[Դ�����] ����ѧϰ���������� Paracel (1)-----����ܹ�
����Ŀ¼
0x00 ժҪ
Paracel�Ƕ��꿪����һ���ֲ�ʽ������,�����ڲ�����������ʽ���������ѧϰ������:���ع顢SVD������ֽ�(BFGS,sgd,als,cg),LDA,Lasso����
Paracel֧�����ݺ�ģ�͵IJ���,Ϊ�û��ṩ�����õ�ͨ�Žӿ�,��mapreduceʽ��ϵͳҪ������Paracelͬʱ֧���첽��ѵ��ģʽ,ʹ�������������ظ��졣����,Paracel����Ľṹ�봮�г���ʮ������,�û����Ը���רע���㷨����,���轫����������ڷֲ�ʽ���ϡ�
��Ϊ����֮ǰ�Ѿ���ps-lite�Բ����������Ļ����������˽���,�����ڱ�����,������Ҫ��ps-lite�ȶ���ķ����һЩ�ؼ�������(paracelû�п�Դ�ݴ�����,�Ǹ���С���ź�),��������� ps-lite ����������ϸ�ķ�����
���ڱ�����˵,ps-lite����Ҫ������:
��ϵ������������:
[ Դ�����] ����ѧϰ����������ps-lite (1) ----- PostOffice
[ Դ�����] ����ѧϰ����������ps-lite(2) ----- ͨ��ģ��Van
[ Դ�����] ����ѧϰ����������ps-lite ֮(3) ----- ������Customer
[Դ�����]����ѧϰ����������ps-lite(4) ----- Ӧ�ýڵ�ʵ��
�����ڽ���ʱ���ɾ�����ַ�������롣
0x01ʹ��
��������ͨ��Դ���ṩ��LR�㷨�������ʹ�á�
1.1 ����&����
���Ǵ�Դ�����ҵ� LR ��ز�������,���¾���һЩ��Ҫ����,�����������˲��ַ���,��Ҫ�������:��һ����������������ɲ�ͬ���͵�ʵ��,ʵ�����еĶ��ǿ�ִ�г��� lr��
- Enter Paracel��s home directory ����Paracel����Ŀ¼
```cd paracel;```
- Generate training dataset for classification ����ѵ�����ݼ�
```python ./tool/datagen.py -m classification -o training.dat -n 2500 -k 100```
- Set up link library path: �������ӿ�·��
```export LD_LIBRARY_PATH=your_paracel_install_path/lib```
Create a json file named
cfg.json, see example in Parameters section below. ���������ļ�Run (4 workers, local mode in the following example) ����(4��worker,2������������)
```./prun.py -w 4 -p 2 -c cfg.json -m local your_paracel_install_path/bin/lr```
Default parameters are set in a JSON format file. For example, we create a cfg.json as below(modify
your_paracel_install_path):{
? ��training_input�� : ��training.dat��, ѵ����
? ��test_input�� : ��training.dat��, ��֤��
? ��predict_input�� : ��training.dat��, label����
? ��output�� : ��./lr_result/��,
? ��update_file�� : ��your_paracel_install_path/lib/liblr_update.so��,
? ��update_func�� : ��lr_theta_update��, ���º���
? ��method�� : ��ipm��,
? ��rounds�� : 100,
? ��alpha�� : 0.001,
? ��beta�� : 0.01,
? ��debug�� : false
}
1.2 ����
ͨ��makefile���ǿ��Կ���,�ǰ� lr_driver.cpp, lr.cppһ������Ϊ lr ��ִ���ļ����� update.cpp ����ɿ�,�����������ص��á�
add_library(lr_update SHARED update.cpp) # ��������������
target_link_libraries(lr_update ${CMAKE_DL_LIBS})
install(TARGETS lr_update LIBRARY DESTINATION lib)
add_library(lr_method SHARED lr.cpp) # �㷨����
target_link_libraries(lr_method ${Boost_LIBRARIES} comm scheduler)
install(TARGETS lr_method LIBRARY DESTINATION lib)
add_executable(lr lr_driver.cpp) # ��������
target_link_libraries(lr
${Boost_LIBRARIES}
comm scheduler lr_method)
install(TARGETS lr RUNTIME DESTINATION bin)
1.3 �ݶ��½���
���� LR,������ ���ģ��������������ݶ��½��� ����ѡ��
-
dgd: distributed gradient descent learning
-
ipm: iterative parameter mixtures learning
-
downpour: asynchrounous gradient descent learning
-
agd: slow asynchronous gradient descent learning
����ѡ�� agd �㷨��ѧϰ����:http://www.eecs.berkeley.edu/~brecht/papers/hogwildTR.pdf
1.4 ��������
����,���ǿ����������� lr_driver.cpp,������:
- �������л�����ͨ�š�
- ��ȡ����������
- ���� logistic_regression,����ѵ��,��֤,Ԥ�⡣
DEFINE_string(server_info,
"host1:7777PARACELhost2:8888",
"hosts name string of paracel-servers.\n");
DEFINE_string(cfg_file,
"",
"config json file with absolute path.\n");
int main(int argc, char *argv[])
{
// �������л�����ͨ��
paracel::main_env comm_main_env(argc, argv);
paracel::Comm comm(MPI_COMM_WORLD);
google::SetUsageMessage("[options]\n\t--server_info\n\t--cfg_file\n");
google::ParseCommandLineFlags(&argc, &argv, true);
// ��ȡ��������
paracel::json_parser pt(FLAGS_cfg_file);
std::string training_input, test_input, predict_input, output, update_file, update_func, method;
try {
training_input = pt.check_parse<std::string>("training_input");
test_input = pt.check_parse<std::string>("test_input");
predict_input = pt.check_parse<std::string>("predict_input");
output = pt.parse<std::string>("output");
update_file = pt.check_parse<std::string>("update_file");
update_func = pt.parse<std::string>("update_func");
method = pt.parse<std::string>("method");
} catch (const std::invalid_argument & e) {
std::cerr << e.what();
return 1;
}
int rounds = pt.parse<int>("rounds");
double alpha = pt.parse<double>("alpha");
double beta = pt.parse<double>("beta");
bool debug = pt.parse<bool>("debug");
// ���� logistic_regression,����ѵ��,��֤,Ԥ��
paracel::alg::logistic_regression lr_solver(comm,
FLAGS_server_info,
training_input,
output,
update_file,
update_func,
method,
rounds,
alpha,
beta,
debug);
lr_solver.solve();
std::cout << "final loss: " << lr_solver.calc_loss() << std::endl;
lr_solver.test(test_input);
lr_solver.predict(predict_input);
lr_solver.dump_result();
return 0;
}
��֮ǰ������������֪�����²�����:
"update_file" : "your_paracel_install_path/lib/liblr_update.so",
"update_func" : "lr_theta_update",
�������Ǵ� alg/classification/logistic_regression/update.cpp �еõ����º�������:
������Ǻϲ���������Ȼ�ء��ⲿ�ִ��뱻����ɿ�,��server֮�б��������С�
#include <vector>
#include "proxy.hpp"
#include "paracel_types.hpp"
using std::vector;
extern "C" {
extern paracel::update_result lr_theta_update;
}
vector<double> local_update(vector<double> a, vector<double> b) {
vector<double> r;
for(int i = 0; i < (int)a.size(); ++i) {
r.push_back(a[i] + b[i]);
}
return r;
}
paracel::update_result lr_theta_update = paracel::update_proxy(local_update);
1.5 �㷨����
1.5.1 �ඨ��
logistic_regression ���ඨ��,λ��lr.hpp��logistic_regression ��Ҫ�̳� paracel::paralg ����ʹ�á�
namespace paracel {
namespace alg {
class logistic_regression: public paracel::paralg {
public:
logistic_regression(paracel::Comm,
string,
string _input,
string output,
string update_file_name,
string update_func_name,
string = "ipm",
int _rounds = 1,
double _alpha = 0.002,
double _beta = 0.1,
bool _debug = false);
virtual ~logistic_regression();
double lr_hypothesis(const vector<double> &);
void dgd_learning(); // distributed gradient descent learning
void ipm_learning(); // by default: iterative parameter mixtures learning
void downpour_learning(); // asynchronous gradient descent learning
void agd_learning(); // slow asynchronous gradient descent learning
virtual void solve();
double calc_loss();
void dump_result();
void print(const vector<double> &);
void test(const std::string &);
void predict(const std::string &);
private:
void local_parser(const vector<string> &, const char);
void local_parser_pred(const vector<string> &, const char);
private:
string input;
string update_file, update_func;
std::string learning_method;
int worker_id;
int rounds;
double alpha, beta;
bool debug = false;
vector<vector<double> > samples, pred_samples;
vector<double> labels;
vector<double> theta;
vector<double> loss_error;
vector<std::pair<vector<double>, double> > predv;
int kdim; // not contain 1
};
} // namespace alg
} // namespace paracel
1.5.2 �������
solve ���������,���ݲ�ͬ����ѡ��ͬ������ݶ��½�����ѵ����
void logistic_regression::solve() {
auto lines = paracel_load(input);
local_parser(lines);
paracel_sync();
if(learning_method == "dgd") {
dgd_learning();
} else if(learning_method == "ipm") {
ipm_learning();
} else if(learning_method == "downpour") {
downpour_learning();
} else if(learning_method == "agd") {
agd_learning();
} else {
ERROR_ABORT("method do not support");
}
paracel_sync();
}
1.5.3 Agd�㷨
�����ҳ������е��㷨�ȶ�:

�������������㷨����һһ��Ӧ,�����¡�
- ���Ȱ� theta ���͵�����������;
- ����ѵ��:
- �Ӳ�����������ȡ���µ� theta;
- ����ѵ��;
- �Ѽ��������͵�����������;
- �Ӳ����������õ����½��;
void logistic_regression::agd_learning() {
int data_sz = samples.size();
int data_dim = samples[0].size();
theta = paracel::random_double_list(data_dim);
paracel_write("theta", theta); // first push // ���Ȱ� theta ���͵�����������
vector<int> idx;
for(int i = 0; i < data_sz; ++i) {
idx.push_back(i);
}
paracel_register_bupdate(update_file, update_func);
double coff2 = 2. * beta * alpha;
vector<double> delta(data_dim);
unsigned time_seed = std::chrono::system_clock::now().time_since_epoch().count();
// train loop
for(int rd = 0; rd < rounds; ++rd) {
std::shuffle(idx.begin(), idx.end(), std::default_random_engine(time_seed));
theta = paracel_read<vector<double> >("theta"); // �Ӳ�����������ȡ���µ� theta
vector<double> theta_old(theta);
// traverse data
for(auto sample_id : idx) {
theta = paracel_read<vector<double> >("theta");
theta_old = theta;
double coff1 = alpha * (labels[sample_id] - lr_hypothesis(samples[sample_id]));
for(int i = 0; i < data_dim; ++i) {
double t = coff1 * samples[sample_id][i] - coff2 * theta[i];
theta[i] += t;
}
if(debug) {
loss_error.push_back(calc_loss());
}
for(int i = 0; i < data_dim; ++i) {
delta[i] = theta[i] - theta_old[i];
}
// �Ѽ��������͵�����������
paracel_bupdate("theta", delta); // you could push a batch of delta into a queue to optimize
} // traverse
} // rounds
theta = paracel_read<vector<double> >("theta"); // last pull // �õ����ս��
}
lr����ͼ����:
+------------+ +-------------------------------------------------+
| lr_driver | |logistic_regression |
| | | |
| +---------------------------------------> solve |
+------------+ lr_solver.solve() | + |
| | |
| | |
| | |
| +---------------------+-----------------------+ |
| | agd_learning | |
| | +-----------------------+ | |
| | | | | |
| | | v | |
| | | theta = paracel_read("theta") | |
| | | | | |
| | | | | |
| | | v | |
| | | | |
| | | delta[i] = theta[i] - theta_old[i] | |
| | | + | |
| | | | | |
| | | | | |
| | | v | |
| | | paracel_bupdate("theta", delta) | |
| | | + + | |
| | | | | | |
| | +-----------------------+ | | |
| +---------------------------------------------+ |
| | |
+-------------------------------------------------+
|
Worker |
+------------------------------------------------------------------------------------+
Server |
+---------------------+
| Server | |
| | |
| v |
| local_update |
| |
+---------------------+
1.6 ��
����,����֪����Paracel���ʹ��,ʵ������driverΪ���Ľ���չ��,�û���Ҫ��д update�������㷨���������Ǿ��������˽��ú�Զ��
����Ŀǰ�м���������Ҫ���:
- Paracel ��ô�����˶��worker����ѵ��?
- Paracel ��ô�����˲���������?
- update ������α�ʹ��?
������Ҫͨ�����������������о���
0x02 ����
��ǰ����./prun.py -w 4 -p 2 -c cfg.json -m local your_paracel_install_path/bin/lr����������,paracel ͨ�� prun.py ����ϵͳ,�������Ƿ�������ű���
2.1 python�ű� prun.py
2.1.1 ���庯��
��������ʡ��һЩ���������,���紦������,������:
- ��������;
- ���� init_starter �õ��������server,worker,������һ����Ӧ�ַ���;
- ���� subprocess.Popen ����server,����server��ִ�г����� bin/start_server;
- ���� os.system ���� worker;
if __name__ == '__main__':
optpar = OptionParser()
# ʡ�Դ�������
(options, args) = optpar.parse_args()
nsrv = 1
nworker = 1
if options.parasrv_num:
nsrv = options.parasrv_num
if options.worker_num:
nworker = options.worker_num
if not options.method_server:
options.method_server = options.method
if not options.ppn_server:
options.ppn_server = options.ppn
if not options.mem_limit_server:
options.mem_limit_server = options.mem_limit
if not options.hostfile_server:
options.hostfile_server = options.hostfile
# ���� init_starter �õ��������server,worker,��������Ӧ�ַ���
server_starter = init_starter(options.method_server,
str(options.mem_limit_server),
str(options.ppn_server),
options.hostfile_server,
options.server_group)
worker_starter = init_starter(options.method,
str(options.mem_limit),
str(options.ppn),
options.hostfile,
options.worker_group)
#initport = random.randint(30000, 65000)
#initport = get_free_port()
initport = 11777
start_parasrv_cmd_lst = [server_starter, str(nsrv), os.path.join(PARACEL_INSTALL_PREFIX, 'bin/start_server --start_host'), socket.gethostname(), ' --init_port', str(initport)]
start_parasrv_cmd = ' '.join(start_parasrv_cmd_lst)
# ���� subprocess.Popen ����server,����server��ִ�г����� bin/start_server
procs = subprocess.Popen(start_parasrv_cmd, shell=True, preexec_fn=os.setpgrp)
try:
serverinfo = paracelrun_cpp_proxy(nsrv, initport)
entry_cmd = ''
if args:
entry_cmd = ' '.join(args)
alg_cmd_lst = [worker_starter, str(nworker), entry_cmd, '--server_info', serverinfo, '--cfg_file', options.config]
alg_cmd = ' '.join(alg_cmd_lst)
# ���� os.system ���� worker
os.system(alg_cmd)
os.killpg(procs.pid, 9)
except Exception as e:
logger.exception(e)
os.killpg(procs.pid, 9)
2.1.2 starter����
init_starter �������������ù���һ���ַ��������� paracel ������������ʽ:
The �Cm_server and -m options above refer to what type of cluster you use. Paracel support mesos clusters, mpi clusters and multiprocessers in a single machine.
��������ǰ��horovod���µ�֪ʶ����֪��,mpirun �ǿ�������������̡�
���֮ǰ��������,./prun.py -w 4 -p 2 -c cfg.json -m local your_paracel_install_path/bin/lr,����֪�� local ���� mpirun,����paracel ͨ�� mpirun �������� 4 �� lr ������
�����������:
def init_starter(method, mem_limit, ppn, hostfile, group):
'''Assemble commands for running paracel programs'''
starter = ''
if not hostfile:
hostfile = '~/.mpi/large.18'
if method == 'mesos':
if group:
starter = '%s/mrun -m %s -p %s -g %s -n ' % (PARACEL_INSTALL_PREFIX, mem_limit, ppn, group)
else:
starter = '%s/mrun -m %s -p %s -n ' % (PARACEL_INSTALL_PREFIX, mem_limit, ppn)
elif method == 'mpi':
starter = 'mpirun --hostfile %s -n ' % hostfile
elif method == 'local':
starter = 'mpirun -n '
else:
print 'method %s not supported.' % method
sys.exit(1)
return starter
2.2 ��ִ�г��� start_server
ǰ���ᵽ,server ִ�г����Ӧ���� bin/start_server��
���ǿ����乹�� src/CMakeLists.txt,�������ǿ���ȥ���� start_server.cpp��
add_library(comm SHARED comm.cpp) # ͨ����ؿ�
install(TARGETS comm LIBRARY DESTINATION lib)
add_library(scheduler SHARED scheduler.cpp # ����
install(TARGETS scheduler LIBRARY DESTINATION lib)
add_library(default SHARED default.cpp) # ȱʡ��
install(TARGETS default LIBRARY DESTINATION lib)
# ������Կ���start_server.cpp
add_executable(start_server start_server.cpp)
target_link_libraries(start_server ${Boost_LIBRARIES} ${CMAKE_DL_LIBS})
install(TARGETS start_server RUNTIME DESTINATION bin)
add_executable(paracelrun_cpp_proxy paracelrun_cpp_proxy.cpp)
target_link_libraries(paracelrun_cpp_proxy ${Boost_LIBRARIES} ${CMAKE_DL_LIBS})
install(TARGETS paracelrun_cpp_proxy RUNTIME DESTINATION bin)
2.3 ����������
src/start_server.cpp �Ƿ�����������롣
���֮ǰ��������,./prun.py -w 4 -p 2 -c cfg.json -m local your_paracel_install_path/bin/lr,����֪�� local ���� mpirun,����paracel ͨ�� mpirun �������� 2 �� start_server ����,������������������
#include <gflags/gflags.h>
#include "server.hpp"
DEFINE_string(start_host, "beater7", "host name of start node\n");
DEFINE_string(init_port, "7773", "init port");
int main(int argc, char *argv[])
{
google::SetUsageMessage("[options]\n\
--start_host\tdefault: balin\n\
--init_port\n");
google::ParseCommandLineFlags(&argc, &argv, true);
paracel::init_thrds(FLAGS_start_host, FLAGS_init_port); // join inside
return 0;
}
�� include/server.hpp �ļ�֮��,init_thrds ����������һϵ���߳�,���������¡�
- ���� zmq ����;
- Ϊÿ���߳̽�����socket;
- ���������������߳�;
- ����SSP�߳�;
- �ȴ��߳̽���;
// init_host is the hostname of starter
void init_thrds(const paracel::str_type & init_host,
const paracel::str_type & init_port) {
// ���� zmq ����
zmq::context_t context(2);
zmq::socket_t sock(context, ZMQ_REQ);
paracel::str_type info = "tcp://" + init_host + ":" + init_port;
sock.connect(info.c_str());
char hostname[1024], freeport[1024];
size_t size = sizeof(freeport);
// hostname of servers
gethostname(hostname, sizeof(hostname));
paracel::str_type ports = hostname;
ports += ":";
// create sock in every thrd Ϊÿ���߳̽�����socket
std::vector<zmq::socket_t *> sock_pt_lst;
for(int i = 0; i < paracel::threads_num; ++i) {
zmq::socket_t *tmp;
tmp = new zmq::socket_t(context, ZMQ_REP);
sock_pt_lst.push_back(tmp);
sock_pt_lst.back()->bind("tcp://*:*");
sock_pt_lst.back()->getsockopt(ZMQ_LAST_ENDPOINT, &freeport, &size);
if(i == paracel::threads_num - 1) {
ports += local_parse_port(paracel::str_type(freeport));
} else {
ports += local_parse_port(std::move(paracel::str_type(freeport))) + ",";
}
}
zmq::message_t request(ports.size());
std::memcpy((void *)request.data(), &ports[0], ports.size());
sock.send(request);
zmq::message_t reply;
sock.recv(&reply);
// ���������������߳� thrd_exec
paracel::list_type<std::thread> threads;
for(int i = 0; i < paracel::threads_num - 1; ++i) {
threads.push_back(std::thread(thrd_exec, std::ref(*sock_pt_lst[i])));
}
// ����ssp�߳� thrd_exec_ssp
threads.push_back(std::thread(thrd_exec_ssp, std::ref(*sock_pt_lst.back())));
// �ȴ��߳̽���
for(auto & thrd : threads) {
thrd.join();
}
for(int i = 0; i < paracel::threads_num; ++i) {
delete sock_pt_lst[i];
}
zmq_ctx_destroy(context);
} // init_thrds
./prun.py -w 4 -p 2 -c cfg.json -m local your_paracel_install_path/bin/lr �Ķ�Ӧ������ͼ��������:
prun.py
+
|
|
| +----------------+
| +--> | start_server |
v | +----------------+
server_starter = init_starter +--> mpirun -n 2 +----+
+ | +----------------+
| | | start_server |
| | | + |
| +--> | | |
v | | |
worker_starter = init_starter +--> mpirun -n 4 | | |
+ | v |
| | init_thrds |
| | + |
| | | |
+-------+----+--+-------+ | | |
| | | | | | |
| | | | | v |
v v v v | thrd_exec |
bin/lr bin/lr bin/lr bin/lr | + |
| | |
| | |
| | |
| v |
| thrd_exec_ssp |
+----------------+
2.4 ��
Ŀǰ����֪����,worker��server���ж���������ʽ,������ mpi �ķ�ʽ������������̡�
-
worker �˾���ͨ�� driver.cpp Ϊ����,����������̡�
-
server�˾���ͨ�� start_server Ϊ����,�����������,���Ƕ������(����������)�����һ����Ⱥ��
������Щ��ps-lite�dz����ơ�
��������Ҫ�ֱ�������������ɫ���ڲ���
0x03 Server����
ͨ��֮ǰps-lite����֪��,�������������ʹ�� KV �洢���������,���������Ƚ���KV�洢��
3.1 KV �洢
�� include/kv_def.hpp ������server ��ʹ�õ�KV�洢��
#include "paracel_types.hpp"
#include "kv.hpp"
namespace paracel {
paracel::kvs<paracel::str_type, int> ssp_tbl; // ����Э��ʵ�� SSP
paracel::kvs<paracel::str_type, paracel::str_type> tbl_store; // ��Ҫ��kv�洢
}
KV �洢�Ķ����� include/kv.hpp,����ʡ���˲��ִ��롣
���Կ�����,�������ܾ���ά�����ڴ�table,�ṩ��setϵ�к�����getϵ�к���,���е���Ҫ���� value, unique ��ʱ��,�Ͳ���hash����������
template <class K, class V> struct kvs {
public:
bool contains(const K & k) {
return kvdct.count(k);
}
void set(const K & k, const V & v) {
kvdct[k] = v;
}
void set_multi(const paracel::dict_type<K, V> & kvdict) {
for(auto & kv : kvdict) {
set(kv.first, kv.second);
}
}
boost::optional<V> get(const K & k) {
auto fi = kvdct.find(k);
if(fi != kvdct.end()) {
return boost::optional<V>(fi->second);
} else return boost::none;
}
bool get(const K & k, V & v) {
auto fi = kvdct.find(k);
if(fi != kvdct.end()) {
v = fi->second;
return true;
} else {
return false;
}
}
paracel::list_type<V>
get_multi(const paracel::list_type<K> & keylst) {
paracel::list_type<V> valst;
for(auto & key : keylst) {
valst.push_back(kvdct.at(key));
}
return valst;
}
void get_multi(const paracel::list_type<K> & keylst,
paracel::list_type<V> & valst) {
for(auto & key : keylst) {
valst.push_back(kvdct.at(key));
}
}
void get_multi(const paracel::list_type<K> & keylst,
paracel::dict_type<K, V> & valdct) {
valdct.clear();
for(auto & key : keylst) {
auto it = kvdct.find(key);
if(it != kvdct.end()) {
valdct[key] = it->second;
}
}
}
// ����ʹ���� hash ����
// gets(key) -> value, unique
boost::optional<std::pair<V, paracel::hash_return_type> >
gets(const K & k) {
if(auto v = get(k)) {
std::pair<V, paracel::hash_return_type> ret(*v, hfunc(*v));
return boost::optional<
std::pair<V, paracel::hash_return_type>
>(ret);
} else {
return boost::none;
}
}
// compare-and-set, cas(key, value, unique) -> True/False
bool cas(const K & k, const V & v, const paracel::hash_return_type & uniq) {
if(auto r = gets(k)) {
if(uniq == (*r).second) {
set(k, v);
return true;
} else {
return false;
}
} else {
kvdct[k] = v;
}
return true;
}
paracel::dict_type<K, V> getall() {
return kvdct;
}
private:
//std::tr1::unordered_map<K, V> kvdct;
paracel::dict_type<K, V> kvdct;
paracel::hash_type<V> hfunc;
};
3.2 ��������
thrd_exec �߳�ʵ���˲����������Ļ���������:�������worker�����IJ�ͬ�����������ش���(�־������KV�洢���д���),����:
- ����� ��pull�� ����,��ʹ�� paracel::tbl_store.get(key, result) ��ȡ����ֵ,Ȼ�ظ��û���
- ����� ��push�� ����,��ʹ�� paracel::tbl_store.set(key, msg[2]) �� KV �в������;
��Ҫע�����,����ʹ�����û������update����,��:
- ����dlopen_update_lambda�����û����õ�update������������,��ֵΪ update_f��
- ������"update������"bupdate"��������ʱ��,ʹ���û���update��������kv���д�����
����ɾ���˲��ַ�������롣
// thread entry
void thrd_exec(zmq::socket_t & sock) {
paracel::packer<> pk;
update_result update_f;
filter_result pullall_special_f;
filter_result remove_special_f;
// ����ʹ����dlopen_update_lambda�����û����õ�update������������,��ֵΪ update_f
auto dlopen_update_lambda = [&](const paracel::str_type & fn, const paracel::str_type & fcn) {
void *handler = dlopen(fn.c_str(), RTLD_NOW | RTLD_LOCAL | RTLD_NODELETE);
auto local = dlsym(handler, fcn.c_str());
update_f = *(std::function<paracel::str_type(paracel::str_type, paracel::str_type)>*) local;
dlclose(handler);
};
// ������
while(1) {
zmq::message_t s;
sock.recv(&s);
auto scrip = paracel::str_type(static_cast<const char *>(s.data()), s.size());
auto msg = paracel::str_split_by_word(scrip, paracel::seperator);
auto indicator = pk.unpack(msg[0]);
if(indicator == "pull") { // ����ǴӲ�����������ȡ����,��ֱ�ӷ���
auto key = pk.unpack(msg[1]);
paracel::str_type result;
auto exist = paracel::tbl_store.get(key, result); // ��ȡkv
if(!exist) {
paracel::str_type tmp = "nokey";
rep_send(sock, tmp);
} else {
rep_send(sock, result); // ����
}
}
if(indicator == "pull_multi") { // ��ȡ�������
paracel::packer<paracel::list_type<paracel::str_type> > pk_l;
auto key_lst = pk_l.unpack(msg[1]);
auto result = paracel::tbl_store.get_multi(key_lst);
rep_pack_send(sock, result);
}
if(indicator == "pullall") { // ��ȡ���в���
auto dct = paracel::tbl_store.getall();
rep_pack_send(sock, dct);
}
mutex.lock();
if(indicator == "push") { // �������
auto key = pk.unpack(msg[1]);
paracel::tbl_store.set(key, msg[2]);
bool result = true;
rep_pack_send(sock, result);
}
if(indicator == "push_multi") { // ����������
paracel::packer<paracel::list_type<paracel::str_type> > pk_l;
paracel::dict_type<paracel::str_type, paracel::str_type> kv_pairs;
auto key_lst = pk_l.unpack(msg[1]);
auto val_lst = pk_l.unpack(msg[2]);
assert(key_lst.size() == val_lst.size());
for(int i = 0; i < (int)key_lst.size(); ++i) {
kv_pairs[key_lst[i]] = val_lst[i];
}
paracel::tbl_store.set_multi(kv_pairs); //����kv
bool result = true;
rep_pack_send(sock, result);
}
if(indicator == "update" || indicator == "bupdate") { // ���²���
if(msg.size() > 3) {
if(msg.size() != 5) {
ERROR_ABORT("invalid invoke in server end");
}
// open request func
auto file_name = pk.unpack(msg[3]);
auto func_name = pk.unpack(msg[4]);
dlopen_update_lambda(file_name, func_name);
} else {
if(!update_f) {
dlopen_update_lambda("../local/build/lib/default.so",
"default_incr_i");
}
}
auto key = pk.unpack(msg[1]);
// ����ʹ���û���update��������kv���д���
std::string result = kv_update(key, msg[2], update_f);
rep_send(sock, result);
}
if(indicator == "remove") { // ɾ������
auto key = pk.unpack(msg[1]);
auto result = paracel::tbl_store.del(key);
rep_pack_send(sock, result);
}
mutex.unlock();
} // while
} // thrd_exec
����ͼ:
+--------------------------------------------------------------------------------------+
| thrd_exec |
| |
| +---------------------------------> while(1) |
| | + |
| | | |
| | | |
| | +----------+----------+--------+--+------+----------+---------+---------+ |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | v v v v v v v v |
| | |
| | pull pull_multi pullall push push_multi update bupdate remove |
| | + + + + + + + + |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | v v v v v v v v |
| | +----------+----------+--------+----+----+----------+---------+---------+ |
| | | |
| | | |
| | | |
| | | |
| +-----------------------------------------+ |
| |
+--------------------------------------------------------------------------------------+
3.3 ��
ĿǰΪֹ,���ǿ��Կ���,Paracel��ps-liteҲ������,������ά����һ���洢,������Ҳ���Դ����ͻ��˵�����
0x04 Worker����
Worker ��������ѵ���㷨�Ľ��̡���ǰ�������˽�,�㷨��Ҫ�̳�paracel::paralg����ʹ�ò������������ܡ�
namespace paracel {
namespace alg {
class logistic_regression: public paracel::paralg { .....
paracel::paralg �Ϳ�����Ϊ�Dz�����������API,���ߴ���,��������Ϳ�����
4.1 ���������� Paralg
Paralg���ṩParacel��Ҫ���ܵĻ�����,��������Ϊһ���㷨API��,���߶����API����
����ֻ�������Ա����,��ʱʡ���亯��ʵ�֡�����Ҫ����Ϊ:
- int stale_cache, clock, total_iters; ͬ����Ҫ
- paracel::Comm worker_comm; ͨ����,���� MPI ͨ��
- int nworker = 1; worker����Ŀ
- bool ssp_switch = false; �Ƿ��� SSP ģʽ
- parasrv *ps_obj; // ��������Ϊ����ʽ�IJ����������ࡣ
class paralg {
private:
class parasrv { // ���������Dz�����������
using l_type = paracel::list_type<paracel::kvclt>;
using dl_type = paracel::list_type<paracel::dict_type<paracel::str_type, paracel::str_type> >;
public:
parasrv(paracel::str_type hosts_dct_str) {
// init dct_lst
dct_lst = paracel::get_hostnames_dict(hosts_dct_str);
// init srv_sz
srv_sz = dct_lst.size();
// init kvm
for(auto & srv : dct_lst) {
paracel::kvclt kvc(srv["host"], srv["ports"]);
kvm.push_back(std::move(kvc));
}
// init servers
for(auto i = 0; i < srv_sz; ++i) {
servers.push_back(i);
}
// init hashring
p_ring = new paracel::ring<int>(servers);
}
virtual ~parasrv() {
delete p_ring;
}
public:
dl_type dct_lst;
int srv_sz = 1;
l_type kvm;
paracel::list_type<int> servers; // ����������б�
paracel::ring<int> *p_ring; // hash ring
}; // nested class parasrv
private:
int stale_cache, clock, total_iters; // ͬ����Ҫ
int clock_server = 0;
paracel::Comm worker_comm; //ͨ����,���� MPI ͨ��
paracel::str_type output;
int nworker = 1;
int rounds = 1;
int limit_s = 0;
bool ssp_switch = false;
parasrv *ps_obj; // ��������Ϊ����ʽ�IJ����������ࡣ
paracel::dict_type<paracel::default_id_type, paracel::default_id_type> rm;
paracel::dict_type<paracel::default_id_type, paracel::default_id_type> cm;
paracel::dict_type<paracel::default_id_type, paracel::default_id_type> dm;
paracel::dict_type<paracel::default_id_type, paracel::default_id_type> col_dm;
paracel::dict_type<paracel::str_type, paracel::str_type> keymap;
paracel::dict_type<paracel::str_type, boost::any> cached_para;
paracel::update_result update_f;
int npx = 1, npy = 1;
}
4.2 ����
��дһ��Paracel������Ҫ��paralg����������,���ұ�����дvirtual solve����������һЩ��SPMD iterfaces ���нӿڡ�
���Ǵ�֮ǰ LR ��ʵ�ֿ��Կ�����Ҫ�̳� paracel::paralg ��
class logistic_regression: public paracel::paralg
����˵,�û���solve��������ֱ�ӵ��� Paralg �ĺ�������ɻ������ܡ�
������ paracel::paracel_read Ϊ��,���Կ�����ʹ�� parasrv.kvm �Ĺ���,���Ǻ������������ parasrv��
template <class V>
V paracel_read(const paracel::str_type & key,
int replica_id = -1) {
if(ssp_switch) { // ���Ӧ��ssp,Ӧ����δ������������ľͽ��������ssp��δ���
V val;
if(clock == 0 || clock == total_iters) {
cached_para[key] = boost::any_cast<V>(ps_obj->
kvm[ps_obj->p_ring->get_server(key)].
pull<V>(key));
val = boost::any_cast<V>(cached_para[key]);
} else if(stale_cache + limit_s > clock) {
val = boost::any_cast<V>(cached_para[key]);
} else {
while(stale_cache + limit_s < clock) {
stale_cache = ps_obj->
kvm[clock_server].pull_int(paracel::str_type("server_clock"));
}
cached_para[key] = boost::any_cast<V>(ps_obj->
kvm[ps_obj->p_ring->get_server(key)].
pull<V>(key));
val = boost::any_cast<V>(cached_para[key]);
}
return val;
}
// ����ֱ�ӷ���
return ps_obj->kvm[ps_obj->p_ring->get_server(key)].pull<V>(key);
}
worker������:
+---------------------------------------------------------------------------+
| Algorithm |
| ^ +------------------------------v |
| | | |
| | | |
| | v |
| | +----------------------------+------------------------------+ |
| | | paracel_read | |
| | | | |
| | | ps_obj+>kvm[ps_obj+>p_ring+>get_server(key)].pull<V>(key) | |
| | | | |
| | +----------------------------+------------------------------+ |
| | | |
| | | |
| | | |
| | v |
| | Compute |
| | + |
| | | |
| | | |
| | v |
| | +---------------------------+-------------------------------+ |
| | | paracel_bupdate | |
| | | ps_obj->kvm[indx].bupdate | |
| | | | |
| | +---------------------------+-------------------------------+ |
| | | |
| | | |
| | | |
| | | |
| +-----<--------------------------+ |
| |
+---------------------------------------------------------------------------+
4.3 ��
Worker�˵Ļ���Ҳ����ps-lite,ͨ��read,pull�Ȳ���,��������������
0x05 Ring Hash
������������,Ring hash ��������һ����,�ݴ�,����չ�Ȼ�����ϵ��һ��,����:
parameter server ������һ������,ʹ�õ��Ǵ�ͳ��һ���Թ�ϣ�㷨,����key��server node id�����뵽һ��hash ring�С�
����ϧ����,ps-lite û���ṩ�ⲿ�ִ���,paracel ��Ȼ�� ring hash,��Ҳ����ȫ,����û�п�Դ�ݴ���һ���ԵȲ��֡�����ֻ�ܻ������д������ѧϰ������
5.1 ԭ��
����ֻ�Ǵ��½�����,�������ͬѧ����ȥ����������ϸ���¡�
���ֿڵļ�������������,һ���Թ�ϣ�ļ����ؼ�����:���ճ��õ�hash�㷨������Ӧ��key��ϣ��һ������2^32�η���Ͱ�Ŀռ���,��0 ~ (2^32)-1�����ֿռ䡣���ǿ��Խ���Щ����ͷβ����,�����һ���պϵĻ��Ρ�
��ͨ�װ�������,����ؼ������:�ڲ����������ʱ��,����������ſռ��Ѿ����ó���һ���̶��ķdz�������� 1~2^32(����Ҫ�ٸı�)�����������Է���Ϊ 1~2^32 ����һ��š�������������Ⱥ���Թ̶�������㷨���� (��Ϊ��ſռ����㷨����Ҫ����),����������ݵȱ仯ֻ��"�������" ��Ҫ����ʵ��ϵͳ��������Ӧ�����Ӷ�������ϵͳӰ���С��
5.2 ����
ring ����hash ����ʵ����,������Ҫ���ܾ��ǰ� ������ ���뵽 hash ring ֮��,�Լ���ring֮��ȡ����������
// T rep type of server name
template <class T>
class ring {
public:
ring(paracel::list_type<T> names) {
for(auto & name : names) {
add_server(name);
}
}
ring(paracel::list_type<T> names, int cp) : replicas(cp) {
for(auto & name : names) {
add_server(name);
}
}
void add_server(const T & name) {
//std::hash<paracel::str_type> hfunc;
paracel::hash_type<paracel::str_type> hfunc;
std::ostringstream tmp;
tmp << name;
auto name_str = tmp.str();
for(int i = 0; i < replicas; ++i) { //��ÿһ���������д���
std::ostringstream cvt;
cvt << i;
auto n = name_str + ":" + cvt.str();
auto key = hfunc(n); // ����name����һ��key
srv_hashring_dct[key] = name; //����value
srv_hashring.push_back(key); //��list��������
}
// sort srv_hashring
std::sort(srv_hashring.begin(), srv_hashring.end());
}
void remove_server(const T & name) {
//std::hash<paracel::str_type> hfunc;
paracel::hash_type<paracel::str_type> hfunc;
std::ostringstream tmp;
tmp << name;
auto name_str = tmp.str();
for(int i = 0; i < replicas; ++i) { // ��ÿ���������д���
std::ostringstream cvt;
cvt << i;
auto n = name_str + ":" + cvt.str();
auto key = hfunc(n);// ����name����һ��key
srv_hashring_dct.erase(key);// ɾ��value
auto iter = std::find(srv_hashring.begin(), srv_hashring.end(), key);
if(iter != srv_hashring.end()) {
srv_hashring.erase(iter); // ɾ��list�е�����
}
}
}
// TODO: relief load of srv_hashring_dct[srv_hashring[0]]
template <class P>
T get_server(const P & skey) {
//std::hash<P> hfunc;
paracel::hash_type<P> hfunc;
auto key = hfunc(skey);// ����name����һ��key
auto server = srv_hashring[paracel::ring_bsearch(srv_hashring, key)];//��ȡserver
return srv_hashring_dct[server];
}
private:
int replicas = 32;
// �ֱ���list��dict�洢
paracel::list_type<paracel::hash_return_type> srv_hashring;
paracel::dict_type<paracel::hash_return_type, T> srv_hashring_dct;
};
5.3 ʹ��
����ʹ�� paracel_read ����,���Է��ֵ���˳����
- ��ʹ�� ps_obj->p_ring->get_server(key) �õ��� key ��Ӧ�� ����������(���Ǵ�ring hash ����ȡ����ijһ������������);
- Ȼ�������������л�ȡ���� key ��Ӧ�� value;
V paracel_read(const paracel::str_type & key,
int replica_id = -1) {
......
ps_obj->kvm[ps_obj->p_ring->get_server(key)].pull<V>(key);
}
5.4 ��
�����Ǻ�ps-lite�IJ�֮ͬ��,������ring-hash��ά������һ����,�ݴ���,����� ������ ���뵽 hash ring ֮��,�Լ���ring֮��ȡ����������
0x06 �����������ӿ� parasrv
���ǰ�Ŀǰ������һ��,�ۺϿ�����
6.1 �����������ӿ� parasrv ����
���ʹ��ring hash,��Ҫ�� parasrv ˵��
����֪��,paralg �ǻ���API��,������ paralg �������¶��� �Լ� ������ ps_obj , ps_obj��һ�� parasrv ���͵�ʵ����
ע:���¶�����worker��ʹ�õ����͡�
// paralg �ڴ���
parasrv *ps_obj; // ��Ա��������,�����������ӿ�
paralg(paracel::str_type hosts_dct_str,
paracel::Comm comm,
paracel::str_type _output = "",
int _rounds = 1,
int _limit_s = 0,
bool _ssp_switch = false) : worker_comm(comm),
output(_output),
nworker(comm.get_size()),
rounds(_rounds),
limit_s(_limit_s),
ssp_switch(_ssp_switch) {
ps_obj = new parasrv(hosts_dct_str); // ��������������,һ��parasrv��ʵ��
init_output(_output);
clock = 0;
stale_cache = 0;
clock_server = 0;
total_iters = rounds;
if(worker_comm.get_rank() == 0) {
paracel::str_type key = "worker_sz";
(ps_obj->kvm[clock_server]).
push_int(key, worker_comm.get_size()); // ��ʼ��ʱ�ӷ�����
}
paracel_sync(); // mpi barrierͬ��һ��
}
6.2 �����������ӿ� parasrv ����
parasrv �Ķ�������,���� p_ring ���� ring ʵ��,ʹ�� p_ring = new paracel::ring<int>(servers) ������˹�����
����p_ring �� ring hash,kvm�Ǿ����kv�洢�б���
class parasrv {
using l_type = paracel::list_type<paracel::kvclt>;
using dl_type = paracel::list_type<paracel::dict_type<paracel::str_type, paracel::str_type> >;
public:
parasrv(paracel::str_type hosts_dct_str) {
// ��ʼ��host��Ϣ,srv��С,kvm,servers,ring hash
// init dct_lst
dct_lst = paracel::get_hostnames_dict(hosts_dct_str);
// init srv_sz
srv_sz = dct_lst.size();
// init kvm
for(auto & srv : dct_lst) {
paracel::kvclt kvc(srv["host"], srv["ports"]);
kvm.push_back(std::move(kvc));
}
// init servers
for(auto i = 0; i < srv_sz; ++i) {
servers.push_back(i);
}
// init hashring
p_ring = new paracel::ring<int>(servers); // ����
}
virtual ~parasrv() {
delete p_ring;
}
public:
dl_type dct_lst;
int srv_sz = 1;
l_type kvm; // ����KV�洢�ӿ�
paracel::list_type<int> servers;
paracel::ring<int> *p_ring; // ring hash
}; // nested class parasrv
kvm ��ʼ������:
// init kvm
for(auto & srv : dct_lst) {
paracel::kvclt kvc(srv["host"], srv["ports"]);
kvm.push_back(std::move(kvc));
}
6.3 KV�洢���ƽӿ�
kvclt �� kv control �ij���
ֻժȡ���ִ���,�����ҵ���Ӧ�ķ��������н�����
namespace paracel {
struct kvclt {
public:
kvclt(paracel::str_type hostname,
paracel::str_type ports) : host(hostname), context(1) {
ports_lst = paracel::str_split(ports, ',');
conn_prefix = "tcp://" + host + ":";
}
template <class V, class K>
bool pull(const K & key, V & val) { // �Ӳ�����������ȡ
if(p_pull_sock == nullptr) {
p_pull_sock.reset(create_req_sock(ports_lst[0]));
}
auto scrip = paste(paracel::str_type("pull"), key); // paracel::str_type
return req_send_recv(*p_pull_sock, scrip, val);
}
template <class K, class V>
bool push(const K & key, const V & val) { // ����������������
if(p_push_sock == nullptr) {
p_push_sock.reset(create_req_sock(ports_lst[1]));
}
auto scrip = paste(paracel::str_type("push"), key, val);
bool stat;
auto r = req_send_recv(*p_push_sock, scrip, stat);
return r && stat;
}
template <class V>
bool req_send_recv(zmq::socket_t & sock,
const paracel::str_type & scrip,
V & val) {
zmq::message_t req_msg(scrip.size());
std::memcpy((void *)req_msg.data(), &scrip[0], scrip.size());
sock.send(req_msg);
zmq::message_t rep_msg;
sock.recv(&rep_msg);
paracel::packer<V> pk;
if(!rep_msg.size()) {
ERROR_ABORT("paracel internal error!");
} else {
std::string data = paracel::str_type(
static_cast<char*>(rep_msg.data()),
rep_msg.size());
if(data == "nokey") return false;
val = pk.unpack(data);
}
return true;
}
private:
paracel::str_type host;
paracel::list_type<paracel::str_type> ports_lst;
paracel::str_type conn_prefix;
zmq::context_t context;
std::unique_ptr<zmq::socket_t> p_contains_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_pull_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_pull_multi_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_pullall_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_push_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_push_multi_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_update_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_bupdate_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_bupdate_multi_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_remove_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_clear_sock = nullptr;
std::unique_ptr<zmq::socket_t> p_ssp_sock = nullptr;
}; // struct kvclt
} // namespace paracel
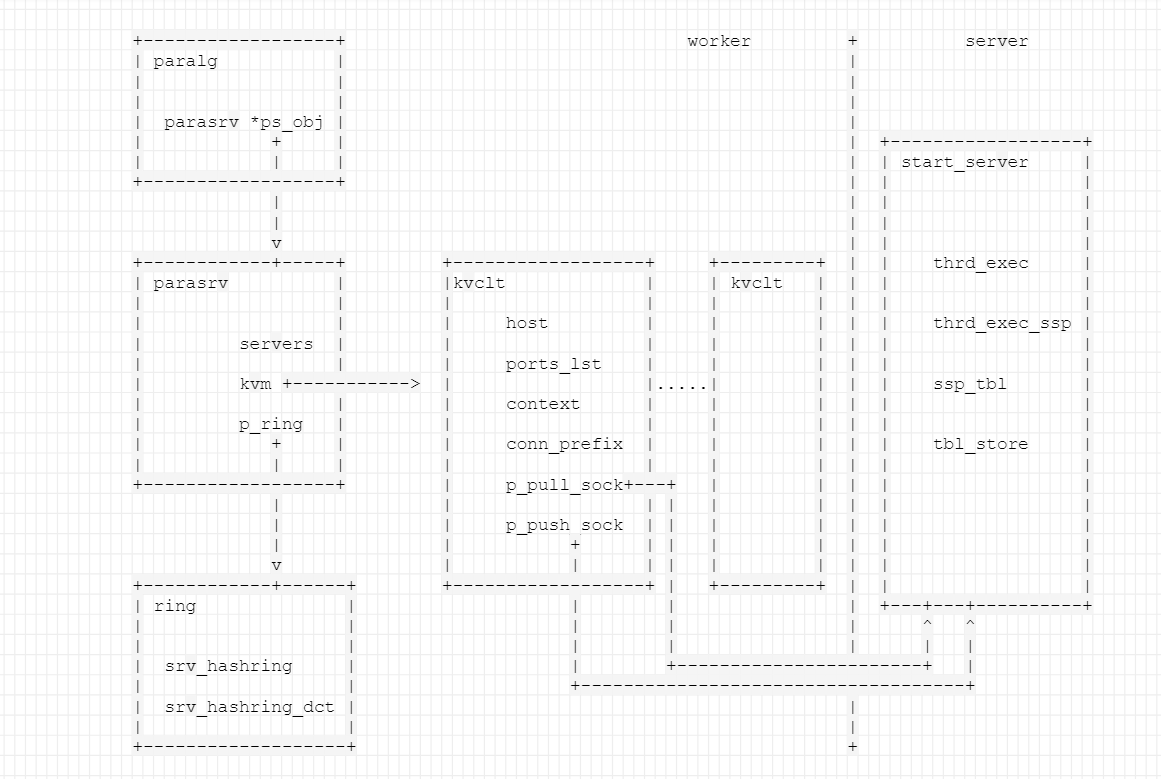
����Ŀǰ����������:
+------------------+ worker + server
| paralg | |
| | |
| | |
| parasrv *ps_obj | |
| + | | +------------------+
| | | | | start_server |
+------------------+ | | |
| | | |
| | | |
v | | |
+------------+-----+ +------------------+ +---------+ | | thrd_exec |
| parasrv | |kvclt | | kvclt | | | |
| | | | | | | | |
| | | host | | | | | thrd_exec_ssp |
| servers | | | | | | | |
| | | ports_lst | | | | | |
| kvm +-----------> | |.....| | | | ssp_tbl |
| | | context | | | | | |
| p_ring | | | | | | | |
| + | | conn_prefix | | | | | tbl_store |
| | | | | | | | | |
+------------------+ | p_pull_sock+---+ | | | | |
| | | | | | | | |
| | p_push_sock | | | | | | |
| | + | | | | | | |
v | | | | | | | | |
+------------+------+ +------------------+ | +---------+ | | |
| ring | | | | +---+---+----------+
| | | | | ^ ^
| | | | | | |
| srv_hashring | | +-----------------------+ |
| | +------------------------------------+
| srv_hashring_dct | |
| | |
+-------------------+ +
�ֻ�����:
0xEE ������Ϣ
��������������ͼ�����˼���������
�Ź����˺�:������˼��
������뼰ʱ�õ�����д���µ���Ϣ����,�����뿴�������Ƽ��ļ�������,�����ע��
