ФПТМ
1. ЯрЙиЫЕУї
зюНќдкећРэЯрЙиЪЕбщДњТыЕФЪБКђ,ЮовтжаашвЊжиаТЪсРэЯТЖдПЙЙЅЛїРяЕФFGSM,гкЪЧздМКВЮПМЭјЩЯЕФвЛаЉзЪСЯвдМАздМКЕФаФЕУаДЯТетЦЊЮФеТ,гУРДвдКѓЛивфЁЃ
2. ЯрЙиМђЪі
ПьЫйЬнЖШБъжОЙЅЛї(FGSM),ЪЧЦљНёЮЊжЙзюдчКЭзюЪмЛЖгЕФЖдПЙадЙЅЛїжЎвЛ,ЫќгЩ Goodfellow ЕШШЫдк[Explaining and Harnessing Adversarial Examples] (https://arxiv.org/abs/1412.6572)жаЬсГі,ЪЧвЛжжМђЕЅЕЋЪЧгааЇЕФЖдПЙбљБОЩњГЩЫуЗЈЁЃЫќжМдкЭЈЙ§РћгУФЃаЭбЇЯАЕФЗНЪНКЭНЅБфРДЙЅЛїЩёО ЭјТчЁЃетИіЯыЗЈКмМђЕЅ,ЙЅЛїЕїећЪфШыЪ§ОнвдЛљгкЯрЭЌЕФЗДЯђДЋВЅЬнЖШРДзюДѓЛЏЫ№ЪЇ,ЖјВЛЪЧЭЈЙ§ЛљгкЗДЯђДЋВЅЕФЬнЖШЕїећШЈжиРДзюаЁЛЏЫ№ЪЇЁЃ ЛЛОфЛАЫЕ,ЙЅЛїЪЧРћгУЫ№ЪЇКЏЪ§ЕФЬнЖШ,ШЛКѓЕїећЪфШыЪ§ОнвдзюДѓЛЏЫ№ЪЇЁЃ
3. ДњТыЪЕЯж
3.1 в§ШыЯрЙиАќ
# етОфЛАЕФзїгУ:МДЪЙЪЧдкPython2.7АцБОЕФЛЗОГЯТ,printЙІФмЕФЪЙгУИёЪНвВзёбPython3.xАцБОжаЕФМгРЈКХЕФаЮЪН
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
3.2 ЪфШы
# ЩшжУВЛЭЌШХЖЏДѓаЁ
epsilons = [0, .05, .1, .15, .2, .25, .3]
# дЄбЕСЗФЃаЭ
pretrained_model = "./data/lenet_mnist_model.pth"
# ЪЧЗёЪЙгУcuda
use_cuda = True
3.3 ЖЈвхБЛЙЅЛїЕФФЃаЭ
# ЖЈвхLeNetФЃаЭ
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#ЩљУї MNIST ВтЪдЪ§ОнМЏКЮЪ§ОнМгди
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
])),
batch_size=1, shuffle=True)
# ЖЈвхЮвУЧе§дкЪЙгУЕФЩшБИ
print("CUDA Available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")
# ГѕЪМЛЏЭјТч
model = Net().to(device)
# МгдивбОдЄбЕСЗЕФФЃаЭ
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))
# дкЦРЙРФЃЪНЯТЩшжУФЃаЭЁЃдкетжжЧщПіЯТ,етЪЪгУгкDropoutЭМВу
model.eval()
ШЛКѓЮвУЧдЫааЯТ,ГіЯжЯТУцНсЙћ,жївЊЪЧдкЯТдиЪ§ОнМЏЁЃ
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to Ё/data/MNIST/raw/train-images-idx3-ubyte.gz
Extracting Ё/data/MNIST/raw/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to Ё/data/MNIST/raw/train-labels-idx1-ubyte.gz
Extracting Ё/data/MNIST/raw/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to Ё/data/MNIST/raw/t10k-images-idx3-ubyte.gz
Extracting Ё/data/MNIST/raw/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to Ё/data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting Ё/data/MNIST/raw/t10k-labels-idx1-ubyte.gz
ProcessingЁ
Done!
CUDA Available: True
3.4 ЖЈвхFGSMЙЅЛїКЏЪ§
# FGSMЫуЗЈЙЅЛїДњТы
def fgsm_attack(image, epsilon, data_grad):
# ЪеМЏЪ§ОнЬнЖШЕФдЊЫиЗћКХ
sign_data_grad = data_grad.sign()
# ЭЈЙ§ЕїећЪфШыЭМЯёЕФУПИіЯёЫиРДДДНЈШХЖЏЭМЯё
perturbed_image = image + epsilon*sign_data_grad
# ЬэМгМєЧавдЮЌГж[0,1]ЗЖЮЇ
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# ЗЕЛиБЛШХЖЏЕФЭМЯё
return perturbed_image
3.5 ВтЪдКЏЪ§
def test( model, device, test_loader, epsilon ):
# ОЋЖШМЦЪ§Цї
correct = 0
adv_examples = []
# бЛЗБщРњВтЪдМЏжаЕФЫљгаЪОР§
for data, target in test_loader:
# АбЪ§ОнКЭБъЧЉЗЂЫЭЕНЩшБИ
data, target = data.to(device), target.to(device)
# ЩшжУеХСПЕФrequires_gradЪєад,етЖдгкЙЅЛїКмЙиМќ
data.requires_grad = True
# ЭЈЙ§ФЃаЭЧАЯђДЋЕнЪ§Он
output = model(data)
init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
# ШчЙћГѕЪМдЄВтЪЧДэЮѓЕФ,ВЛДђЖЯЙЅЛї,МЬај
if init_pred.item() != target.item():
continue
# МЦЫуЫ№ЪЇ
loss = F.nll_loss(output, target)
# НЋЫљгаЯжгаЕФНЅБфЙщСу
model.zero_grad()
# МЦЫуКѓЯђДЋЕнФЃаЭЕФЬнЖШ
loss.backward()
# ЪеМЏdatagrad
data_grad = data.grad.data
# ЛНабFGSMНјааЙЅЛї
perturbed_data = fgsm_attack(data, epsilon, data_grad)
# жиаТЗжРрЪмШХТвЕФЭМЯё
output = model(perturbed_data)
# МьВщЪЧЗёГЩЙІ
final_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
if final_pred.item() == target.item():
correct += 1
# БЃДц0 epsilonЪОР§ЕФЬиР§
if (epsilon == 0) and (len(adv_examples) < 5):
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
else:
# ЩдКѓБЃДцвЛаЉгУгкПЩЪгЛЏЕФЪОР§
if len(adv_examples) < 5:
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
# МЦЫуетИіepsilonЕФзюжезМШЗЖШ
final_acc = correct/float(len(test_loader))
print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))
# ЗЕЛизМШЗадКЭЖдПЙадЪОР§
return final_acc, adv_examples
дйДЮдЫаа,ЪфГіЯТУцНсЙћ:
Epsilon: 0 Test Accuracy = 9810 / 10000 = 0.981
Epsilon: 0.05 Test Accuracy = 9426 / 10000 = 0.9426
Epsilon: 0.1 Test Accuracy = 8510 / 10000 = 0.851
Epsilon: 0.15 Test Accuracy = 6826 / 10000 = 0.6826
Epsilon: 0.2 Test Accuracy = 4303 / 10000 = 0.4303
Epsilon: 0.25 Test Accuracy = 2087 / 10000 = 0.2087
Epsilon: 0.3 Test Accuracy = 871 / 10000 = 0.0871
4. ПЩЪгЛЏНсЙћ
дкЩЯУцЕФЛљДЁЩЯЮвУЧЬэМгЯТУцЕФДњТы:
plt.figure(figsize=(5,5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()
дЫаа,ГіЯжЯТУцНсЙћ:
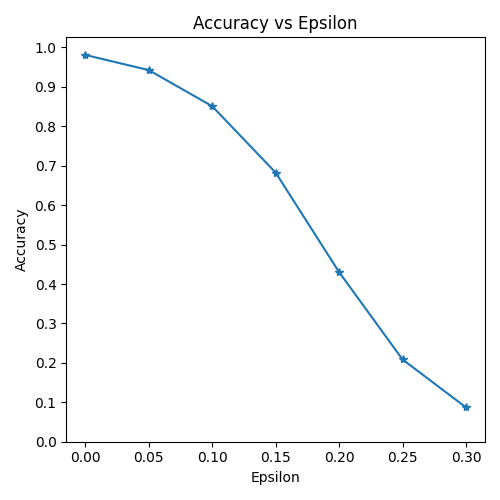
5. ПЩЪгЛЏЖдПЙбљБО
# дкУПИіepsilonЩЯЛцжЦМИИіЖдПЙбљБОЕФР§зг
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):
for j in range(len(examples[i])):
cnt += 1
plt.subplot(len(epsilons),len(examples[0]),cnt)
plt.xticks([], [])
plt.yticks([], [])
if j == 0:
plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)
orig,adv,ex = examples[i][j]
plt.title("{} -> {}".format(orig, adv))
plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()
дЫаа,НсЙћШчЯТ:

6. дЄбЕСЗФЃаЭЯТди
ЮФжаЮвУЧгавЛИідЄбЕСЗКУЕФФЃаЭ,ШчЙћздМКВЛЯыбЕСЗПЩвддкетРяЯТди:
ФЃаЭЯТдиЕижЗ
7. бЕСЗФЃаЭ
ШчЙћздМКЯыбЕСЗвЛИіФЃаЭ,ПЩвддЫааЯТУцетИіКЏЪ§main.py:
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
# ЖЈвхLeNetФЃаЭ
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data_row', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data_row', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
# БЃДцЭјТчжаЕФВЮЪ§, ЫйЖШПь,еМПеМфЩй
if args.save_model:
torch.save(model.state_dict(), "lenet_mnist_model.pth")
if __name__ == '__main__':
main()
8. ЭъећДњТы
ЩЯУцЪЧНЋУПИіФЃПщЕЅЖРФУГіРДаДЕФ,ашвЊЭъећДњТыЕФПЩвддкЮвЕФGitHubЩЯЯТди,ШчЙћФњОѕЕУКУЕФЛАМЧЕУИјИіStarЁЃ
ЭъећДњТыСДНгЕижЗ