本文来自公众号“每日一醒”
?
Yolo v5一共有四个模型,分别为Yolov5s、Yolov5m、Yolov5l、Yolov5x。
Yolov5s网络最小,速度最少,AP精度也最低,如果检测的以大目标为主,追求速度,倒也是个不错的选择。
其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。

YOLOV5的改进
1、backbone:CSPDarkNet53+Focus
2、neck:SPP+PAN
3、head:YOLOv3
4、自适应图片缩放
5、数据增强:马赛克(Mosaic)
6、自适应锚框计算
7、激活函数:Leaky ReLU 和 Sigmoid 激活函数。
8、损失函数:GIOU
9、跨网格预测(新的Loss计算方法)

Focus
Focus从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进行堆叠,聚焦wh维度信息到c通道空间,提高每个点感受野,并减少原始信息的丢失,该模块的设计主要是减少计算量加快速度。
以Yolov5s的结构为例,原始640*640*3的图像输入Focus结构,采用切片操作,先变成320*320*12的特征图,再经过一次32个卷积核的卷积操作,最终变成320*320*32的特征图。
简单来说就是把数据切分为4份,每份数据都是相当于2倍下采样得到的,然后在channel维度进行拼接,最后进行卷积操作。
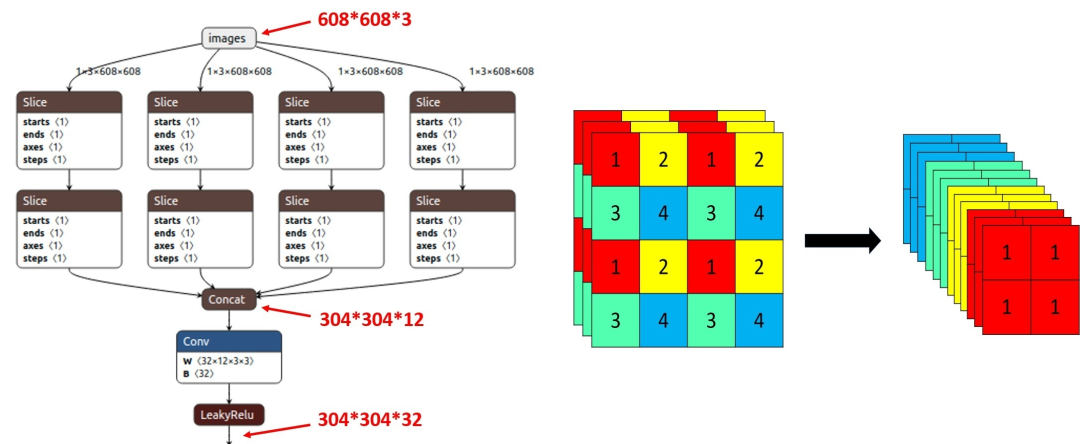
(4*4*3的图像切片后变成2*2*12的特征图)
Focus示意图:
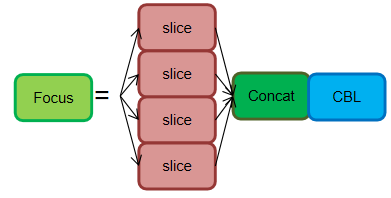

为什么要加fucus?
其最大好处是可以最大程度的减少信息损失而进行下采样操作。
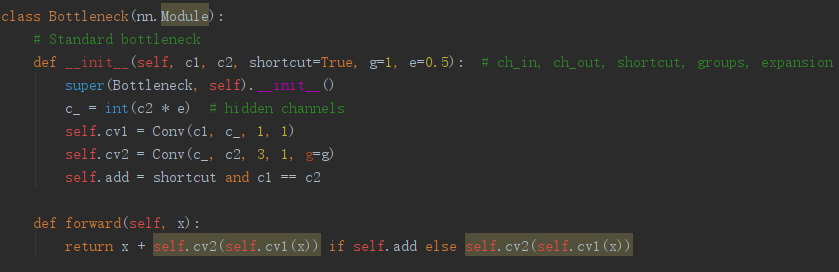
CSP(跨阶段局部网络)
跨阶段局部网络缓解以前需要大量推理计算的问题。
Yolov4中只有主干网络使用了CSP结构,而Yolov5中设计了两种CSP结构。
以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
Yolov4的Neck结构中,采用的都是普通的卷积操作。
Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
CSP示意图:


CSP代码实现:

Res unit模块:



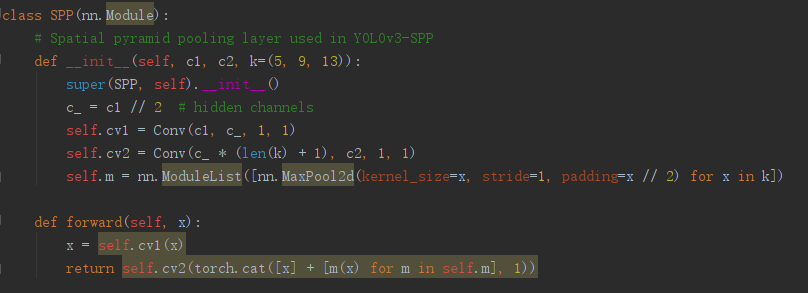
SPP
SPP模块(空间金字塔池化模块), 分别采用5、9、13的最大池化,再进行concat融合,提高感受野。
SPP的输入是512x20x20,经过1x1的卷积层后输出256x20x20,然后经过并列的三个Maxpool进行下采样,将结果与其初始特征相加,输出1024x20x20,最后用512的卷积核将其恢复到512x20x20。
SPP示意图:

SPP代码实现:
自适应锚框计算
在 yolov3、v4 中是采用 kmean 和遗传算法对自定义数据集进行分析,获得合适自定义数据集中对象边界框预测的预设锚点框,计算初始锚框的值是通过单独的程序运行的。
在YOLO V5 中锚定框是基于训练数据自动学习的,此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:
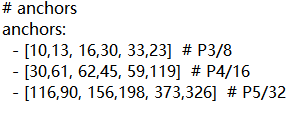
自适应图片缩放
在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
GIOU
Yolov5采用GIOU_Loss做Bounding box的损失函数,使用 二进制交叉熵(BCE) 和 Logits 损失函数 计算类概率和目标得分的损失。
进化二:不相交时,IOU=0,两个框距离变换,IOU loss不变,改进为GIOU。
GIOU Loss,在IOU的基础上引入了预测框和真实框的最小外接矩形。
GIoU公式:
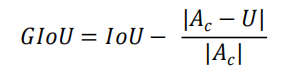
?GIoU Loss公式:
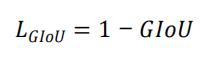
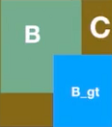
GIOU算法流程如下:

当两框完全重合时取最小值0,当两框的边外切时,损失函数值为1;
当两框分离且距离很远时,损失函数值为2。
使用外接矩形的方法不仅可以反应重叠区域的面积,还可以计算非重叠区域的比例,因此GIOU损失函数能更好的反应真实框和预测框的重合程度和远近距离。
GIOU Loss存在的问题:
1)包含时计算得到的IOU、GIOU数值相等,损失函数值与IOUloss 一样,无法很好的衡量其相对的位置关系。
2)同时在计算过程中出现上述情况,预测框在水平或垂直方向优化困难,导致收敛速度慢。
?
nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。
因为CIOU_Loss中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。
所以Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,Yolov5中采用加权nms的方式。
激活函数
YOLO V5的作者使用了 Leaky ReLU 和 Sigmoid 激活函数。
在 YOLO V5中,中间/隐藏层使用了 Leaky ReLU 激活函数,最后的检测层使用了 Sigmoid 形激活函数。
而YOLO V4使用Mish激活函数。
跨网格预测(新的Loss计算方法)
yolov5的loss设计和前yolo系列差别比较大的地方就是正样本anchor区域计算。
yolov3的loss计算过程非常简单,核心是如何得到loss计算所需的target。
yolov5的很大区别就是在于正样本区域的定义。
yolov3的正样本区域也就是anchor匹配策略非常粗暴:
保证每个gt bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大,并且某个gt一定不可能在三个预测层的某几层上同时进行匹配。
(不考虑一个gt bbox对应多个anchor的场合,也不考虑anchor是否设置合理,不考虑一个gt bbox对应多个anchor的场合的设定会导致整体收敛比较慢。)
yolov5采用了增加正样本anchor数目的做法来加速收敛。
yolov5核心匹配规则为:
(1) 对于任何一个输出层,抛弃了基于max iou匹配的规则,而是直接采用shape规则匹配,也就是该bbox和当前层的anchor计算宽高比,如果宽高比例大于设定阈值,则说明该bbox和anchor匹配度不够,将该bbox过滤暂时丢掉,在该层预测中认为是背景
(2) 对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前yolo系列,至少增加了三倍。
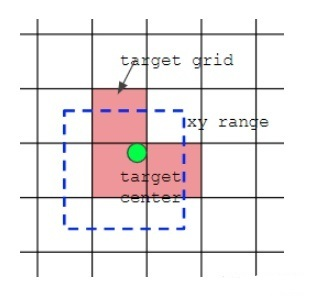
绿点表示该Bbox中心,现在需要额外考虑其2个最近的邻域网格也作为该bbox的正样本anchor。
bbox的xy回归分支的取值范围不再是0~1,而是-0.5~1.5(0.5是网格中心偏移),因为跨网格预测了。
在任何一预测层,将每个bbox复制和anchor个数一样多的数目,然后将bbox和anchor一一对应计算,去除不匹配的bbox,然后对原始中心点网格坐标扩展两个邻居像素,增加正样本anchor。
有个细节需要注意,前面shape过滤时候是不考虑bbox的xy坐标的,也就是说bbox的wh是和所有anchor匹配的,会导致找到的邻居也相当于进行了shape过滤规则,故对于任何一个输出层,如果该bbox保留,那么至少有3个anchor进行匹配,并且保留的3个anchor shape是一样大的。
即保留的anchor在不考虑越界情况下是3或者6或者9。
(1) 不同于yolov3和v4,其gt bbox可以跨层预测即有些bbox在多个预测层都算正样本
(2) 不同于yolov3和v4,其gt bbox的匹配数范围从3-9个,明显增加了很多正样本(3是因为多引入了两个邻居)
(3) 不同于yolov3和v4,有些gt bbox由于和anchor匹配度不高,而变成背景
这种特别暴力增加正样本做法还是存在很大弊端,虽然可以加速收敛,但是由于引入了很多低质量anchor,对最终结果还是有影响的。
yolo v5深度与宽度控制
Yolov5代码中的四种网络,和之前的Yolov3,Yolov4中的cfg文件不同,都是以yaml的形式来呈现。
而且四个文件的内容基本上都是一样的,只有最上方的depth_multiple和width_multiple两个参数不同。
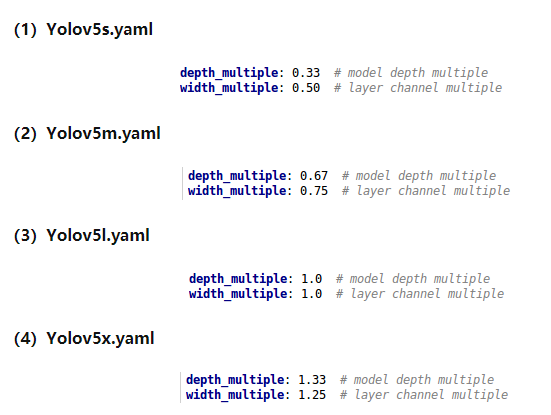
四种结构就是通过上面的两个参数,来进行控制网络的深度和宽度。
其中depth_multiple控制网络的深度,width_multiple控制网络的宽度。
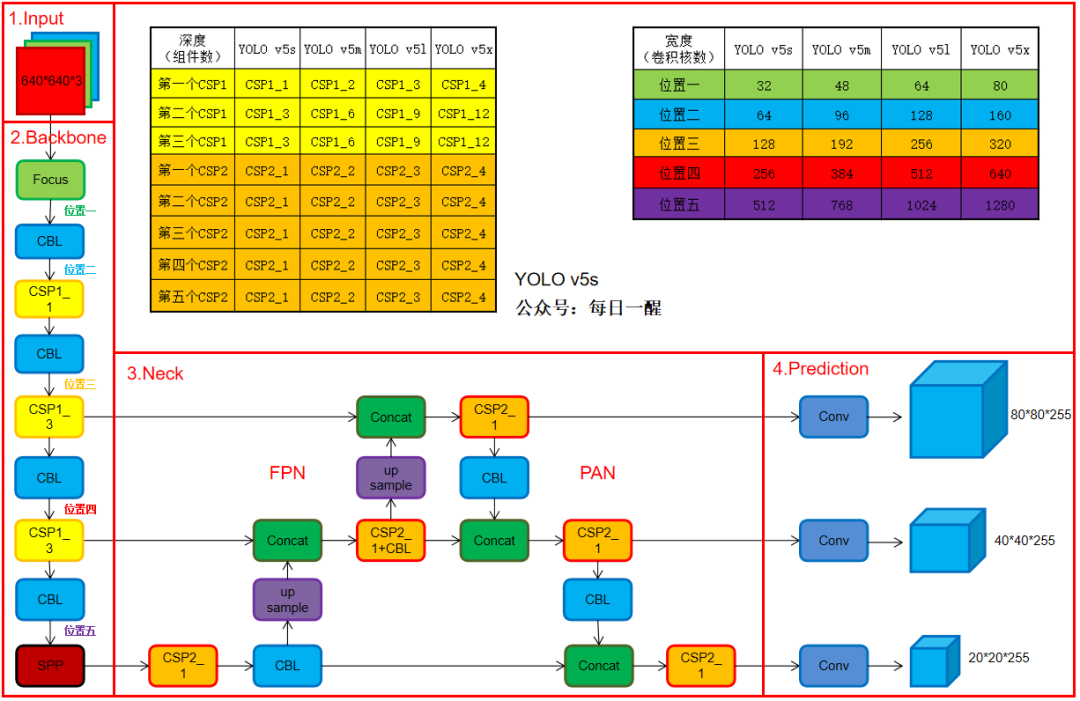
深度:四种网络结构中每个CSP结构的深度都是不同的。
yolov5s,第一个CSP1中,使用了1个残差组件,是CSP1_1。
Yolov5m,在第一个CSP1中,使用了2个残差组件,是CSP1_2。
Yolov5l,在第一个CSP1中,使用了3个残差组件,是CSP1_3。
Yolov5x,在第一个CSP1中,使用了4个残差组件,是CSP1_4。
宽度:四种yolov5结构在不同阶段的卷积核的数量都是不一样的,因此也直接影响卷积后特征图的第三维度,即厚度。
Yolov5s,第一个Focus结构中,最后卷积操作使用了32个卷积核,因此经过Focus结构,特征图的大小变成304*304*32。
yolov5m,第一个Focus结构中,最后卷积操作使用了48个卷积核,因此经过Focus结构,特征图的大小变成304*304*48。
yolov5l,yolov5x也是同样的原理。
总结
yolov5:
(1) 考虑了邻域的正样本anchor匹配策略,增加了正样本。
(2) 通过灵活的配置参数,可以得到不同复杂度的模型。
(3) 通过一些内置的超参优化策略,提升整体性能。
(4) 和yolov4一样,都用了mosaic增强,提升小物体检测性能。
?

???
?――――――
浅谈则止,细致入微AI大道理
扫描下方“每日一醒”,选择“关注”公众号
―――――――――――――――――――――

―――――――――――――――――――――