文章目录
GPT模型
GPT模型:生成式预训练模型(Generative Pre-Training)
总体结构:
无监督的预训练
有监督的下游任务精调
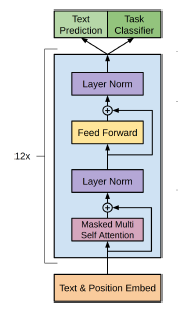
核心结构:中间部分主要由12个Transformer Decoder的block堆叠而成
下面这张图更直观地反映了模型的整体结构:
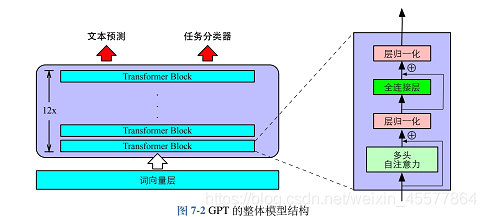
模型描述
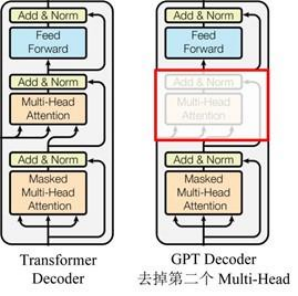
GPT 使用 Transformer的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
(很多资料上说类似于decoder结构,因为采用了decoder的mask机制,不过抛开这一点,其实感觉和encoder会更像,所以实现时有时反而是调encoder实现 莫烦Python GPT实现代码)
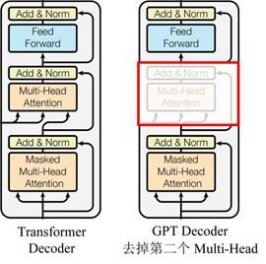
对比原有transformer的结构
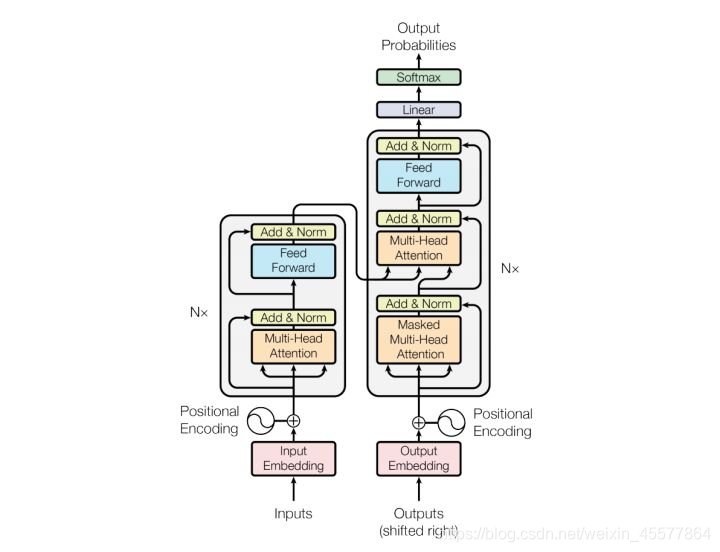
阶段描述
预训练阶段:



预训练阶段为文本预测,即根据已有的历史词预测当前时刻的词,7-2,7-3,7-4三个式子对应之前的GPT结构图,输出P(x)为输出,每个词被预测到的概率,再利用7-1式,计算最大似然函数,据此构造损失函数,即可以对该语言模型进行优化。
下游任务精调阶段

损失函数
下游任务与上游任务损失的线性组合

计算过程:
输入→embedding(词嵌入、位置嵌入等)→多层transformer的block→拿到两个输出端结果→计算损失、反向传播、更新参数
一个具体的GPT实例代码:
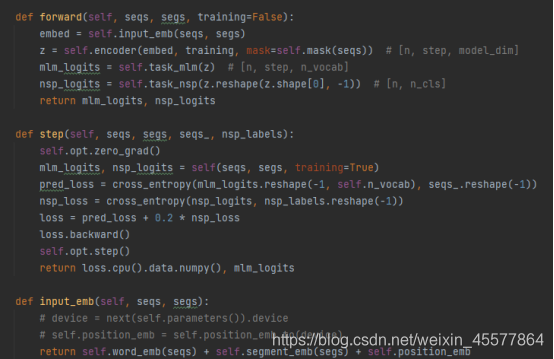
可以看到GPT模型的forward函数中,首先进行Embedding操作,然后经过12层transformer的block中进行运算,然后分别经过两个线性变换得到最终计算值(一个用于文本预测,一个用于任务分类器),代码与最开始展示的模型结构图保持一致。
参考:莫烦Python GPT实现代码
计算细节:
【Embedding层】:
查表操作
Embedding层就是以one hot为输入、中间层节点为字向量维数的全连接层。而这个全连接层的参数,就是一个“字向量表”。

one hot型的矩阵相乘,就像是相当于查表,于是它直接用查表作为操作,而不写成矩阵再运算,这大大降低了运算量。再次强调,降低了运算量不是因为词向量的出现,而是因为把one hot型的矩阵运算简化为了查表操作。
【GPT中类似transformer的decoder层】:
每个decoder层包含两个子层
- sublayer1: mask的多头注意力层
- sublayer2: ffn (feed-forward network)前馈网络(多层感知机)
sublayer1:mask的多头注意力层
输入: q, k, v, mask
计算注意力:Linear(矩阵乘法)→Scaled Dot-Product Attention→Concat(多个注意力的结果, reshape )→Linear(矩阵乘法)
残差连接和归一化操作:Dropout操作→残差连接→层归一化操作
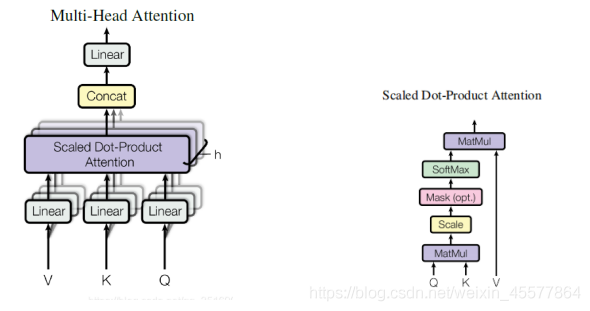
计算过程:
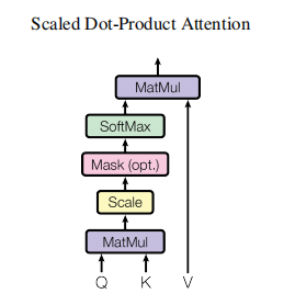
下面这段内容介绍了计算注意力的整体过程:

分解说明:
Mask Multi-head Attention
1.矩阵乘法:
将输入的q,k,v进行变换
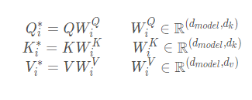
2.Scaled Dot-Product Attention
主要就是进行attention的计算以及mask的操作
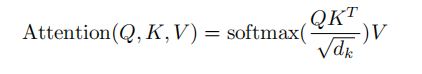
Mask操作:masked_fill_(mask, value)
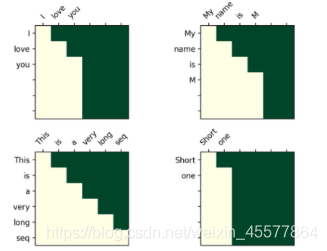
掩码操作,用value填充tensor中与mask中值为1位置相对应的元素。mask的形状必须与要填充的tensor形状一致。(这里采用-inf填充,从而softmax之后变成0,相当于看不见后面的词)
transformer中的mask操作
mask后可视化矩阵:
直观理解是每个词只能看到它之前的词(因为目的就是要预测未来的词嘛,要是看到了就不用预测了)
3.Concat操作:
综合多个注意力头的结果,实际上是对矩阵做变换:permute,reshape操作,降维。(如下图红框中所示)
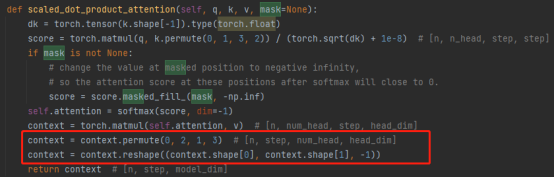
4.矩阵乘法:一个Linear层,对注意力结果线性变换
整个mask多头注意力层的代码:
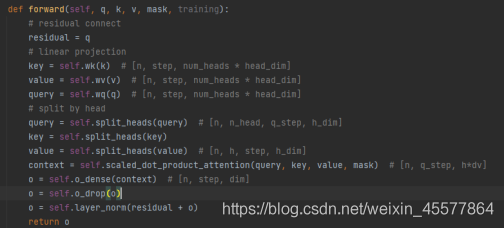
注意到:上述代码中后面几行是对注意力结果进行残差连接和归一化操作
下说明这一过程:
残差连接和归一化操作:
5.Dropout层
6.矩阵加法
7.层归一化
批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化。
输入归一化、批量归一化(BN)与层归一化(LN)
代码展示:
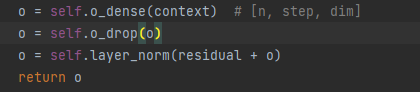
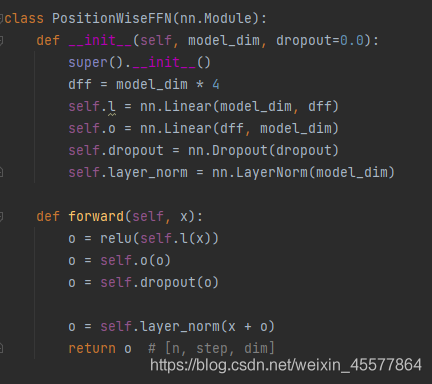
sublayer2: ffn (feed-forward network)前馈网络
1.线性层(矩阵乘法)
2.relu函数激活
3.线性层(矩阵乘法)
4.Dropout操作
5.层归一化
【线性层】:
多层block的输出结果放到两个线性层中进行变换,比较简单,不做赘述。
补充:注意力层流程图示
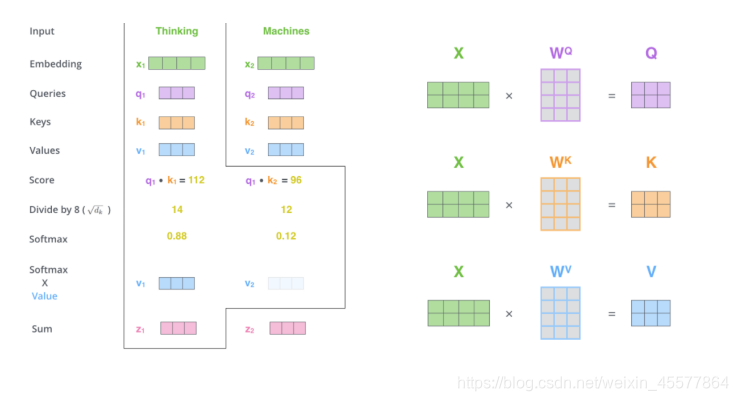
参考资料
1.参考论文:Radford et al. 《Improving Language Undersatnding by Generative Pre-Training"》
2.参考书籍:《自然语言处理 基于预训练模型的方法》车万翔,郭江,崔一鸣
3.本文中代码来源:莫烦Python GPT实现代码
4.其它参考链接(博文中已提到部分):
word embedding计算过程剖析
Transformer的矩阵维度分析和Mask详解