Sarsa算法与Q-learning思考
Sarsa算法
它与Q-learning相当的相似,不同点在于Q-learning在现实值代入的是s2状态下的最大值,而Sarsa是选择在s2上实实在在走的动作a,这个a可能是所有动作里的最大值,也可能不是。
Sarsa算法我愿称之为说到做到型算法!
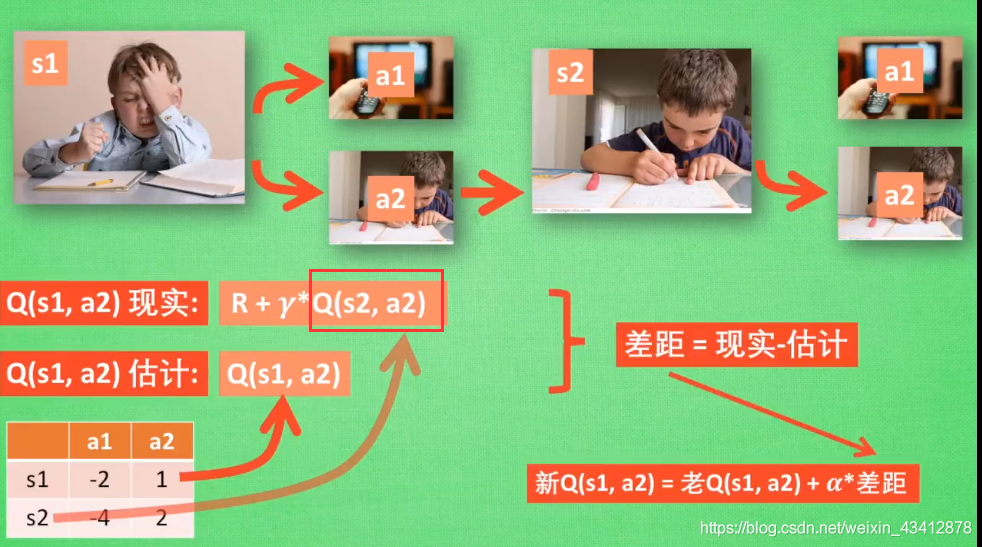
如果思考比较两种算法选择最大值与否对算法的后续影响的话,Sarsa训练学习到的孩子,更容易偏向获得更高利益的动作,比方说他通过一直执行a2学习动作最后得到了高回报,那么下一次他学习时,就更偏向一直做a2学习动作,即使学习10次看1次电视潜在回报更高,容易陷入“局部最优”
而Q-learning则更加的理性,能够执行理论上下一步的最优操作,消耗的资源可能更多,更容易达到全局最优吧。
但这里提到的“局部最优”其实并不是这么回事,因为只要迭代次数足够,算法基本上都会遍历每种情况,只是二者的学习过程有些不同而已。
Q-learning训练flappy bird的思考
本来学习完了Q学习算法就想要训练机器去玩flappy bird游戏(有点过于自信了hhh),但在游戏的开发中遇到了一些问题,在这里记录下来,日后如果能弄明白就继续来执行这个想法。

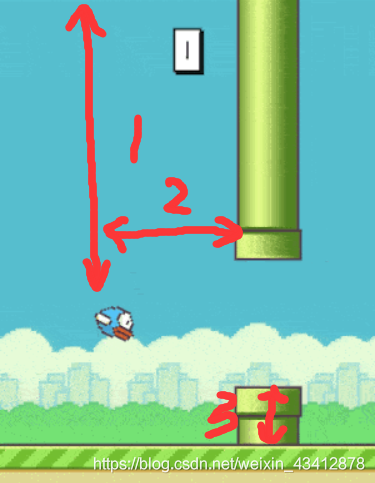
初步的想法是,这样的,首先Q表中的动作只有两种,一个是跳,一个是无操作,而这样的话,状态就有很多种了。我将状态取三个值来唯一的表示:
1.小鸟与天空的距离
2.小鸟与下一个障碍物的横向距离
3.障碍物的下边的高度(因为游戏中障碍的空隙相同,所以取一个高度就可以推断出障碍物全貌)
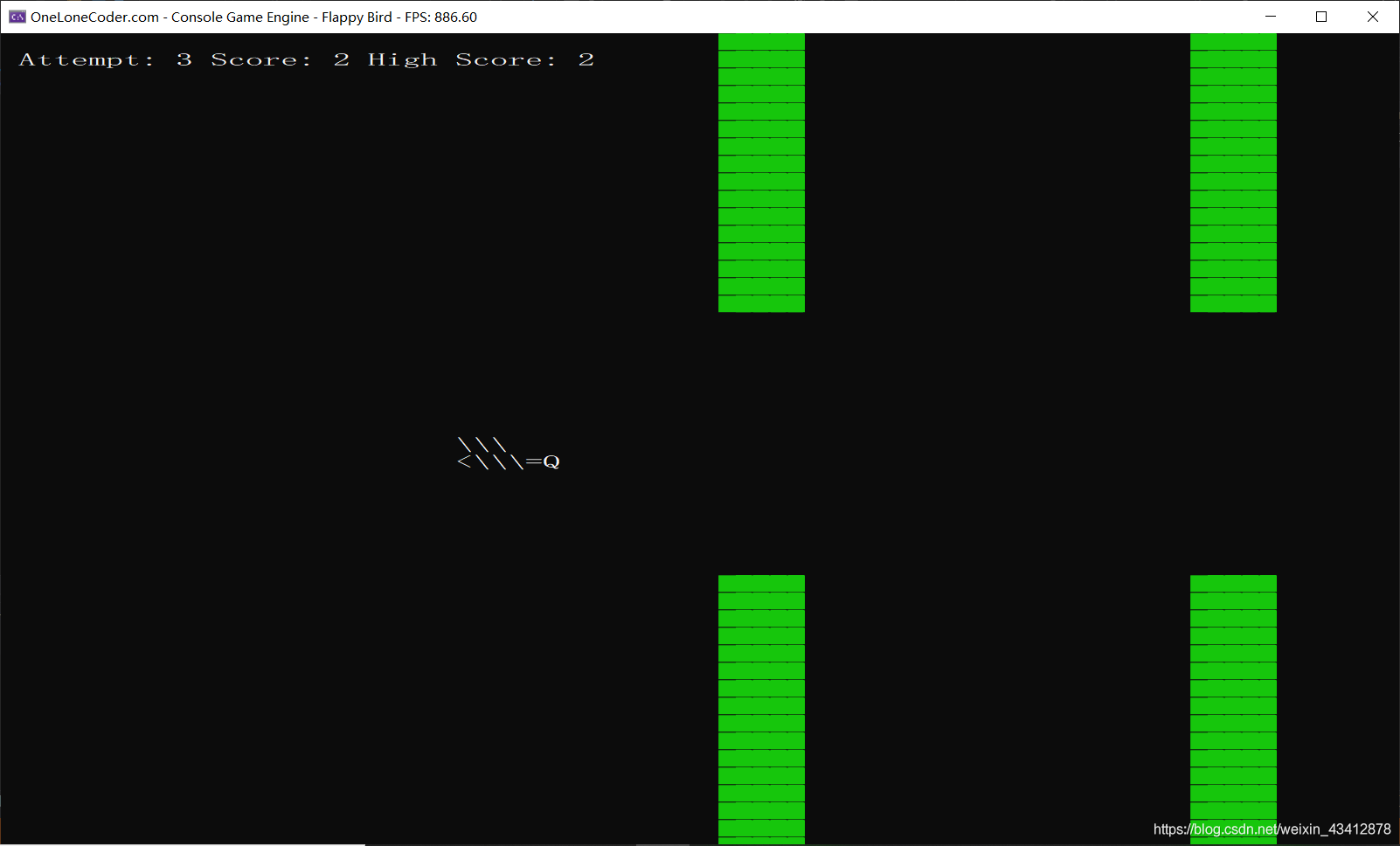
我用C++做了个简易的flappy bird游戏,并执行该策略,目前小鸟可以简单的通过学习自主控制是否按下space飞行。
但重要的问题是状态的选择,因为我这三个坐标的可选取值太多,导致状态s的数量呈爆发式增长(更何况我还简化了可选取值),所以电脑带的很慢,目前只训练到了第100代,小鸟能够自主学习的飞一飞,但还没能够越过第一个障碍物(这种情况越过障碍物基本就是靠蒙)
究其原因就是不能完全将所有可能的选区值录入,所以不能遍历全局情况,而如果遍历全局情况,算法的执行效率又会特别的慢!问题至此遇到瓶颈。
/-----------------------------手动分割线-----------------------------/
今天看了视频,发现可以通过深度学习的方法解决上述问题中状态数量爆炸的问题(这个问题也是Q学习普遍存在的算法瓶颈),具体原理就是通过输入当前情况下的三个值确定唯一状态,然后通过深度学习的一个"黑箱系统”得到一个简单的输出值,这个输出值作为当前状态,与Q学习算法进行配合,进行下一步的运算!