用通俗的语言来说,attention就是 分析某一个 向量与一组向量的相关性 只是不使用直接的相关性系数,来使用矩阵的方法 进行计算 当然了 这里最简单的attention与transformer 里面的还是不一样的?attention 有好多种 !!
视频参考:https://www.bilibili.com/video/BV1op4y1U7ag?from=search&seid=900729188878337684

?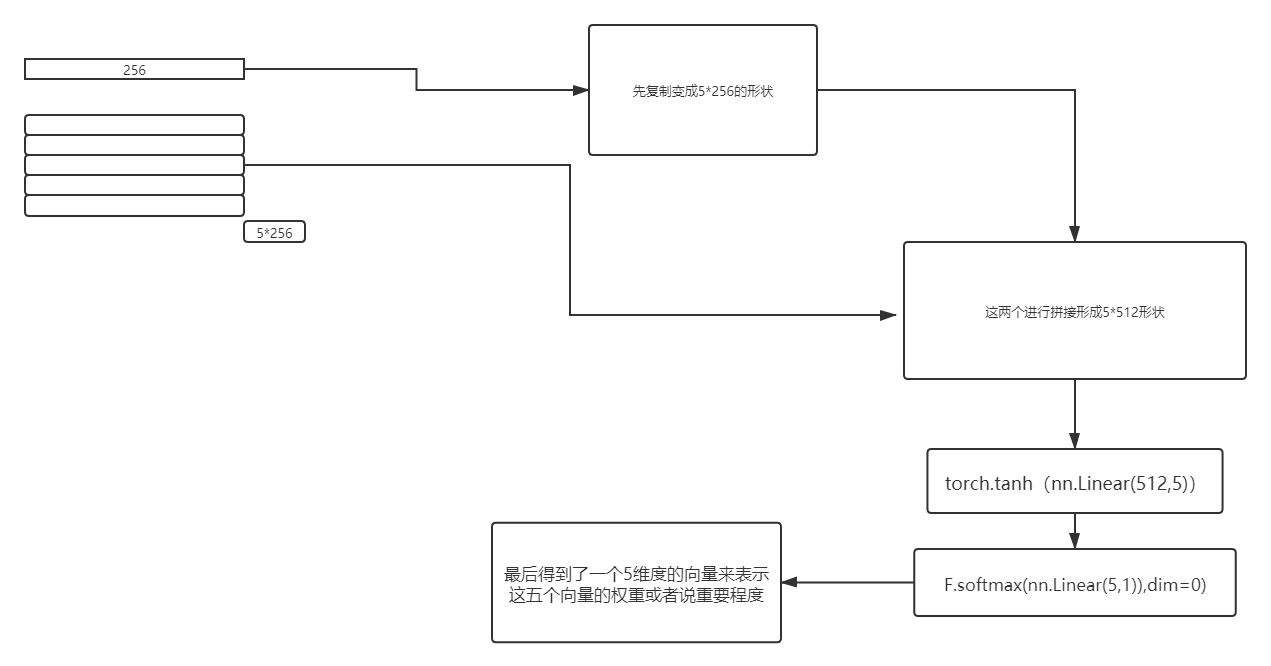
?代码实现:这里的数据是二维的 假设是三维的,一般在seq2seq中会有 ,而且第一维度的 也是1
所以不影响!
a=torch.rand(1,256)
a=a.repeat(10,1)
print(a.size())
b=torch.rand(10,256)
weights = torch.tanh(attn(torch.cat([a, b],1)))
print(weights.size())
v=nn.Linear(10,1)
attention = F.softmax(v(weights),dim=0)
print(attention)?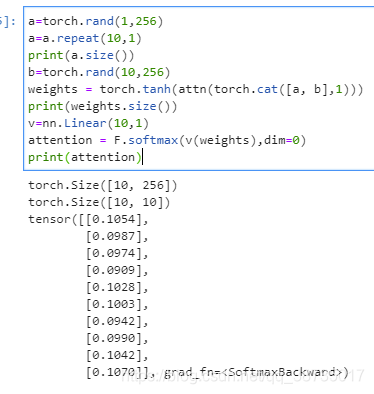
?
?