ИХФюв§Шы
ТпМЛиЙщ
ЯпадЛиЙщ
ЪБМфађСаЗжЮі
ЩёОЭјТч
self-attentionгыsoftmaxЕФЭЦЕМ
word2evc
ИУЦЊТлЮФЕФБГОА
word2evcЬсГіЕФЗНЗЈЮоЗЈЪЙгУШЋОжЕФЭГМЦаХЯЂ
ОиеѓЗжНтЗНЗЈдкДЪЖдЭЦРэЕФШЮЮёЩЯБэЯжКмВю
НщЩм
LSAКЭword2vec,вЛИіЪЧРћгУСЫШЋОжЬиеїЕФОиеѓЗжНтЗНЗЈ,вЛИіЪЧРћгУОжВПЩЯЯТЮФЕФЗНЗЈЁЃ
GloVeФЃаЭОЭЪЧНЋетСНжаЬиеїКЯВЂЕНвЛЦ№ЕФ,МДЪЙгУСЫгяСЯПтЕФШЋОжЭГМЦ(overall statistics)Ьиеї,вВЪЙгУСЫОжВПЕФЩЯЯТЮФЬиеї(МДЛЌЖЏДАПк)ЁЃЮЊСЫзіЕНетвЛЕуGloVeФЃаЭв§ШыСЫCo-occurrence Probabilities MatrixЁЃ
ЙиМќЕу
? ОиеѓЗжНтЕФДЪЯђСПбЇЯАЗНЗЈ
? ЛљгкЩЯЯТЮФЕФДЪЯђСПбЇЯАЗНЗЈ
? дЄбЕСЗДЪЯђСП
ИУЦЊТлЮФЕФГЩЙћ
? ЬсГіСЫвЛжжаТЕФДЪЯђСПбЕСЗФЃаЭЁЊЁЊGloVe
? дкЖрИіШЮЮёЩЯШЁЕУзюКУЕФНсЙћ
? ЙЋВМСЫвЛЯЕСадЄбЕСЗЕФДЪЯђСП
еЊвЊДѓвт
ЕБЧАДЪЯђСПбЇЯАФЃаЭФмЙЛЭЈЙ§ЯђСПЕФЫуЪѕМЦЫуВЖзНДЪжЎМфЯИЮЂЕФгяЗЈКЭгявхЙцТЩ,ЕЋЪЧетжжЙцТЩБГКѓЕФдРэВЛЧхГўЁЃОЗжЮі,ЮвУЧЗЂЯжСЫвЛаЉгажњгкетжжДЪЯђСПЙцТЩЕФЬиад,ВЂЛљгкДЪЬсГіСЫвЛжжаТЕФЖдЪ§ЫЋЯпадЛиЙщФЃаЭ,етжжФЃаЭФмЙЛРћгУШЋОжОиеѓЗжНтКЭОжВПЩЯЯТЮФЕФгХЕуРДбЇЯАДЪЯђСПЁЃЮвУЧЕФФЃаЭЭЈЙ§жЛдкЙВЯжОиеѓжаЕФЗЧ0ЮЛжУбЕСЗДяЕНИпаЇбЕСЗЕФФПЕФЁЃдкДЪЖдЭЦРэШЮЮёЩЯЕУЕН75%ЕФзМШЗТЪ,ВЂЧвдкЖрИіШЮЮёЩЯЕУЕНзюгХНсЙћЁЃ
ФЃаЭдРэ
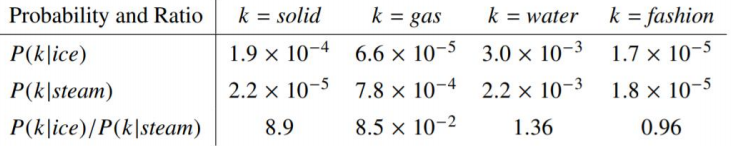

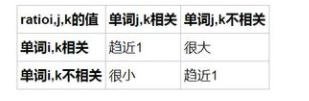
ФЃаЭЕФЙЋЪНЭЦЕМ
ЭЈЙ§eЕФxДЮЗНКЏЪ§ЪЧМѕЗЈБфГ§ЗЈ,МгЗЈБфГЫЗЈ,ЪЙВЮЪ§МѕЩй,БШШчЯТЭМжаЕФШ§ИіВЮЪ§БфСНИі,ИќКУЕиНјааМЦЫу(НЋАзЩЋВПЗжгыКкЩЋВПЗжЖдееПД)
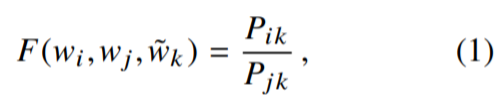
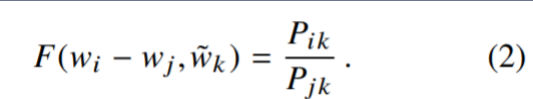
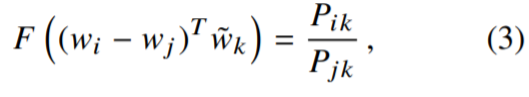
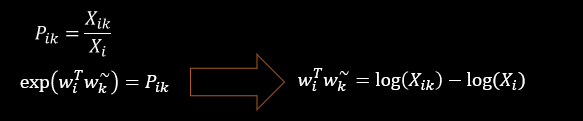
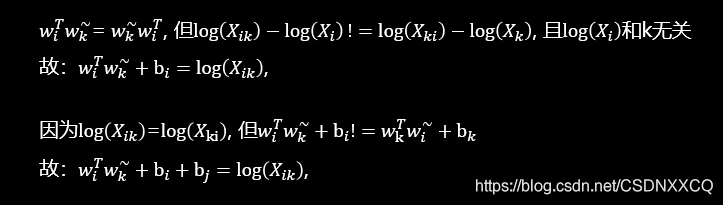
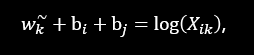
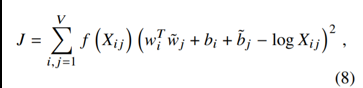
дРэ:ДЪЖдГіЯжДЮЪ§дНЖр,ФЧУДетСНИіДЪдкlossКЏЪ§жаЕФгАЯьдНДѓЁЃ
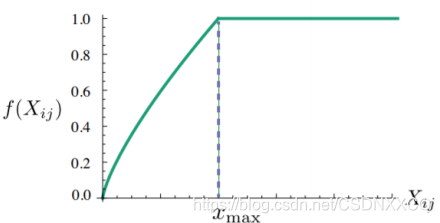
𝑓 (𝑋𝑖𝑗) ашвЊТњзу:
? 𝑋𝑖𝑗=0ЪБ, 𝑓 𝑋𝑖𝑗 =0:БэЪОУЛгаЙВЯжЙ§ЕФШЈжиЮЊ0,ВЛВЮМгбЕСЗ
? ЗЧМѕКЏЪ§,вђЮЊЙВЯжДЮЪ§дНЖр,ШЈжидНИп
? 𝑓 (𝑋𝑖𝑗) ВЛФмЮоЯожЦЕФДѓ,ЗРжЙЮовтвхДЪБШШч is,are,theЕФгАЯь
гкЪЧТлЮФШчДЫЩшМЦ𝑓 (𝑋𝑖𝑗)КЏЪ§,ГіЯжДЮЪ§ЖрЕФДЪЦфШЈжиВЛГЌЙ§1,НЕЕЭЦфгАЯь
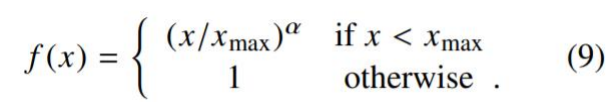
ФЃаЭаЇЙћЖдБШ

дкДЪЖдЭЦРэЕФЪ§ОнМЏЩЯШЁЕУСЫСМКУЕФаЇЙћ(ЭМжаФЃаЭжаЕФзюКУНсЙћ)
ЖрИіДЪЯрЫЦЖШШЮЮёЕФЪЕбщНсЙћ
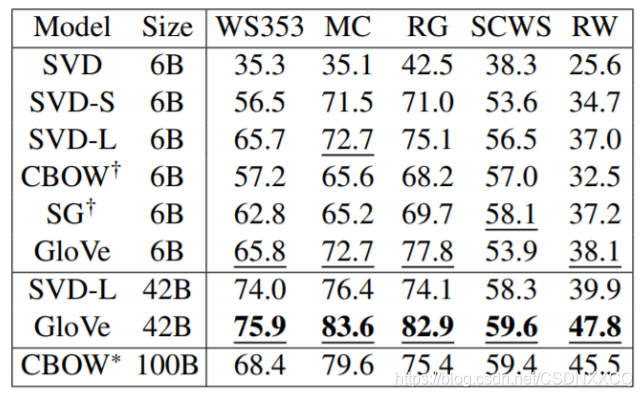
УќУћЪЕЬхЪЖБ№ШЮЮёЕФЪЕбщНсЙћ
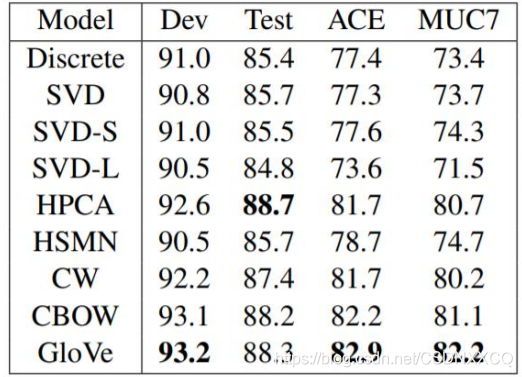
ЯђСПГЄЖШгыДАПкДѓаЁЖдНсЙћЕФгАЯь
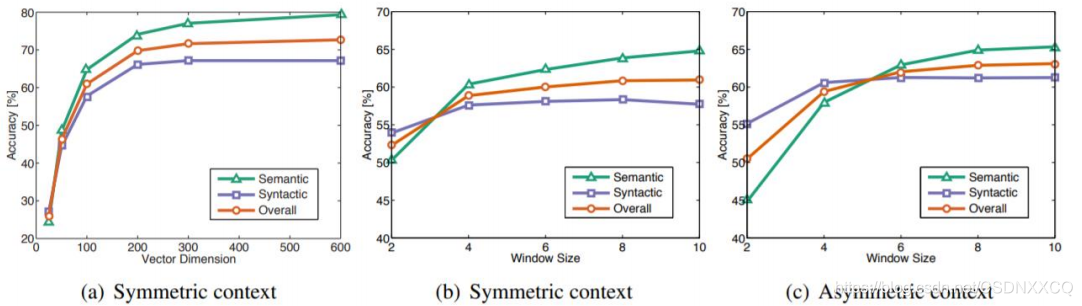
бЕСЗгяСЯЖдНсЙћЕФгАЯь
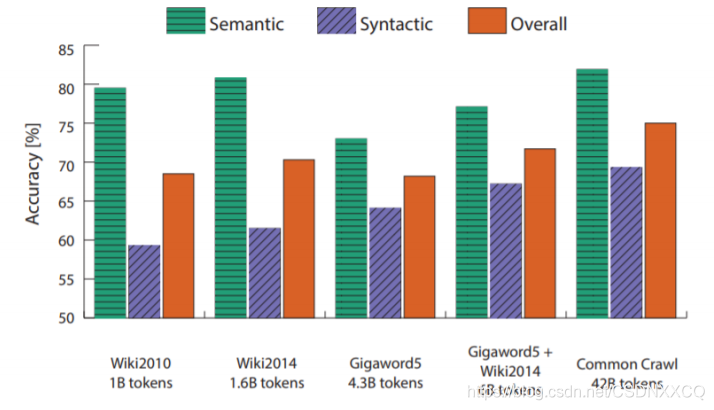
гыWord2vecЖдБШ
