дкЪ§ФЃжа,ШЗЖЈШЈжиЗНЗЈгаКмЖржж,БШШчжїГЩЗжЗжЮіЗЈЁЂВуДЮЗжЮіЗЈЁЂьиШЈЗЈЁЂЯрЙиЯЕЪ§зїЮЊШЈжиЕШЁЃ
ЭјЩЯКмЖрНЬГЬЖМЪЧгУspssМЦЫуШЈжи,етРяжївЊНВРћгУpythonЭЈЙ§жїГЩЗжЗжЮіЗЈШЗЖЈШЈжиЁЃ
жїГЩЗжЗжЮіЗЈИХЪі
жїГЩЗжЗжЮіЗЈЪЧвЛжжЯпадЕФНЕЮЌЫуЗЈ,ЭЈЙ§НЋNЮЌЬиеїНјаае§НЛБфЛЛ,ЕУЕНЯрЛЅЖРСЂЕФkЮЌ(k<N)Ъ§Он,ЭЈЙ§ЗжЮіЕУГіЁАжїГЩЗжЁБ,РћгУЁАжїГЩЗжЁБШЗЖЈгАЯьШЈжиЁЃ
Ъ§ОнЙщвЛЛЏ
ЮЊСЫЯћГ§ВЛЭЌБфСПЕФСПИйЕФгАЯь,дкЖдЪ§ОнНјаажїГЩЗжЗжЮіЧА,ЪзЯШвЊЖдЪ§ОнНјааБъзМЛЏ,жЎЫљвдвЊЖдЪ§ОнНјааБъзМЛЏЁЃ
ЩцМАmИібљБО,nИіжИБъ,ЕкjИібљБОЕФЕкiИіжИБъжЕЮЊ,НЋИїИіЙщвЛЛЏжЕАДШчЯТЙЋЪННјааЙщвЛЛЏЮЊ:
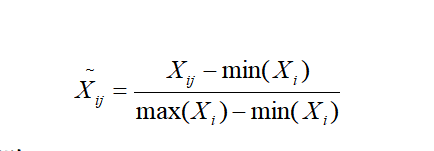
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
data = mms.fit_transform(data)pcaНЕЮЌ
from sklearn.decomposition import PCA
from sklearn import preprocessing
pca = PCA()
pca.fit(data)ЯШДѓжТПДвЛЯТИїжїГЩЗжЕФРлМЦЙБЯзжЕ,ШЗЖЈkИіжїГЩЗж
pca.components_ #ФЃаЭЕФИїИіЬиеїЯђСП вВНаГЩЗжОиеѓ
pca.explained_variance_ # ЙБЯзЗНВю,МДЬиеїИљ
pca.explained_variance_ratio_ #ИїИіГЩЗжИїздЕФЗНВюАйЗжБШ(ЙБЯзТЪ)pca = PCA(5) #ШЗЖЈ5ИіжїГЩЗж
pca.fit(data)
low_d = pca.transform(data)# low_dНЕЮЌКѓЕФНсЙћШЗЖЈШЈжи
# ЧѓжИБъдкВЛЭЌжїГЩЗжЯпадзщКЯжаЕФЯЕЪ§
k1_spss = pca.components_ / np.sqrt(pca.explained_variance_.reshape(-1, 1)) #ГЩЗжЕУЗжЯЕЪ§Оиеѓ
j = 0
Weights = []
for j in range(len(k1_spss)):
for i in range(len(pca.explained_variance_)):
Weights_coefficient = np.sum(100 * (pca.explained_variance_ratio_[i]) * (k1_spss[i][j])) / np.sum(
pca.explained_variance_ratio_)
j = j + 1
Weights.append(np.float(Weights_coefficient))
print('Weights',Weights)
#Weights [11.55267610875436, 22.403803988479392, 13.391066309212121, -2.3723300938403176, -0.5180775289478192]ШЈжиЙщвЛЛЏ
Weights=pd.DataFrame(Weights)
Weights1 = preprocessing.MinMaxScaler().fit(Weights)
Weights2 = Weights1.transform(Weights)
print('Weights2',Weights2)
'''
Weights2 [[0.56203305]
[1. ]
[0.63623309]
[0. ]
[0.07484027]]
'''ЙизЂВшЬИДѓЪ§ОнЛиИДЁОжїГЩЗжДњТыЁПЛёШЁЭъећЕФДњТы
