前言
- 希望保研顺顺利利的,好慌=.=
- csdn啥时候支持代码折叠啊啊啊啊啊
- 使用windows10+CPU+pycharm+tensorflow.keras+python搭建简单的卷积神经网络模型,并进行猫狗分类
- 数据来源于kaggle-cat vs. dog,包含train和test两个文件夹,train中图像有标签,test中无标签
正文
导入相应的文件处理、数据处理、深度学习、机器学习的库
- 主要是
pandas, numpy, keras, tensorflow.keras, sklearn, random, os(keras和tensorflow.keras的区别?建议使用tensorflow.keras) - 源码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator, load_img
from keras.utils import to_categorical
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D,\
Dropout, Flatten, Dense, Activation, BatchNormalization
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
import random
import os
标记数据标签
- 定义关于训练集和验证集图像的信息
- 此处图像命名规则为:cat/dog.*.jpg,所以将数据集与标签对应好,得到
pd.DataFrame数据 - 源码:
FAST_RUN = False
image_width = 128
image_height = 128
image_channels = 3
image_size = (image_width, image_height)
input_shape = (image_width, image_height, image_channels)
filenames = os.listdir('train')
random.shuffle(filenames)
categories = []
for filename in filenames:
categories.append(filename.split('.')[0])
df = pd.DataFrame({
'filename': filenames,
'category': categories
})
搭建卷积神经网络模型
- 该神经网络模型总计有四层:(卷积层+最大池化层)x2、全连接层x1、输出层softmax,此处为二分类问题输出层可以使用sigmoid激活函数,模型如下图所示:
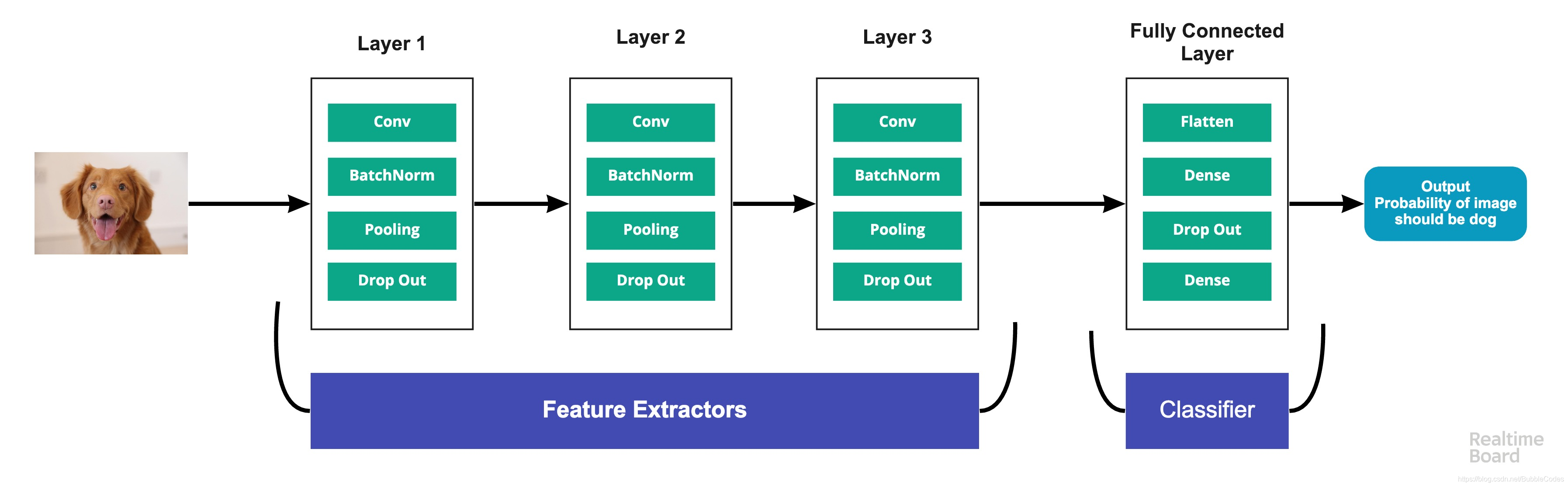 - 每层都使用
dropout防止过拟合;并且使用BatchNormalizationj加速了网络训练速度、提高网络的鲁棒性;优化算法使用adam算法 - 源码:
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 126, 126, 32) 896
_________________________________________________________________
batch_normalization (BatchNo (None, 126, 126, 32) 128
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 63, 63, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 63, 63, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 61, 61, 64) 18496
_________________________________________________________________
batch_normalization_1 (Batch (None, 61, 61, 64) 256
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 30, 30, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 30, 30, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 57600) 0
_________________________________________________________________
dense (Dense) (None, 512) 29491712
_________________________________________________________________
batch_normalization_2 (Batch (None, 512) 2048
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 29,514,562
Trainable params: 29,513,346
Non-trainable params: 1,216
数据增强
- 使用
sklearn.model_selection.train_test.split将数据集划分为训练集和验证集 - 这里有个点不太明白,
ImageDataGenerator和ImageDataGenerator.flow_from_dataframe如何区分,或者说,二者具体的职能是什么?按照名字来看,ImageDataGenerator是一个增强图像生成器,而调用ImageDataGenerator.flow_from_dataframe的过程就像是把图像喂给生成器然后产生增强后的图像,详情见keras中文文档 - 回调函数是
- 源码:
train_df, validate_df = train_test_split(df, test_size=0.2, random_state=42)
train_df = train_df.reset_index(drop=True)
validate_df = validate_df.reset_index(drop=True)
total_train = train_df.shape[0]
total_validate = validate_df.shape[0]
batch_size = 15
train_datagen = ImageDataGenerator(
rotation_range=15,
rescale=1./255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1
)
train_genertor = train_datagen.flow_from_dataframe(
train_df,
'train',
x_col='filename',
y_col='category',
target_size=image_size,
class_mode='categorical',
batch_size=batch_size
)
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_dataframe(
validate_df,
'train',
x_col='filename',
y_col='category',
target_size=image_size,
class_mode='categorical',
batch_size=batch_size
)
模型训练
- 模型训练需要:训练集、验证集、总迭代次数、批量数、回调函数列表(训练时使用)
- 在训练时出现警告
WARNING:tensorflow:Reduce LR on plateau conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr,有人说是验证集太小导致的 - 一个epoch大概训练10多分钟,用CPU训练了一晚上=.=,如果只是想练习,建议把
FAST_RUN = True - 源码:
epochs = 3 if FAST_RUN else 50
early_stop = EarlyStopping(patience=10)
learn_rate_reduction = ReduceLROnPlateau(monitor='val_acc', patience=2,
verbose=1, factor=0.5, min_lr=0.00001)
callbacks = [early_stop, learn_rate_reduction]
history = model.fit_generator(
train_genertor,
epochs=epochs,
validation_data=validation_generator,
validation_steps=total_validate//batch_size,
steps_per_epoch=total_train//batch_size,
callbacks=callbacks
)
model.save_weights('model.h5')
・・・
1333/1333 [==============================] - 685s 514ms/step - loss: 0.4195 - accuracy: 0.8084 - val_loss: 0.4752 - val_accuracy: 0.7862
Epoch 46/50
1333/1333 [==============================] - 681s 511ms/step - loss: 0.4291 - accuracy: 0.8017 - val_loss: 0.3621 - val_accuracy: 0.8432
WARNING:tensorflow:Reduce LR on plateau conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
Epoch 47/50
1333/1333 [==============================] - 679s 509ms/step - loss: 0.4165 - accuracy: 0.8087 - val_loss: 0.3811 - val_accuracy: 0.8308
WARNING:tensorflow:Reduce LR on plateau conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
Epoch 48/50
1333/1333 [==============================] - 687s 515ms/step - loss: 0.4407 - accuracy: 0.7967 - val_loss: 0.3781 - val_accuracy: 0.8374
WARNING:tensorflow:Reduce LR on plateau conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
Epoch 49/50
1333/1333 [==============================] - 689s 517ms/step - loss: 0.4129 - accuracy: 0.8113 - val_loss: 0.4771 - val_accuracy: 0.7722
WARNING:tensorflow:Reduce LR on plateau conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
Epoch 50/50
1333/1333 [==============================] - 680s 510ms/step - loss: 0.4152 - accuracy: 0.8113 - val_loss: 1.6649 - val_accuracy: 0.5908
WARNING:tensorflow:Reduce LR on plateau conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
Process finished with exit code 0
模型测试
- 用和得到训练集和验证集一样的方法得到测试集
- 使用
predict_genrator预测测试集 - 将结果存起来,最后转成
csv格式 - 源码:
test_filenames = os.listdir('test')
test_df = pd.DataFrame({
'filename': test_filenames
})
number_samples = test_df.shape[0]
test_gen = ImageDataGenerator(rescale=1./255)
test_generator = test_gen.flow_from_dataframe(
test_df,
'test',
x_col='filename',
y_col=None,
class_mode=None,
target_size=image_size,
batch_size=batch_size,
shuffle=False
)
predict = model.predict_generator(test_generator,
steps=np.ceil(number_samples/batch_size))
test_df['category'] = np.argmax(predict, axis=-1)
label_map = dict((v, k) for k, v in train_generator.class_indices.items())
test_df['category'] = test_df['category'].replace(label_map)
test_df['category'] = test_df['category'].replace({
'dog': 1,
'cat': 0
})
submission_df = test_df.copy()
submission_df['id'] = submission_df['filename'].str.split('.').str[0]
submission_df.drop(['filename', 'category'], axis=1, inplace=True)
submission_df.to_csv('submission.csv', index=False)
完整源码
import pandas as pd
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D,\
Dropout, Flatten, Dense, Activation, BatchNormalization
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
import random
import os
FAST_RUN = True
image_width = 128
image_height = 128
image_channels = 3
image_size = (image_width, image_height)
input_shape = (image_width, image_height, image_channels)
filenames = os.listdir('train')
random.shuffle(filenames)
categories = []
for filename in filenames:
categories.append(filename.split('.')[0])
df = pd.DataFrame({
'filename': filenames,
'category': categories
})
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
early_stop = EarlyStopping(patience=10)
learn_rate_reduction = ReduceLROnPlateau(monitor='val_acc', patience=2,
verbose=1, factor=0.5, min_lr=0.00001)
callbacks = [early_stop, learn_rate_reduction]
train_df, validate_df = train_test_split(df, test_size=0.2, random_state=42)
train_df = train_df.reset_index(drop=True)
validate_df = validate_df.reset_index(drop=True)
total_train = train_df.shape[0]
total_validate = validate_df.shape[0]
batch_size = 15
train_datagen = ImageDataGenerator(
rotation_range=15,
rescale=1./255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1
)
train_generator = train_datagen.flow_from_dataframe(
train_df,
'train',
x_col='filename',
y_col='category',
target_size=image_size,
class_mode='categorical',
batch_size=batch_size
)
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_dataframe(
validate_df,
'train',
x_col='filename',
y_col='category',
target_size=image_size,
class_mode='categorical',
batch_size=batch_size
)
epochs = 3 if FAST_RUN else 50
history = model.fit_generator(
train_generator,
epochs=epochs,
validation_data=validation_generator,
validation_steps=total_validate//batch_size,
steps_per_epoch=total_train//batch_size,
callbacks=callbacks
)
model.save_weights('model.h5')
test_filenames = os.listdir('test')
test_df = pd.DataFrame({
'filename': test_filenames
})
number_samples = test_df.shape[0]
test_gen = ImageDataGenerator(rescale=1./255)
test_generator = test_gen.flow_from_dataframe(
test_df,
'test',
x_col='filename',
y_col=None,
class_mode=None,
target_size=image_size,
batch_size=batch_size,
shuffle=False
)
predict = model.predict_generator(test_generator,
steps=np.ceil(number_samples/batch_size))
test_df['category'] = np.argmax(predict, axis=-1)
label_map = dict((v, k) for k, v in train_generator.class_indices.items())
print(label_map)
test_df['category'] = test_df['category'].replace(label_map)
test_df['category'] = test_df['category'].replace({
'dog': 1,
'cat': 0
})
submission_df = test_df.copy()
submission_df['id'] = submission_df['filename'].str.split('.').str[0]
submission_df.drop(['filename', 'category'], axis=1, inplace=True)
submission_df.to_csv('submission.csv', index=False)
总结
- 基本卷积神经网络的训练流程
- 以下问题对应python不熟悉的同学(比如我>.<)来说,肯定会经常搞不明白,下面是我的总结
os.listdir('.')
test_df['category'] = np.argmax(predict, axis=-1)
train_df.shape[0]
axis=0 vs. axis=1
index=False vs. index=True
inplace=False vs. inplace=True
参考
- kaggle
|