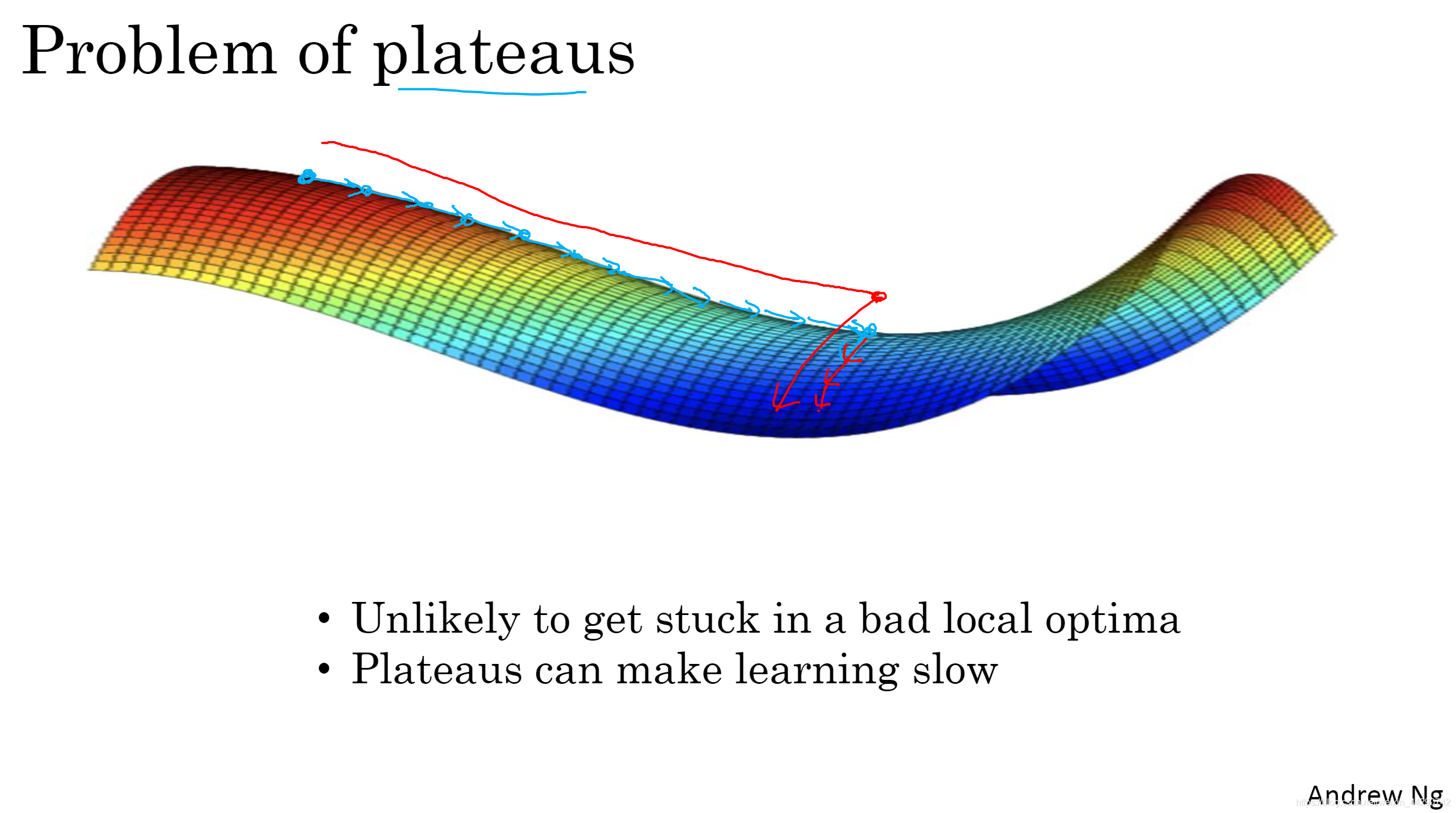
10 �ֲ����ŵ�����
- �ڸ�ά�ȿռ���п���������ͼ�İ���(����Ϊ0�ĵ�),�����������ֲ����š�

- ƽ�ȶλ����ѧϰ�������½���ƽ�ȶ�,Ȼ�����߳�ƽ�ȶΡ�
- ��ѵ���ϴ����������ڴ����������ҳɱ�����J�������ڽϸߵ�ά�ȿռ�ʱ,����������ڼ���ľֲ������С�
- ƽ�ȶ���һ������,����ʹ��ѧϰʮ�ֻ���,��Ҳ����Momentum������RMSprop������Adam�������㷨�ӿ�ѧϰ�㷨�ĵط�,���㾡���߳�ƽ�ȶΡ�