一.超参数
1.引言
机器学习模型中一般有两类参数:
一类需要从数据中学习和估计得到,称为模型参数(Parameter)―即模型本身的参数。比如,线性回归直线的加权系数(斜率)及其偏差项(截距)都是模型参数。
另一类则是机器学习算法中的调优参数(tuning parameters),需要人为设定,称为超参数(Hyperparameter)。比如,正则化系数λ,决策树模型中树的深度。
2.超参数的定义
度娘定义:
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
狐仙补充:
超参数也是一个参数,是一个未知变量,但是它不同于在训练过程中的参数,它是可以对训练得到的参数有影响的参数,需要训练者人工输入,并作出调整,以便优化训练模型的效果。
3.超参数的特点
1.定义关于模型的更高层次的概念,如复杂性或学习能力。
2.不能直接从标准模型培训过程中的数据中学习,需要预先定义。
3.可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
4.超参数与模型参数的区别
模型参数是模型内部的配置变量,需要用数据估计模型参数的值;
模型超参数是模型外部的配置,需要手动设置超参数的值。
机器学习中一直说的“调参”,实际上不是调“参数”,而是调“超参数”。
5.超参数的示例
1.树的数量或树的深度
2.矩阵分解中潜在因素的数量
3.学习率(多种模式)
4.深层神经网络隐藏层数
5.k均值聚类中的簇数
6.超参数的优化
1.超参数优化的目的
学习率可能是最重要的超参数。
[1] 超参数优化或模型选择是为学习算法选择一组最优超参数时的问题,通常目的是优化算法在独立数据集上的性能的度量。 通常使用交叉验证来估计这种泛化性能。
[2] 超参数优化与实际的学习问题形成对比,这些问题通常也被转化为优化问题,但是优化了训练集上的损失函数。 实际上,学习算法学习可以很好地建模/重建输入的参数,而超参数优化则是确保模型不会像通过正则化一样通过调整来过滤其数据。
2.超参数优化的方法
1.网格搜索
2.贝叶斯优化
3.随机搜索
4.基于梯度的优化
二.超平面
度娘定义:
超平面是n维欧氏空间中余维度等于一的线性子空间,也就是必须是(n-1)维度。
这是平面中的直线、空间中的平面之推广(n大于3才被称为“超”平面),是纯粹的数学概念,不是现实的物理概念。因为是子空间,所以超平面一定经过原点。
相信大家看完定义,脑中应该是一万头神兽奔腾而过,也就是对于度娘的定义,我们的理解是什么鬼,能不能说人话,这时候,就得我狐仙登场了。
狐仙定义:
1.我们都知道,零维的点可以把一维的线分成两部分:
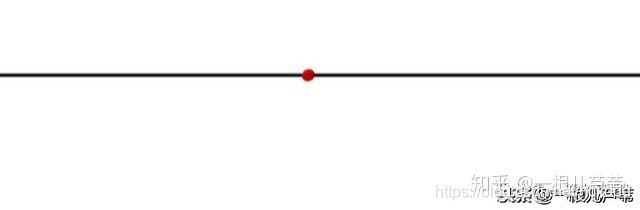
2.一维的线可以把二维的面分成两部分:
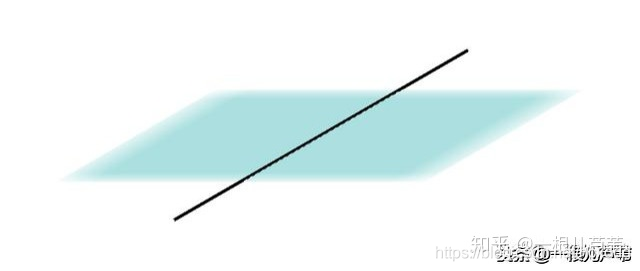
3.二维的面可以把三维的体分成两部分:
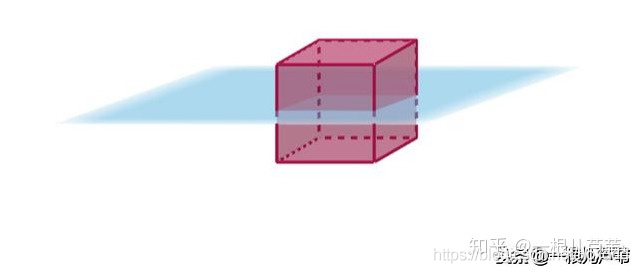
依此类推,n-1维的子空间可以把n维空间分成两部分。
所以,超平面就是这个n-1维子空间,它就像3维空间中的平面,可以用来分割n维空间。