ФПТМ
-
Ъ§ОнМЏ
-
ПЩгУЪ§ОнМЏ
-
sklearnЪ§ОнМЏ
-
-
ЬиеїЬсШЁ
-
зжЕф
-
ЮФБО
-
-
ЬиеїдЄДІРэ
- ЮоСПИйЛЏ
- ЙщвЛЛЏ
- БъзМЛЏ
- ЮоСПИйЛЏ
-
ЬиеїНЕЮЌ
-
ЬиеїбЁдё
-
жїГЩЗжЗжЮі(PCAНЕЮЌ)
-
Ъ§ОнМЏ
ЯТУцСаОйСЫвЛаЉЪОР§РДЫЕУїФФаЉФкШнФмЫузїЪ§ОнМЏ:
-
АќКЌФГаЉЪ§ОнЕФБэИёЛђ CSV ЮФМў
-
зщжЏгаађЕФБэИёМЏКЯ
-
ВЩгУзЈгаИёЪНЕФЮФМў,ЦфжаАќКЌЪ§Он
-
ПЩЙВЭЌЙЙГЩФГИігавтвхЪ§ОнМЏЕФвЛзщЮФМў
-
АќКЌЦфЫћИёЪНЕФЪ§ОнЕФНсЙЙЛЏЖдЯѓ,ФњПЩФмЯЃЭћНЋЦфМгдиЕНЬиЪтЙЄОпжаНјааДІРэ
-
ВЖЛёЪ§ОнЕФЭМЯё
-
гыЛњЦїбЇЯАЯрЙиЕФЮФМў,ШчОЙ§бЕСЗЕФВЮЪ§ЛђЩёОЭјТчНсЙЙЖЈвх
-
ШЮКЮПДРДЯёЪ§ОнМЏЕФФкШн
sklearnЪЧвЛИіPythonЕкШ§ЗНЬсЙЉЕФЗЧГЃЧПСІЕФЛњЦїбЇЯАПт,ЫќАќКЌСЫДгЪ§ОндЄДІРэЕНбЕСЗФЃаЭЕФИїИіЗНУцЁЃдкЪЕеНЪЙгУscikit-learnжаПЩвдМЋДѓЕФНкЪЁЮвУЧБраДДњТыЕФЪБМфвдМАМѕЩйЮвУЧЕФДњТыСП,ЪЙЮвУЧгаИќЖрЕФОЋСІШЅЗжЮіЪ§ОнЗжВМ,ЕїећФЃаЭКЭаоИФГЌВЮЁЃ(sklearnЮЊАќУћ)
ЬиеїЬсШЁ
ФПБъ
-
гІгУDictVectorizerЪЕЯжЖдРрБ№ЬиеїНјааЪ§жЕЛЏЁЂРыЩЂЛЏ
-
гІгУCountVectorizerЪЕЯжЖдЮФБОЬиеїНјааЪ§жЕЛЏ
-
гІгУTfidfVectorizerЪЕЯжЖдЮФБОЬиеїНјааЪ§жЕЛЏ
-
ЫЕГіСНжжЮФБОЬиеїЬсШЁЕФЗНЪНЧјБ№
ЖЈвх
ЬиеїЬсШЁЪЧНЋШЮвтЪ§Он(ШчЮФБОЛђЭМЯё)зЊЛЛЮЊПЩгУгкЛњЦїбЇЯАЕФЪ§зжЬиеї
зЂ:ЬиеїжЕЛЏЪЧЮЊСЫМЦЫуЛњИќКУЕФШЅРэНтЪ§Он
-
зжЕфЬиеїЬсШЁ(ЬиеїРыЩЂЛЏ) -
ЮФБОЬиеїЬсШЁ -
ЭМЯёЬиеїЬсШЁ(ЩюЖШбЇЯА)
ЬиеїЬсШЁAPI
sklearn.feature_extraction
зжЕфЬиеїЬсШЁ
зїгУ:ЖдзжЕфЪ§ОнНјааЬиеїжЕЛЏ
- sklearn.feature_extraction.DictVectorizer(sparse=True,Ё)
- DictVectorizer.fit_transform(X) X:зжЕфЛђепАќКЌзжЕфЕФЕќДњЦї,ЗЕЛижЕ:ЗЕЛиsparseОиеѓ
- DictVectorizer.inverse_transform(X) X:arrayЪ§зщЛђепsparseОиеѓ ЗЕЛижЕ:зЊЛЛжЎЧАЪ§ОнИёЪН
- DictVectorizer.get_feature_names() ЗЕЛиРрБ№УћГЦ
гІгУ
ЖдвдЯТЪ§ОнНјааЬиеїЬсШЁ
data = [{'city': 'ББОЉ', 'temperature': 100}, {'city': 'ЩЯКЃ', 'temperature': 60}, {'city': 'Щюлк', 'temperature': 30}]
СїГЬЗжЮі
-
ЪЕР§ЛЏРрDictVectorizer
-
ЕїгУfit_transformЗНЗЈЪфШыЪ§ОнВЂзЊЛЛ(зЂвтЗЕЛиИёЪН)
def dict_demo():
"""
зжЕфЬиеїжЕЬсШЁ
:return:
"""
data = [{'city': 'ББОЉ', 'temperature': 100}, {'city': 'ЩЯКЃ', 'temperature': 60}, {'city': 'Щюлк', 'temperature': 30}]
# 1. ЪЕР§ЛЏвЛИізЊЛЛЦї ФЌШЯЗЕЛи sparseОиеѓ НЋЗЧ0жЕАДЮЛжУБэЪОГіРД вдНкЪЁФкДц ЬсИпМгдиаЇТЪ
transfer = DictVectorizer(sparse=False)
# гІгУГЁОА:Ъ§ОнМЏжаРрБ№ЬиеїжЕНЯЖр;НЋЪ§ОнМЏЕФЬиеї-ЁЗзжЕфРраЭ;DictVectorizerзЊЛЛ;БОЩэФУЕНЕФОЭЪЧзжЕф
# 2. ЕїгУfit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
print("ЬиеїУћзж:\n", transfer.get_feature_names())
return None

зЂвтЙлВьУЛгаМгЩЯsparse=FalseВЮЪ§ЕФНсЙћ

етИіНсЙћВЂВЛЪЧЯывЊПДЕНЕФ,ЫљвдМгЩЯВЮЪ§,ЕУЕНЯывЊЕФНсЙћ,дкетРяАбетИіДІРэЪ§ОнЕФММЧЩгУзЈвЕЕФГЦКє"one-hot"БрТыЁЃ
змНс
ЖдгкЬиеїЕБжаДцдкРрБ№аХЯЂЕФЖМЛсзіone-hotБрТыДІРэ
ЮФБОЬиеїЬсШЁ
зїгУ:ЖдЮФБОЪ§ОнНјааЬиеїжЕЛЏ
-
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- ЗЕЛиДЪЦЕОиеѓ
-
CountVectorizer.fit_transform(X) X:ЮФБОЛђепАќКЌЮФБОзжЗћДЎЕФПЩЕќДњЖдЯѓ ЗЕЛижЕ:ЗЕЛиsparseОиеѓ
-
CountVectorizer.inverse_transform(X) X:arrayЪ§зщЛђепsparseОиеѓ ЗЕЛижЕ:зЊЛЛжЎЧАЪ§ОнИё
-
CountVectorizer.get_feature_names() ЗЕЛижЕ:ЕЅДЪСаБэ
-
sklearn.feature_extraction.text.TfidfVectorizer
гІгУ
ЖдвдЯТЪ§ОнНјааЬиеїЬсШЁ
data = ["life is short, i like python", "life is too long i dislike python"]
СїГЬЗжЮі
-
ЪЕР§ЛЏРрCountVectorizer
-
ЕїгУfit_transformЗНЗЈЪфШыЪ§ОнВЂзЊЛЛ (зЂвтЗЕЛиИёЪН,РћгУtoarray()НјааsparseОиеѓзЊЛЛarrayЪ§зщ)
def count_demo():
"""
ЮФБОЬиеїжЕГщШЁ
:return:
"""
data = ["life is short, i like python", "life is too long i dislike python"]
# 1ЁЂЪЕР§ЛЏвЛИізЊЛЛЦїРр
transfer = CountVectorizer()
# бнЪОЭЃгУДЪ
# transfer = CountVectorizer(stop_words=["is", "too"])
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("ЬиеїУћзж:\n", transfer.get_feature_names())
# 2ЁЂЕїгУfit_transform
return None

ЮЪЬт:ШчЙћЮвУЧНЋЪ§ОнЬцЛЛГЩжаЮФ?
ЗЂЯжгЂЮФФЌШЯЪЧвдПеИёЗжПЊЕФЁЃЦфЪЕОЭДяЕНСЫвЛИіЗжДЪЕФаЇЙћ,ЫљвдЮвУЧвЊЖджаЮФНјааЗжДЪДІРэ
ЯТУцДњТыашвЊЬсЧААбЮФБОзіКУПеИёМфЯЖ
def count_chinese_demo():
"""
жаЮФЮФБОЬиеїжЕГщШЁ
:return:
"""
data = ["Юв АЎ ББОЉ ЬьАВУХ", "ЬьАВУХ ЩЯ ЬЋбє Щ§"]
data2 = ["ЮвАЎББОЉЬьАВУХ", "ЬьАВУХЩЯЬЋбєЩ§"]
# 1ЁЂЪЕР§ЛЏвЛИізЊЛЛЦїРр
transfer = CountVectorizer()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("ЬиеїУћзж:\n", transfer.get_feature_names())
# 2ЁЂЕїгУfit_transform
return None

ИќКУЕФДІРэЗНЪНМћЯТЗНАИ
jiebaЗжДЪДІРэ
- jieba.cut()
- ЗЕЛиДЪгязщГЩЕФЩњГЩЦї
ашвЊАВзАЯТjiebaПт
pip install jieba
АИР§ЗжЮі
data = ["дкЙ§ШЅСНИідТРя,ЮвКЭ60ЖрЮЛаЁЛяАщНјааСЫ1Жд1ЕФвЛаЁЪБЙЕЭЈ;",
"TAОјДѓЖрЪ§ЪЧЯывЊГЂЪдИБвЕБфЯжЕФХѓгбЁЃ",
"ДгвЛЯпГЧЪаЕНШ§ЯпГЧЪа,ДгБІТшЕНжАГЁШЫ,ДгжАГЁЕНЬхжЦФкЁЃ"]
ЗжЮі
-
зМБИОфзг,РћгУjieba.cutНјааЗжДЪ
-
ЪЕР§ЛЏCountVectorizer
-
НЋЗжДЪНсЙћБфГЩзжЗћДЎЕБзїfit_transformЕФЪфШыжЕ
def count_word(text):
"""
НјаажаЮФЗжДЪ ЮвАЎББОЉЬьАВУХ-ЁЗЮв АЎ ББОЉ ЬьАВУХ
:param text:
:return:
"""
a = " ".join(list(jieba.cut(text)))
print(a)
return a
def count_chinese_demo2():
"""
жаЮФЮФБОЬиеїжЕГщШЁ здЖЏЗжДЪ
:return:
"""
data = ["дкЙ§ШЅСНИідТРя,ЮвКЭ60ЖрЮЛаЁЛяАщНјааСЫ1Жд1ЕФвЛаЁЪБЙЕЭЈ;",
"TAОјДѓЖрЪ§ЪЧЯывЊГЂЪдИБвЕБфЯжЕФХѓгбЁЃ",
"ДгвЛЯпГЧЪаЕНШ§ЯпГЧЪа,ДгБІТшЕНжАГЁШЫ,ДгжАГЁЕНЬхжЦФкЁЃ"]
# 1ЁЂЪЕР§ЛЏвЛИізЊЛЛЦїРр
transfer = CountVectorizer(stop_words=["ДгБІТш"])
data_new = transfer.fit_transform(count_word(item) for item in data)
print("data_new:\n", data_new.toarray())
print("ЬиеїУћзж:\n", transfer.get_feature_names())
# 2ЁЂЕїгУfit_transform
return None

ЮЪЬт:ИУШчКЮДІРэФГИіДЪЛђЖЬгядкЖрЦЊЮФеТжаГіЯжЕФДЮЪ§ИпетжжЧщПі?
Tf-idfЮФБОЬиеїЬсШЁ
TF-IDFЕФжївЊЫМЯыЪЧ:ШчЙћФГИіДЪЛђЖЬгядквЛЦЊЮФеТжаГіЯжЕФИХТЪИп,ВЂЧвдкЦфЫћЮФеТжаКмЩйГіЯж,дђШЯЮЊДЫДЪЛђепЖЬгяОпгаКмКУЕФРрБ№ЧјЗжФмСІ,ЪЪКЯгУРДЗжРрЁЃ
TF-IDFзїгУ:гУвдЦРЙРвЛзжДЪЖдгквЛИіЮФМўМЏЛђвЛИігяСЯПтжаЕФЦфжавЛЗнЮФМўЕФживЊГЬЖШЁЃ
ЙЋЪН
ДЪЦЕ(term frequency,tf)жИЕФЪЧФГвЛИіИјЖЈЕФДЪгядкИУЮФМўжаГіЯжЕФЦЕТЪ
ФцЯђЮФЕЕЦЕТЪ(inverse document frequency,idf)ЪЧвЛИіДЪгяЦеБщживЊадЕФЖШСПЁЃФГвЛЬиЖЈДЪгяЕФidf,ПЩвдгЩзмЮФМўЪ§ФПГ§вдАќКЌИУДЪгяжЎ
ЮФМўЕФЪ§ФП,дйНЋЕУЕНЕФЩЬШЁвд10ЮЊЕзЕФЖдЪ§ЕУЕН
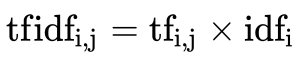
зюжеЕУГіНсЙћПЩвдРэНтЮЊживЊГЬЖШЁЃ
зЂ:МйШчвЛЦЊЮФМўЕФзмДЪгяЪ§ЪЧ100Иі,ЖјДЪгя"ЗЧГЃ"ГіЯжСЫ5ДЮ,ФЧУД"ЗЧГЃ"вЛДЪдкИУЮФМўжаЕФДЪЦЕОЭЪЧ5/100=0.05ЁЃЖјМЦЫуЮФМўЦЕТЪ(IDF)ЕФЗНЗЈЪЧвдЮФМўМЏЕФЮФМўзмЪ§,Г§вдГіЯж"ЗЧГЃ"вЛДЪЕФЮФМўЪ§ЁЃЫљвд,ШчЙћ"ЗЧГЃ"вЛДЪдк1,000ЗнЮФМўГіЯжЙ§,ЖјЮФМўзмЪ§ЪЧ10,000,000ЗнЕФЛА,ЦфФцЯђЮФМўЦЕТЪОЭЪЧlg(10,000,000 / 1,0000)=3ЁЃзюКѓ"ЗЧГЃ"ЖдгкетЦЊЮФЕЕЕФtf-idfЕФЗжЪ§ЮЊ0.05 * 3=0.15
АИР§
def tfidf_demo():
"""
гУTF-IDFЗНЗЈНјааЮФБОЬиеїжЕГщШЁ
:return:
"""
data = ["дкЙ§ШЅСНИідТРя,ЮвКЭ60ЖрЮЛаЁЛяАщНјааСЫ1Жд1ЕФвЛаЁЪБЙЕЭЈ;",
"TAОјДѓЖрЪ§ЪЧЯывЊГЂЪдИБвЕБфЯжЕФХѓгбЁЃ",
"ДгвЛЯпГЧЪаЕНШ§ЯпГЧЪа,ДгБІТшЕНжАГЁШЫ,ДгжАГЁЕНЬхжЦФкЁЃ"]
transfer = TfidfVectorizer(stop_words=["ДгБІТш"])
data_new = transfer.fit_transform(count_word(item) for item in data)
print("data_new:\n", data_new.toarray())
print("ЬиеїУћзж:\n", transfer.get_feature_names())
return None
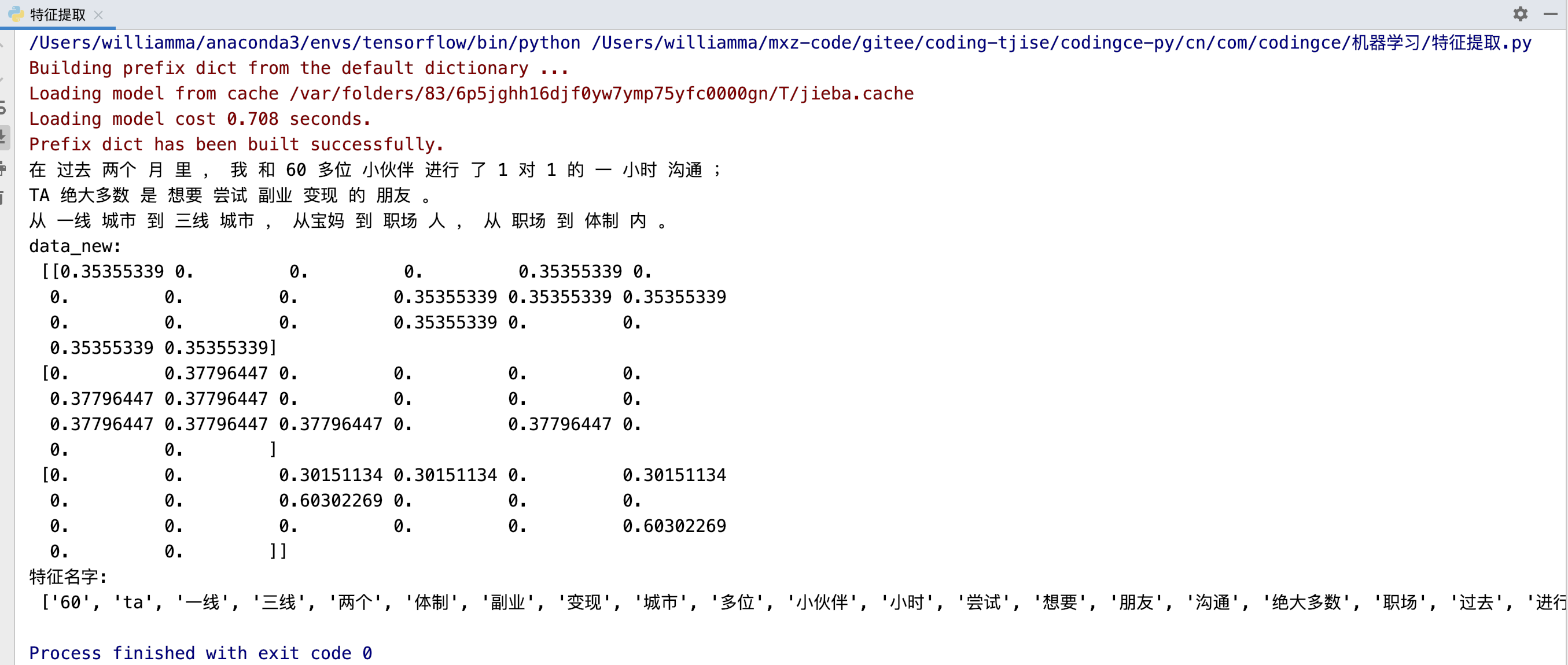
Tf-idfЕФживЊад
ЗжРрЛњЦїбЇЯАЫуЗЈНјааЮФеТЗжРржаЧАЦкЪ§ОнДІРэЗНЪН
ЬиеїдЄДІРэ
ФПБъ
-
СЫНтЪ§жЕаЭЪ§ОнЁЂРрБ№аЭЪ§ОнЬиЕу
-
гІгУMinMaxScalerЪЕЯжЖдЬиеїЪ§ОнНјааЙщвЛЛЏ
-
гІгУStandardScalerЪЕЯжЖдЬиеїЪ§ОнНјааБъзМЛЏ
ЪВУДЪЧЬиеїдЄДІРэ
ЬиеїдЄДІРэ:ЭЈЙ§вЛаЉзЊЛЛКЏЪ§НЋЬиеїЪ§ОнзЊЛЛГЩИќМгЪЪКЯЫуЗЈФЃаЭЕФЬиеїЪ§ОнЙ§ГЬ
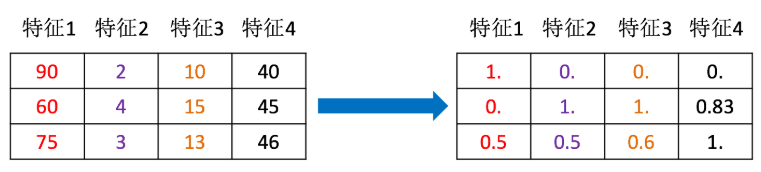
ПЩвдЭЈЙ§ЩЯУцФЧеХЭМРДРэНт
АќКЌФкШн
Ъ§жЕаЭЪ§ОнЕФЮоСПИйЛЏ:
-
ЙщвЛЛЏ
-
БъзМЛЏ
ЬиеїдЄДІРэAPI
sklearn.preprocessing
ЮЊЪВУДЮвУЧвЊНјааЙщвЛЛЏ/БъзМЛЏ?
ЬиеїЕФЕЅЮЛЛђепДѓаЁЯрВюНЯДѓ,ЛђепФГЬиеїЕФЗНВюЯрБШЦфЫћЕФЬиеївЊДѓГіМИИіЪ§СПМЖ,ШнвзгАЯь(жЇХф)ФПБъНсЙћ,ЪЙЕУвЛаЉЫуЗЈЮоЗЈбЇЯАЕНЦфЫќЕФЬиеї
ЮвУЧашвЊгУЕНвЛаЉЗНЗЈНјааЮоСПИйЛЏ,ЪЙВЛЭЌЙцИёЕФЪ§ОнзЊЛЛЕНЭЌвЛЙцИё
ЙщвЛЛЏ
ЖЈвх
ЭЈЙ§ЖддЪМЪ§ОнНјааБфЛЛАбЪ§ОнгГЩфЕН(ФЌШЯЮЊ[0,1])жЎМф
ЙЋЪН
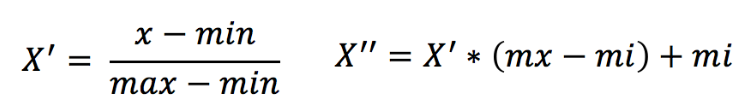
зїгУгкУПвЛСа,maxЮЊвЛСаЕФзюДѓжЕ,minЮЊвЛСаЕФзюаЁжЕ,ФЧУДXЁЏЁЏЮЊзюжеНсЙћ,mx,miЗжБ№ЮЊжИЖЈЧјМфжЕФЌШЯmxЮЊ1ЁЂmiЮЊ0
API
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)Ё )
- MinMaxScalar.fit_transform(X)
- X:numpy arrayИёЪНЕФЪ§Он[n_samples,n_features]
- ЗЕЛижЕ:зЊЛЛКѓЕФаЮзДЯрЭЌЕФarray
- MinMaxScalar.fit_transform(X)
Ъ§ОнМЦЫу
ЮвУЧЖдвдЯТЪ§ОнНјаадЫЫу,дкdating.txtжаЁЃБЃДцЕФОЭЪЧжЎЧАЕФдМЛсЖдЯѓЪ§Он
milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
ЗжЮі
-
ЪЕР§ЛЏMinMaxScalar
-
ЭЈЙ§fit_transformзЊЛЛ
def minmax_demo():
"""
ЙщвЛЛЏ
:return:
"""
# 1ЁЂЛёШЁЪ§Он
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print(data)
# 2ЁЂЪЕР§ЛЏвЛИізЊЛЛЦїРр
transform = MinMaxScaler()
# transform = MinMaxScaler(feature_range=[2, 3])
# 3ЁЂЕїгУfit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
return None

ЙщвЛЛЏзмНс
зЂвтзюДѓжЕзюаЁжЕЪЧБфЛЏЕФ,СэЭт,зюДѓжЕгызюаЁжЕЗЧГЃШнвзЪмвьГЃЕугАЯь,ЫљвдетжжЗНЗЈТГАєадНЯВю,жЛЪЪКЯДЋЭГОЋШЗаЁЪ§ОнГЁОАЁЃ
БъзМЛЏ
ЖЈвх
ЭЈЙ§ЖддЪМЪ§ОнНјааБфЛЛАбЪ§ОнБфЛЛЕНОљжЕЮЊ0,БъзМВюЮЊ1ЗЖЮЇФк
ЙЋЪН
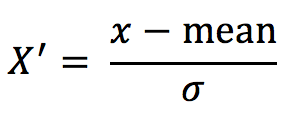
зїгУгкУПвЛСа,meanЮЊЦНОљжЕ,ІвЮЊБъзМВю
ЫљвдЛиЕНИеВХвьГЃЕуЕФЕиЗН,ЮвУЧдйРДПДПДБъзМЛЏ
-
ЖдгкЙщвЛЛЏРДЫЕ:ШчЙћГіЯжвьГЃЕу,гАЯьСЫзюДѓжЕКЭзюаЁжЕ,ФЧУДНсЙћЯдШЛЛсЗЂЩњИФБф
-
ЖдгкБъзМЛЏРДЫЕ:ШчЙћГіЯжвьГЃЕу,гЩгкОпгавЛЖЈЪ§ОнСП,ЩйСПЕФвьГЃЕу
-
ЖдгкЦНОљжЕЕФгАЯьВЂВЛДѓ,ДгЖјЗНВюИФБфНЯаЁЁЃ
API
- sklearn.preprocessing.StandardScaler( )
- ДІРэжЎКѓУПСаРДЫЕЫљгаЪ§ОнЖМОлМЏдкОљжЕ0ИННќБъзМВюВюЮЊ1
- StandardScaler.fit_transform(X)
- X:numpy arrayИёЪНЕФЪ§Он[n_samples,n_features]
- ЗЕЛижЕ:зЊЛЛКѓЕФаЮзДЯрЭЌЕФarray
Ъ§ОнМЦЫу
ЭЌбљЖдЩЯУцЕФЪ§ОнНјааДІРэ
[[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
ЗжЮі
-
ЪЕР§ЛЏStandardScaler
-
ЭЈЙ§fit_transformзЊЛЛ
def stand_demo():
"""
НјааБъзМЛЏ
дквбгабљБОзуЙЛЖрЕФЧщПіЯТ,ЪЪКЯЯждкрадгДѓЪ§ОнГЁОА
:return:
"""
# 1ЁЂЛёШЁЪ§Он
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print(data)
# 2ЁЂЪЕР§ЛЏвЛИізЊЛЛЦїРр
transform = StandardScaler()
# 3ЁЂЕїгУfit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
return None

БъзМЛЏзмНс
дквбгабљБОзуЙЛЖрЕФЧщПіЯТБШНЯЮШЖЈ,ЪЪКЯЯжДњрадгДѓЪ§ОнГЁОАЁЃ
ЬиеїНЕЮЌ
ФПБъ
-
жЊЕРЬиеїбЁдёЕФЧЖШыЪНЁЂЙ§ТЫЪНвдМААќЙќЪЯШ§жжЗНЪН
-
гІгУVarianceThresholdЪЕЯжЩОГ§ЕЭЗНВюЬиеї
-
СЫНтЯрЙиЯЕЪ§ЕФЬиЕуКЭМЦЫу
-
гІгУЯрЙиадЯЕЪ§ЪЕЯжЬиеїбЁдё
НЕЮЌ
НЕЮЌЪЧжИдкФГаЉЯоЖЈЬѕМўЯТ,НЕЕЭЫцЛњБфСП(Ьиеї)ИіЪ§,ЕУЕНвЛзщЁАВЛЯрЙиЁБжїБфСПЕФЙ§ГЬ
-
НЕЕЭЫцЛњБфСПЕФИіЪ§
-
ЯрЙиЬиеї(correlated feature):ЯрЖдЪЊЖШгыНЕгъСПжЎМфЕФЯрЙиЕШЕШ
е§ЪЧвђЮЊдкНјаабЕСЗЕФЪБКђ,ЮвУЧЖМЪЧЪЙгУЬиеїНјаабЇЯАЁЃШчЙћЬиеїБОЩэДцдкЮЪЬтЛђепЬиеїжЎМфЯрЙиадНЯЧП,ЖдгкЫуЗЈбЇЯАдЄВтЛсгАЯьНЯДѓ
НЕЮЌЕФСНжжЗНЪН
-
ЬиеїбЁдё
-
жїГЩЗжЗжЮі(ПЩвдРэНтвЛжжЬиеїЬсШЁЕФЗНЪН)
ЬиеїбЁдё
ЪВУДЪЧЬиеїбЁдё
ЖЈвх: Ъ§ОнжаАќКЌШпгрЛђЮоЙиБфСП(ЛђГЦЬиеїЁЂЪєадЁЂжИБъЕШ),жМдкДгдгаЬиеїжаевГіжївЊЬиеїЁЃ
ЗНЗЈ:
-
Filter(Й§ТЫЪН):жївЊЬНОПЬиеїБОЩэЬиЕуЁЂЬиеїгыЬиеїКЭФПБъжЕжЎМфЙиСЊ
- ЗНВюбЁдёЗЈ:ЕЭЗНВюЬиеїЙ§ТЫ
- ЯрЙиЯЕЪ§
-
Embedded (ЧЖШыЪН):ЫуЗЈздЖЏбЁдёЬиеї(ЬиеїгыФПБъжЕжЎМфЕФЙиСЊ)
- ОіВпЪї:аХЯЂьиЁЂаХЯЂдівц
- е§дђЛЏ:L1ЁЂL2
- ЩюЖШбЇЯА:ОэЛ§ЕШ
-
Wrapper (АќЙќЪН)
ФЃПщ
sklearn.feature_selection
Й§ТЫЪН
ЕЭЗНВюЬиеїЙ§ТЫ
ЩОГ§ЕЭЗНВюЕФвЛаЉЬиеї,ЧАУцНВЙ§ЗНВюЕФвтвхЁЃдйНсКЯЗНВюЕФДѓаЁРДПМТЧетИіЗНЪНЕФНЧЖШЁЃ
-
ЬиеїЗНВюаЁ:ФГИіЬиеїДѓЖрбљБОЕФжЕБШНЯЯрНќ
-
ЬиеїЗНВюДѓ:ФГИіЬиеїКмЖрбљБОЕФжЕЖМгаВюБ№
API
- sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
- ЩОГ§ЫљгаЕЭЗНВюЬиеї
- Variance.fit_transform(X)
- X:numpy arrayИёЪНЕФЪ§Он[n_samples,n_features]
- ЗЕЛижЕ:бЕСЗМЏВювьЕЭгкthresholdЕФЬиеїНЋБЛЩОГ§ЁЃФЌШЯжЕЪЧБЃСєЫљгаЗЧСуЗНВюЬиеї,МДЩОГ§ЫљгабљБОжаОпгаЯрЭЌжЕЕФЬиеїЁЃ
Ъ§ОнМЦЫу
ЮвУЧЖдФГаЉЙЩЦБЕФжИБъЬиеїжЎМфНјаавЛИіЩИбЁ
вЛЙВетаЉЬиеї
pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense
index,pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense,date,return
0,000001.XSHE,5.9572,1.1818,85252550922.0,0.8008,14.9403,1211444855670.0,2.01,20701401000.0,10882540000.0,2012-01-31,0.027657228229937388
1,000002.XSHE,7.0289,1.588,84113358168.0,1.6463,7.8656,300252061695.0,0.326,29308369223.2,23783476901.2,2012-01-31,0.08235182370820669
2,000008.XSHE,-262.7461,7.0003,517045520.0,-0.5678,-0.5943,770517752.56,-0.006,11679829.03,12030080.04,2012-01-31,0.09978900335112327
3,000060.XSHE,16.476,3.7146,19680455995.0,5.6036,14.617,28009159184.6,0.35,9189386877.65,7935542726.05,2012-01-31,0.12159482758620697
4,000069.XSHE,12.5878,2.5616,41727214853.0,2.8729,10.9097,81247380359.0,0.271,8951453490.28,7091397989.13,2012-01-31,-0.0026808154146886697
def variance_demo():
"""
Й§ТЫЕЭЗНВюЬиеї
:return:
"""
# 1ЁЂЛёШЁЪ§Он
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1: -2]
print(data)
# 2ЁЂЪЕР§ЛЏвЛИізЊЛЛЦї
transfer = VarianceThreshold(threshold=5)
# 3ЁЂЕїгУfit_transform
data_new = transfer.fit_transform(data)
print("data_new", data_new, data_new.shape)
return None
if __name__ == '__main__':
# ЕЭЗНВюЬиеїЙ§ТЫ
variance_demo()

ЯрЙиЯЕЪ§
ЦЄЖћбЗЯрЙиЯЕЪ§(Pearson Correlation Coefficient): ЗДгГБфСПжЎМфЯрЙиЙиЯЕУмЧаГЬЖШЕФЭГМЦжИБъ
ЙЋЪНМЦЫуАИР§(СЫНт,ВЛгУМЧвф)
ЙЋЪН:
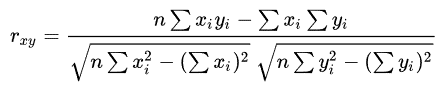
БШШчЫЕЮвУЧМЦЫуФъЙуИцЗбЭЖШыгыдТОљЯњЪлЖю
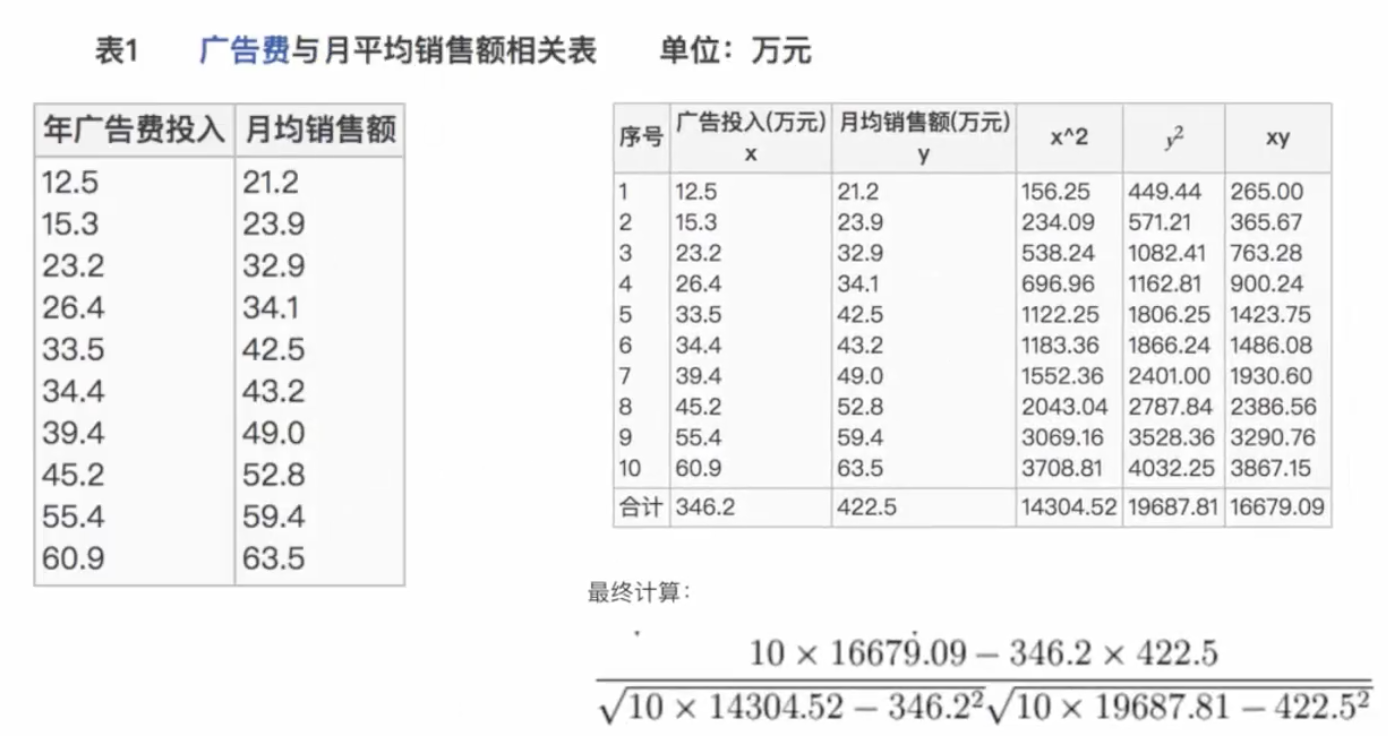
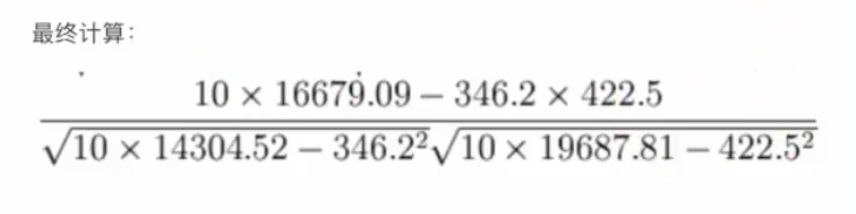
= 0.9942
ЫљвдЮвУЧзюжеЕУГіНсТлЪЧЙуИцЭЖШыЗбгыдТЦНОљЯњЪлЖюжЎМфгаИпЖШЕФе§ЯрЙиЙиЯЕЁЃ
ЬиЕу
ЯрЙиЯЕЪ§ЕФжЕНщгкЈC1гы+1жЎМф,МДЈC1Ём r Ём+1ЁЃЦфаджЪШчЯТ:
-
ЕБr>0ЪБ,БэЪОСНБфСПе§ЯрЙи,r<0ЪБ,СНБфСПЮЊИКЯрЙи
-
ЕБ|r|=1ЪБ,БэЪОСНБфСПЮЊЭъШЋЯрЙи,ЕБr=0ЪБ,БэЪОСНБфСПМфЮоЯрЙиЙиЯЕ
-
ЕБ0<|r|<1ЪБ,БэЪОСНБфСПДцдквЛЖЈГЬЖШЕФЯрЙиЁЃЧв|r|дННгНќ1,СНБфСПМфЯпадЙиЯЕдНУмЧа;|r|дННгНќгк0,БэЪОСНБфСПЕФЯпадЯрЙидНШѕ
вЛАуПЩАДШ§МЖЛЎЗж:|r|<0.4ЮЊЕЭЖШЯрЙи;0.4Ём|r|<0.7ЮЊЯджјадЯрЙи;0.7Ём|r|<1ЮЊИпЖШЯпадЯрЙи
етИіЗћКХ:|r|ЮЊrЕФОјЖджЕ, |-5| = 5
API
from scipy.stats import pearsonr
x : (N,) array_like
y : (N,) array_like Returns: (PearsonЁЏs correlation coefficient, p-value)
жїГЩЗжЗжЮі
ФПБъ
-
гІгУPCAЪЕЯжЬиеїЕФНЕЮЌ
-
гІгУ:гУЛЇгыЮяЦЗРрБ№жЎМфжїГЩЗжЗжЮі
ЪВУДЪЧжїГЩЗжЗжЮі(PCA)
ЖЈвх:ИпЮЌЪ§ОнзЊЛЏЮЊЕЭЮЌЪ§ОнЕФЙ§ГЬ,дкДЫЙ§ГЬжаПЩФмЛсЩсЦњдгаЪ§ОнЁЂДДдьаТЕФБфСП
зїгУ:ЪЧЪ§ОнЮЌЪ§бЙЫѕ,ОЁПЩФмНЕЕЭдЪ§ОнЕФЮЌЪ§(ИДдгЖШ),Ы№ЪЇЩйСПаХЯЂЁЃ
гІгУ:ЛиЙщЗжЮіЛђепОлРрЗжЮіЕБжа
ФЧУДИќКУЕФРэНтетИіЙ§ГЬФи?ЮвУЧРДПДвЛеХЭМ

API
- sklearn.decomposition.PCA(n_components=None)
- НЋЪ§ОнЗжНтЮЊНЯЕЭЮЌЪ§ПеМф
- n_components:
- аЁЪ§:БэЪОБЃСєАйЗжжЎЖрЩйЕФаХЯЂ
- ећЪ§:МѕЩйЕНЖрЩйЬиеї
- PCA.fit_transform(X) X:numpy arrayИёЪНЕФЪ§Он[n_samples,n_features]
- ЗЕЛижЕ:зЊЛЛКѓжИЖЈЮЌЖШЕФarray
Ъ§ОнМЦЫу
[[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
def pca():
"""
жїГЩЗжЗжЮіНјааНЕЮЌ
:return:
"""
# аХЯЂБЃСє70%
pca = PCA(n_components=0.7)
data = pca.fit_transform([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])
print(data)
return None
АИР§:ЬНОПгУЛЇЖдЮяЦЗРрБ№ЕФЯВКУЯИЗжНЕЮЌ
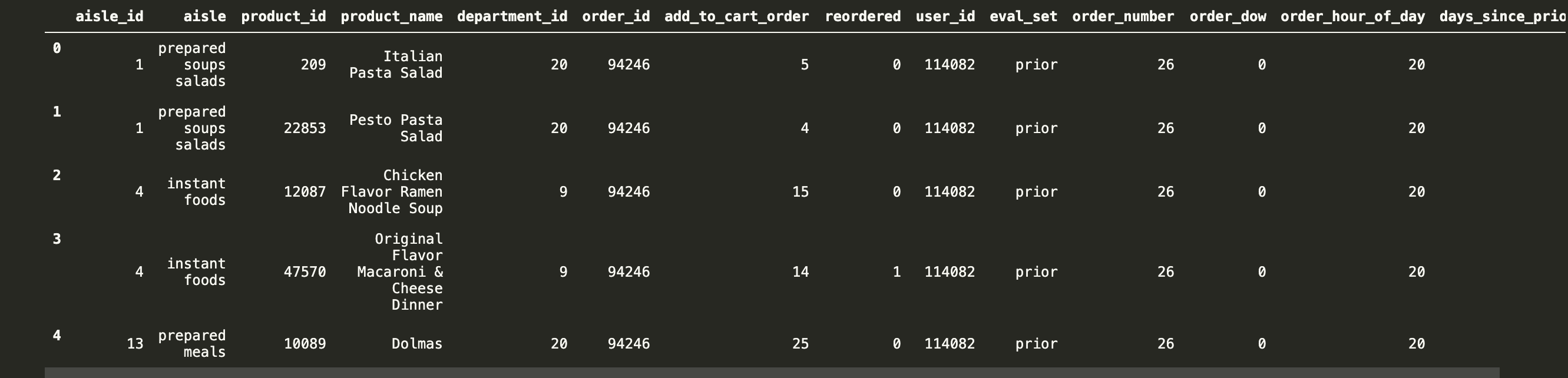
Ъ§Он
-
order_products__prior.csv:ЖЉЕЅгыЩЬЦЗаХЯЂ
- зжЖЮ:order_id, product_id, add_to_cart_order, reordered
-
products.csv:ЩЬЦЗаХЯЂ
- зжЖЮ:product_id, product_name, aisle_id, department_id
-
orders.csv:гУЛЇЕФЖЉЕЅаХЯЂ
- зжЖЮ:order_id,user_id,eval_set,order_number,Ё.
-
aisles.csv:ЩЬЦЗЫљЪєОпЬхЮяЦЗРрБ№
- зжЖЮ: aisle_id, aisle
ЗжЮі
-
КЯВЂБэ,ЪЙЕУuser_idгыaisleдквЛеХБэЕБжа
-
НјааНЛВцБэБфЛЛ
-
НјааНЕЮЌ
def pca_case_study():
"""
жїГЩЗжЗжЮіАИР§
:return:
"""
# ШЅЖСЫФеХБэЕФЪ§Он
prior = pd.read_csv("./instacart/order_products__prior.csv")
products = pd.read_csv("./instacart/products.csv")
orders = pd.read_csv("./instacart/orders.csv")
aisles = pd.read_csv("./instacart/aisles.csv")
print(prior)
# КЯВЂЫФеХБэ
mt = pd.merge(prior, products, on=['product_id', 'product_id'])
mt1 = pd.merge(mt, orders, on=['order_id', 'order_id'])
mt2 = pd.merge(mt1, aisles, on=['aisle_id', 'aisle_id'])
# pd.crosstab ЭГМЦгУЛЇгыЮяЦЗжЎМфЕФДЮЪ§ЙиЯЕ(ЭГМЦДЮЪ§)
cross = pd.crosstab(mt2['user_id'], mt2['aisle'])
# PCAНјаажїГЩЗжЗжЮі
pc = PCA(n_components=0.95)
data_new = pc.fit_transform(cross)
print("data_new:\n", data_new.shape)
return None