在弄毕设的时候,室友的毕设是基于DCGAN实现音乐的自动生成。那是第一次接触对抗神经网络,当时听室友的描述就是两个CNN,一个生成一个监测,在互相博弈。
最近我关注的一个大神在弄有关于GAN的东西,所以就跟着学了一下,蛮有意思的,和之前的深度学习略有不同。
1.导入库
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import glob
import sys,os,pathlib,imageio
2.基本原理
生成式对抗网络(GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。2014年由lanGoodfellow引入深度学习领域,被评价为“20年来深度学习领域最酷的想法”。
机器学习的模型大体上可分为两类,生成模型和判别模型。判别模型需要输入变量,通过某种模型来预测。生成模型是给定某种隐含信息,来随机产生观测数据。在之前的深度学习实验中,都是使用判别模型,来实现对某种事务的判别,例如:猫狗大战、鸟类识别、手写数字识别等。而生成模型接触的并不多。GAN是更好的生成模型。
GAN主要包括了两个部分:生成器generator与判别器discriminator。生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,从而骗过判别器。而判别器则需要对接收的图片进行真假判别。
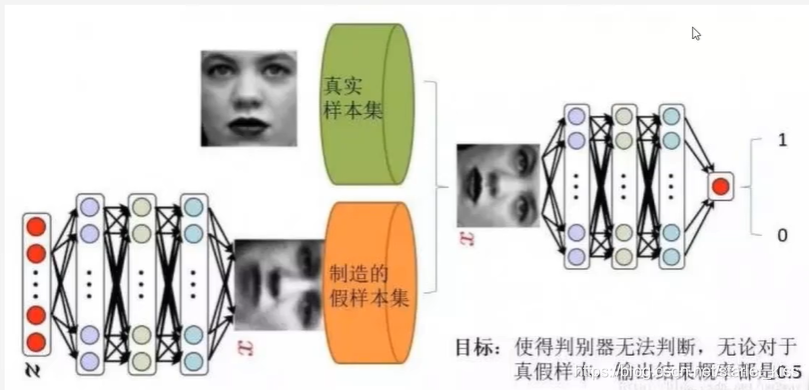
在训练过程中,生成器努力地令生成的图像更加真实,而判别器则努力地去识别图像的真假,这个过程相当于二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗。最终两个网络达到了一个动态均衡:生成器生成的图像接近于真是图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近0.5(相当于随机猜测类别)。
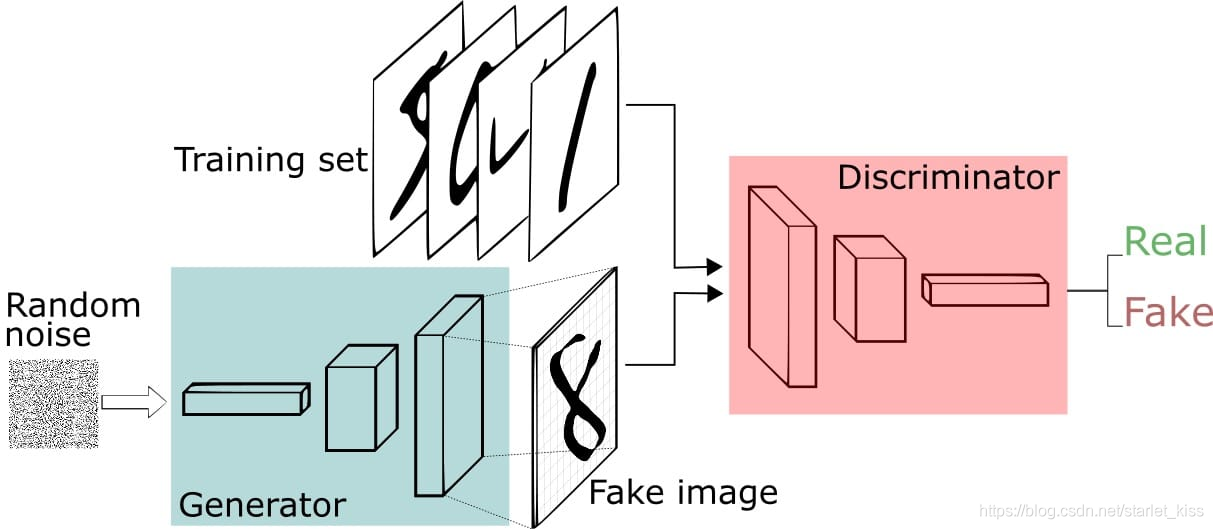
利用GAN生成手写数字识别的流程图如下所示:
对于给定的真实图片,判别器要为其打上标签1;
对于给定的生成图片,判别器要为其打上标签0;
对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签1.
GAN步骤:
1.生成器(Generator)接收随机数并返回生成图像。
2.将生成的数字图像与实际数据集中的数字图像一起送到鉴别器(Discriminator)。
3.鉴别器(Discriminator)接收真实和假图像并返回概率,0到1之间的数字,1表示真,0表示假。
3.数据准备
在这一阶段我们导入真实的手写数字,对其进行打乱、batch、归一化等操作。
(train_images,train_labels) ,(_,_) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0],28,28,1).astype('float32')
train_images = (train_images - 127.5)/127.5#归一化到[-1,1]之间
batch_size = 256
buffer_size = 60000
datasets = tf.data.Dataset.from_tensor_slices(train_images)
datasets = datasets.shuffle(buffer_size).batch(batch_size)
4.生成器与判别器的构建
def Generator_model():#最终生成28*28*1的图片
model = tf.keras.Sequential([
tf.keras.layers.Dense(256,input_shape=(100,)),#传入的数据为长度为100的随机向量
tf.keras.layers.BatchNormalization(),#归一化
tf.keras.layers.LeakyReLU(),#高级一点的Relu函数
tf.keras.layers.Dense(512),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dense(28*28*1,activation='tanh'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Reshape((28,28,1))#最后调整为(28,28,1)形状的数据,与手写数字的shape一致,作为生成器生成的图片
])
return model
def Discriminator_model():#判断图片是真正的图片还是生成的
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),#传入一张图片,将其展开成一维数组
tf.keras.layers.Dense(512),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dense(256),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return model
generator = Generator_model()
discriminator = Discriminator_model()
5.生成器与判别器的loss构建
判别器的loss值:判断真实图片为1的loss与判断生成图片为0的loss之和。因为判别器希望将真实图片判别为1,将生成图片判别为0.
生成器的loss值:判断生成图片为1的loss。因为生成器希望生成的图片是真实图片,即判别为1.
#生成器losses
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def Discriminator_loss(real_out,fake_out):
real_loss = cross_entropy(tf.ones_like(real_out),real_out)
fake_loss = cross_entropy(tf.zeros_like(fake_out), fake_out)
return real_loss+fake_loss
def Generator_loss(fake_out):
return cross_entropy(tf.ones_like(fake_out), fake_out)
Generator_opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
Discriminator_opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
参数设置
epochs = 100
noise_dim = 100
num_exp_to_generate = 16
seed = tf.random.normal([num_exp_to_generate,noise_dim])#16个长度为100的向量
6.批次训练
对一个batch_size的数据进行训练
def train_step(images):
noise = tf.random.normal([batch_size,noise_dim])#生成一个batch_size*noise_dim的数据,相当于生成了batch_size个长度为100的随机向量
with tf.GradientTape() as gen_tape,tf.GradientTape() as dis_tape:#两个Tape,一个代表生成器,一个代表判别器。
real_out = discriminator(images,training = True)#利用判别器对真实的图片进行训练,得到一个model
gen_image = generator(noise,training = True)#利用生成器对噪声数据生成图片
fake_out = discriminator(gen_image, training=True)#利用判别器对生成的图片进行训练
gen_loss = Generator_loss(fake_out)#利用判别器对生成图片的判断计算生成器的loss值
dis_loss = Discriminator_loss(real_out,fake_out)##利用判别器对生成图片和真实图片的判断计算判别器的loss值
gradient_gen = gen_tape.gradient(gen_loss,generator.trainable_variables)#根据生成器的loss值和网络模型计算梯度
gradient_dis = dis_tape.gradient(dis_loss, discriminator.trainable_variables)#根据判别器的loss值和网络模型计算梯度
Generator_opt.apply_gradients(zip(gradient_gen,generator.trainable_variables))#根据梯度对生成器进行梯度更新
Discriminator_opt.apply_gradients(zip(gradient_dis,discriminator.trainable_variables))#根据梯度对判别器进行梯度更新
7.训练&&可视化
def train(dataset,epochs):
for epoch in range(epochs):#一共训练epochs次
for image_batch in dataset:#对dataset中的每一个batch进行训练
train_step(image_batch)
print('.',end='')
print()
Generator_plot_image(generator,seed,epoch)#根据训练好的生成器,对之前生成的seed进行处理,生成图片
train(datasets,epochs)
def Generator_plot_image(gen_model,test_noise,epoch):
pre_images = gen_model(test_noise,training = False)#根据test_noise生成图片,生成器设置为不可训练
fig = plt.figure(figsize=(4,4))
for i in range(pre_images.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow((pre_images[i,:,:,0]+1)/2,cmap='gray')#之前归一化为[-1,1]之间,现在+1然后除以2,使之在[0,1]之间
plt.axis('off')
fig.savefig("E:/tmp/.keras/datasets/number_gen/%05d.png" % epoch)
plt.close()
生成图片如下所示:

8.生成动图
该模块参考大神K同学啊
def compose_gif():
# 图片地址
data_dir = "E:/tmp/.keras/datasets/number_gen"
data_dir = pathlib.Path(data_dir)
paths = list(data_dir.glob('*'))
gif_images = []
for path in paths:
print(path)
gif_images.append(imageio.imread(path))
imageio.mimsave("E:/tmp/.keras/datasets/test.gif", gif_images, fps=2)
compose_gif()
文件太大,csdn忍不了无法上传。

由于训练速度等原因,epochs设置的是100,最终展示的效果并不是很好,但是也可以看出生成的图片由一片模糊向逐渐清晰的过渡。
努力加油a啊
