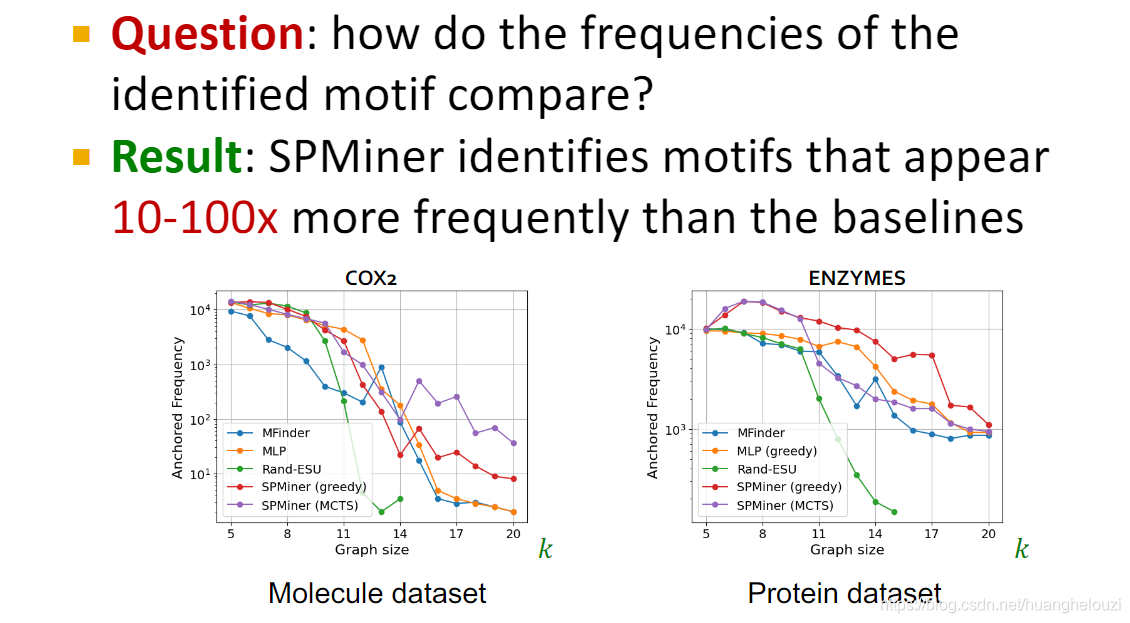
ͼ������
Subgraphs and Motifs
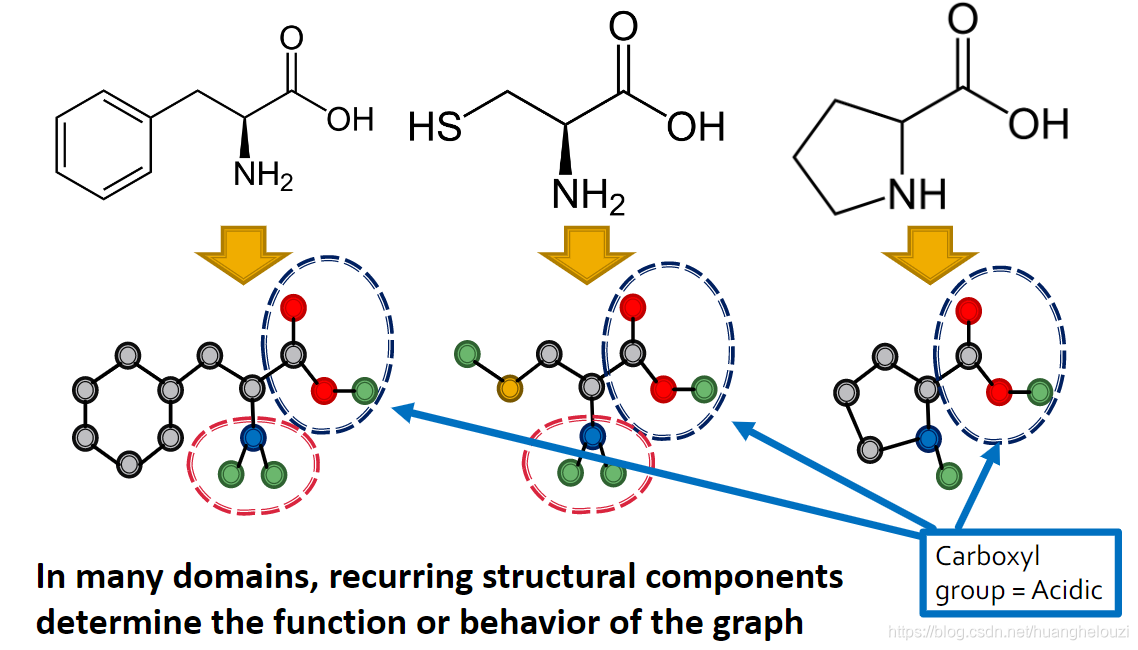
��ͼ(Subgraphs)��ͼ��һ����,��������ͼΪ��ľ(building blocks),����ͼ����������ͼ���ںܶ�����,�ܶ��ظ����ֵĵ���ͼ��������ͼ�Ĺ��ܡ��������һ�����������е�����,��ͼ�г���Carboxyl�����ͼ�ṹ,��ô���������ʽ�������ζ������ʡ�
�����ַ�ʽ������ʽ���Ķ�����ͼ:Node-induced subgraph,Edge-induced subgraph(����ʹ��)��


�ڲ�ͬ������Ͳ�ͬ�ij�����ʹ�ò�ͬ����ͼ���巽��,һ�������,ʹ��Node-induced subgraph�Ƚ϶�,��ΪEdge-induced subgraph��ʱ�临���ԱȽϴ�

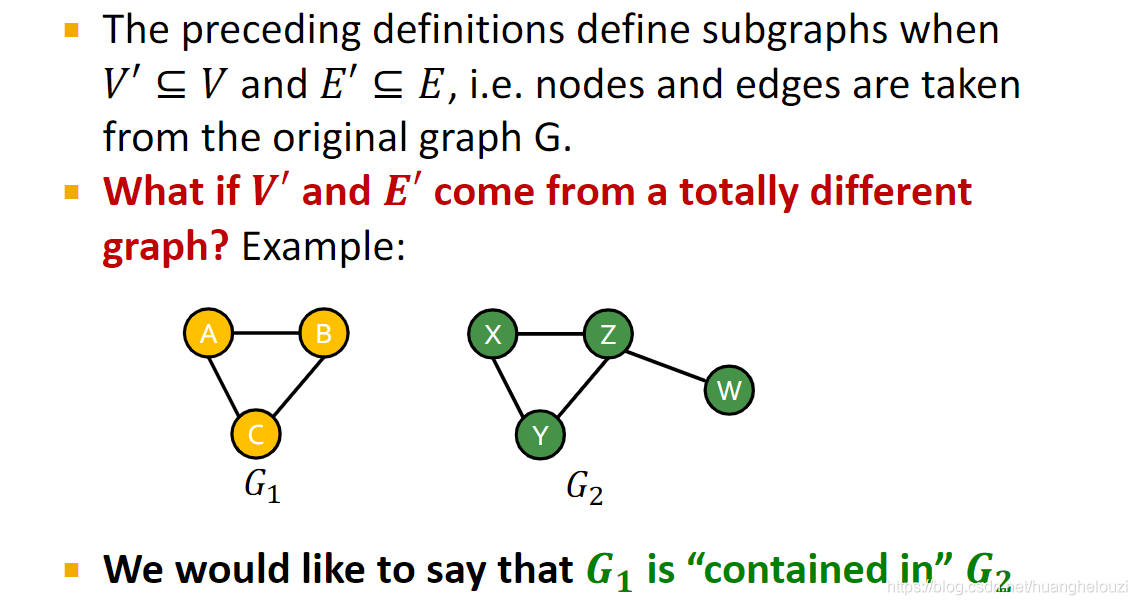
��Ȼ��ͼ������������������ͼ,��ʱ��ͱ����ij����ͼ�Ƿ������ͼ�е����⡣
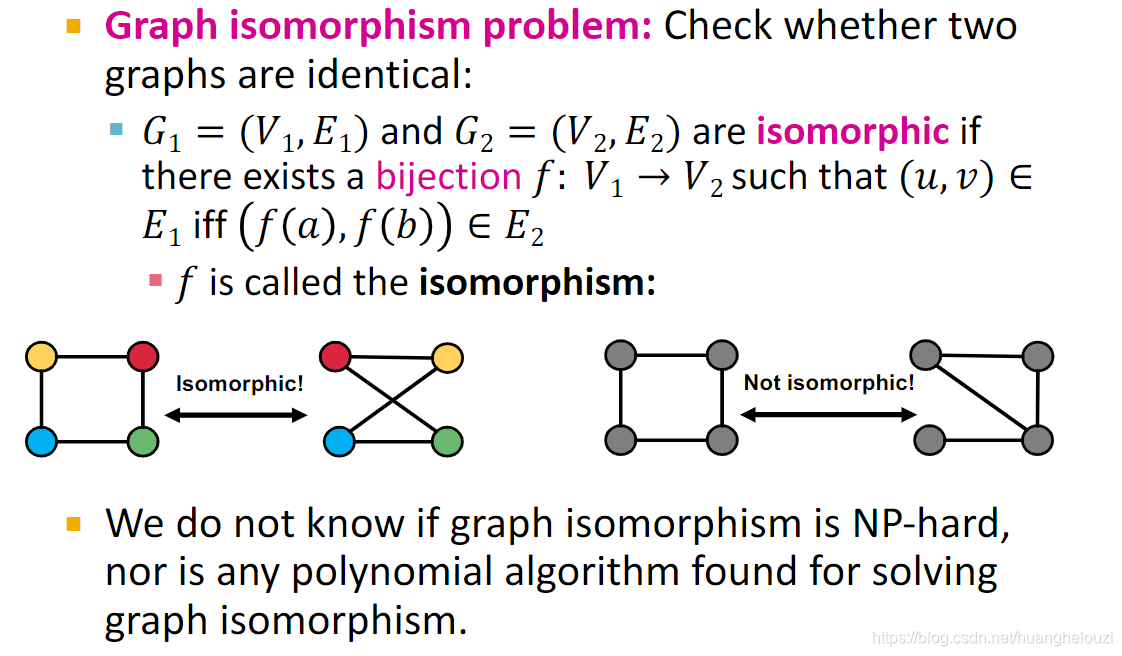
ͼͬ������(Graph isomorphism problem):ע��ͬ������ͬ�Ǵ������ֵ�,��Ҫ����Ϊͼ�нڵ����迼��˳������(��ڵ�a���ھӽڵ���bcd�ͽڵ�a���ھӽڵ���cbd��һ����)��
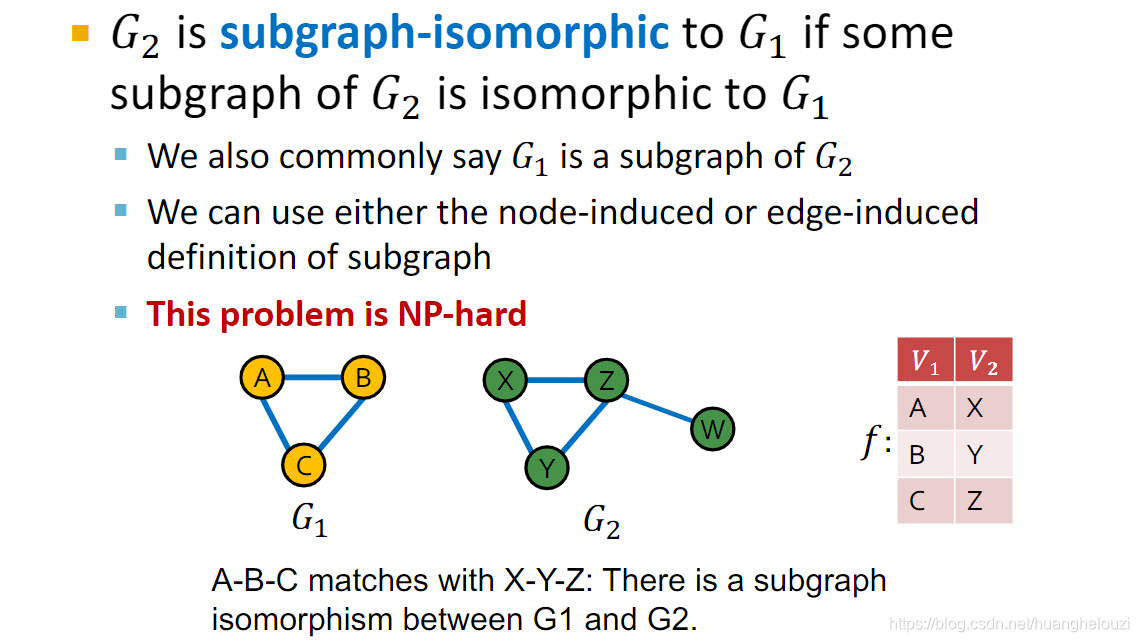
��ͼͬ������,���ǿ��Եõ���ͼͬ������,������仰˵����ij��ͼ�Ƿ��������һ��ͼ�С���������ͼ
G
1
G_1
G1?��
G
2
G_2
G2?����ͼ(xyz)ͬ��,Ҳ����˵
G
1
G_1
G1?������
G
2
G_2
G2?�С�
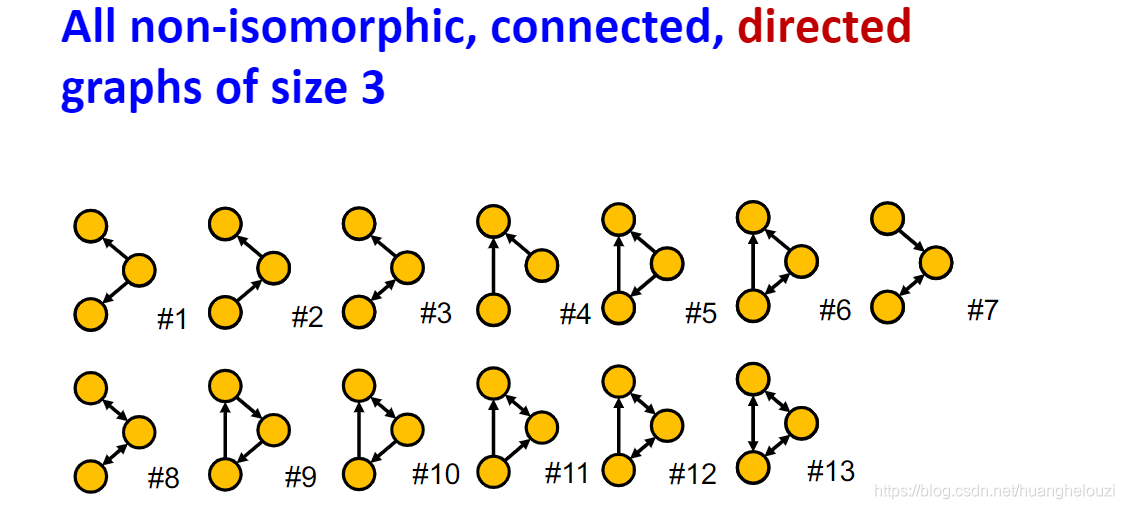
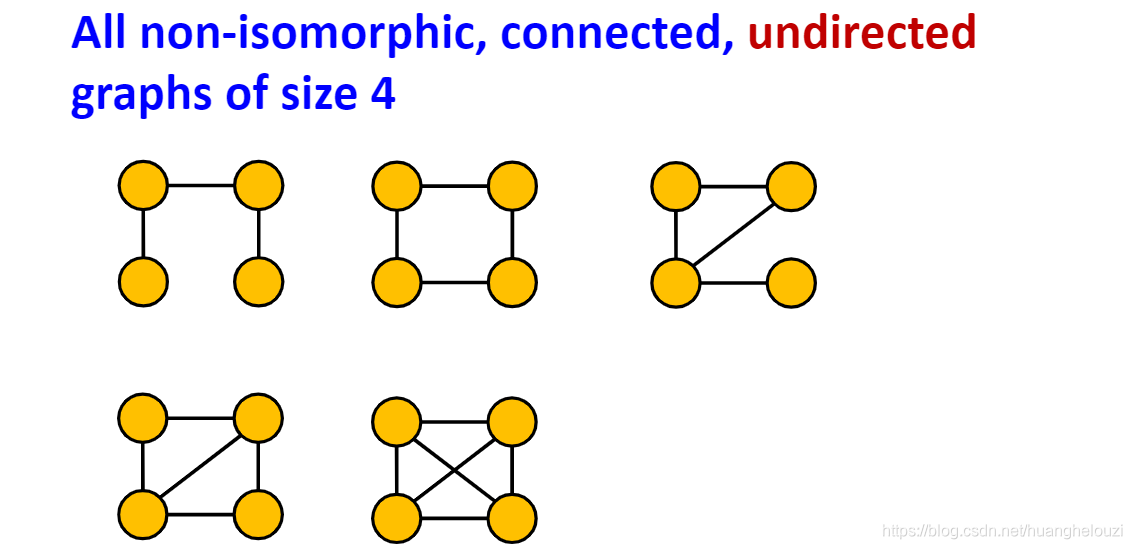
�����ڵ�����,���ǿɻ�úܶ����ͬ���ġ���ͨ�ġ���������������ͼ��������ijЩ����Ƶ�ʸߵġ��Ƚ���Ҫ��һ������ͼ����Ϊmotifs����������ڵ�����Ϊ3��4ʱ�����з�ͬ���ġ���ͨ�ġ���������������ͼ,�������ڵ������Ƚϴ�ʱ,������ͼ����������������
�������motifs�Ķ��������,motifs�������Ƕ�γ��ֵġ���Ҫ��С����ͼ��

��ômotifs��ʲô����?��ͼ�������motifs�����úͳ�����motifs���ӡ�
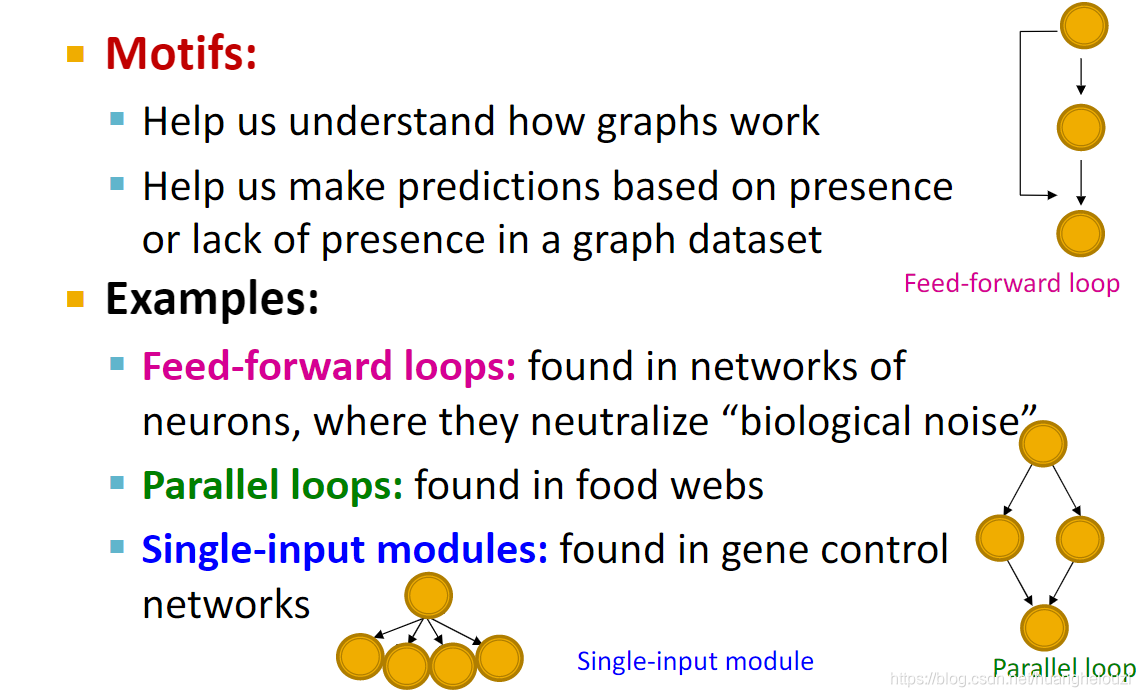
����˵��motifs�������Ƕ�γ��ֵġ���Ҫ��С����ͼ������������ָ����Ҫ����,һ��Ƶ��(Frequency),������Ҫ��(significance)��
Ƶ�ʷ�Ϊ����:Graph-level Subgraph Frequency��Node-level Subgraph Frequency��
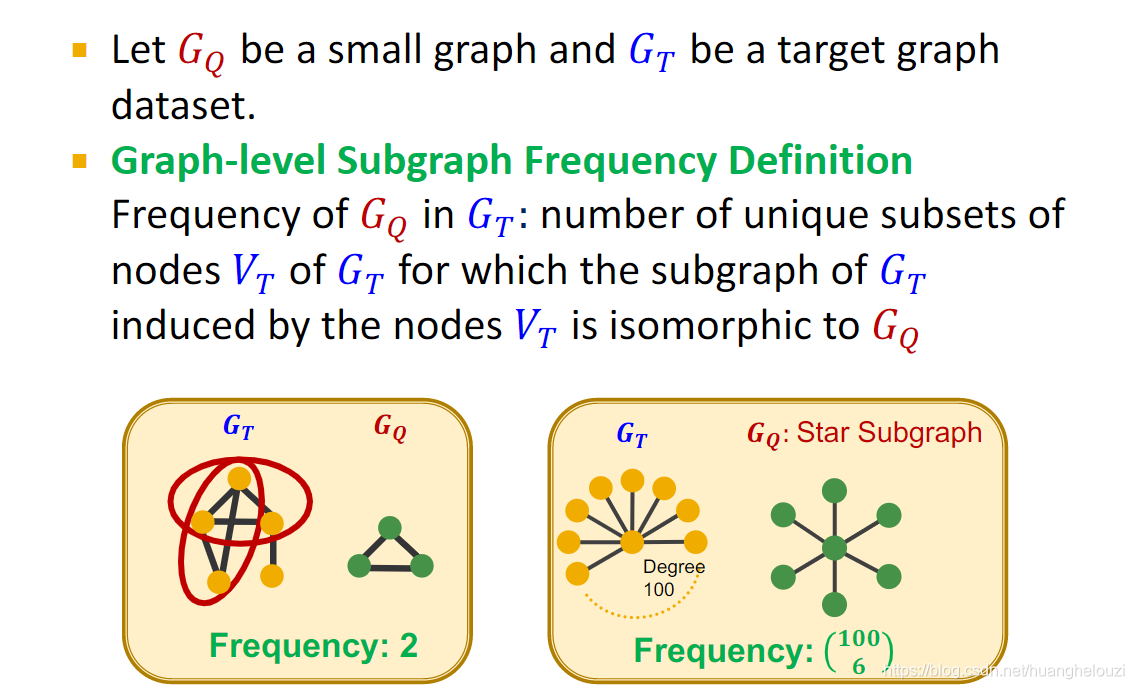
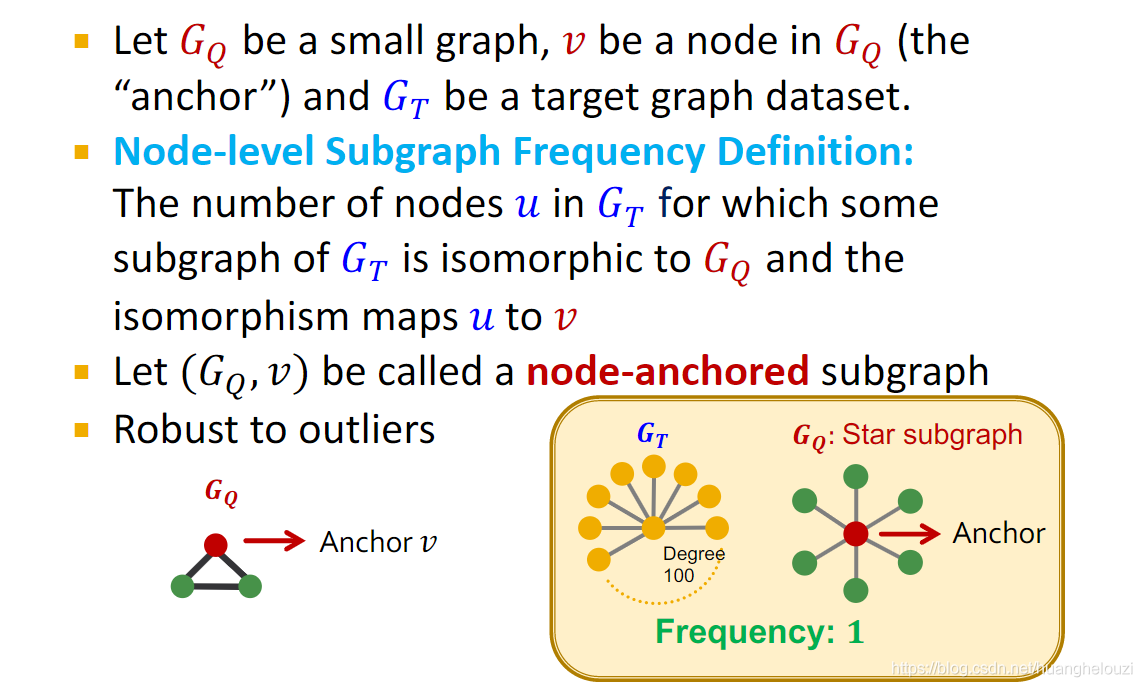
�����,������Ƶ�ʶ��������չ������ͨͼ,ֻ��Ҫ��ÿ����ͨ������Ϊһ��������ͼ���ɡ�
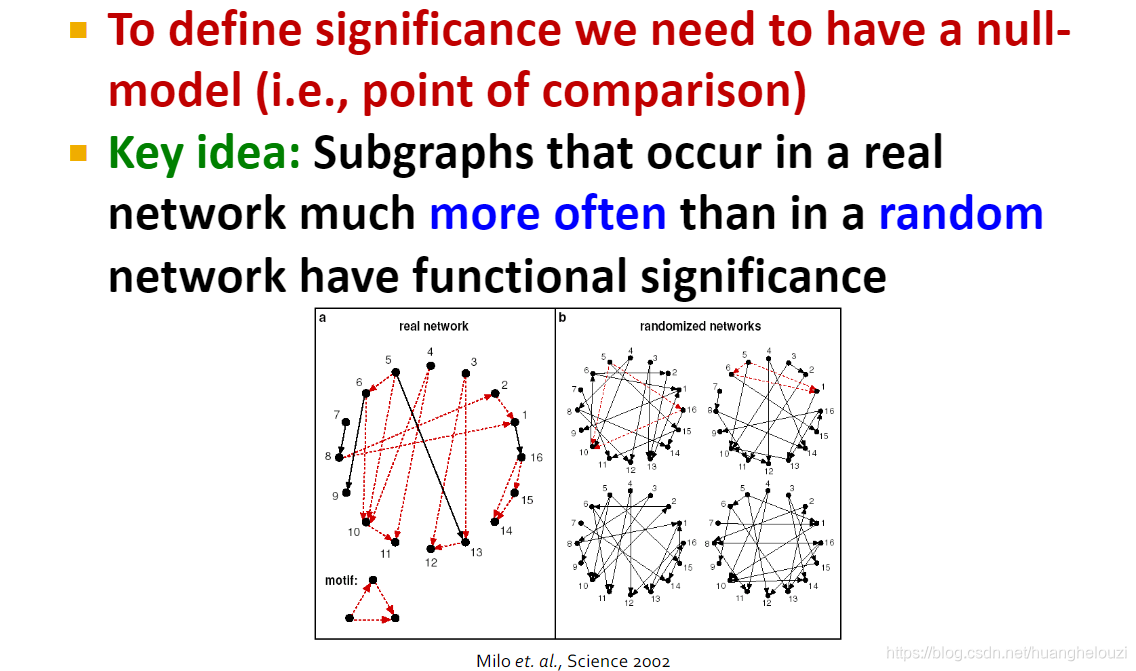
����ͼ��Ҫ��(significance)�Ķ���ͱȽϸ���,������Ҫ����һ��null-model(Ҳ����һ�����ͼ),��һ����ͼ��������ʵͼ(��֮��Ӧ�ľ������ͼ)�Ĵ����ȳ��������ͼ�еĴ���Խ��,����ͼ����Ҫ�Ծ�Խ��
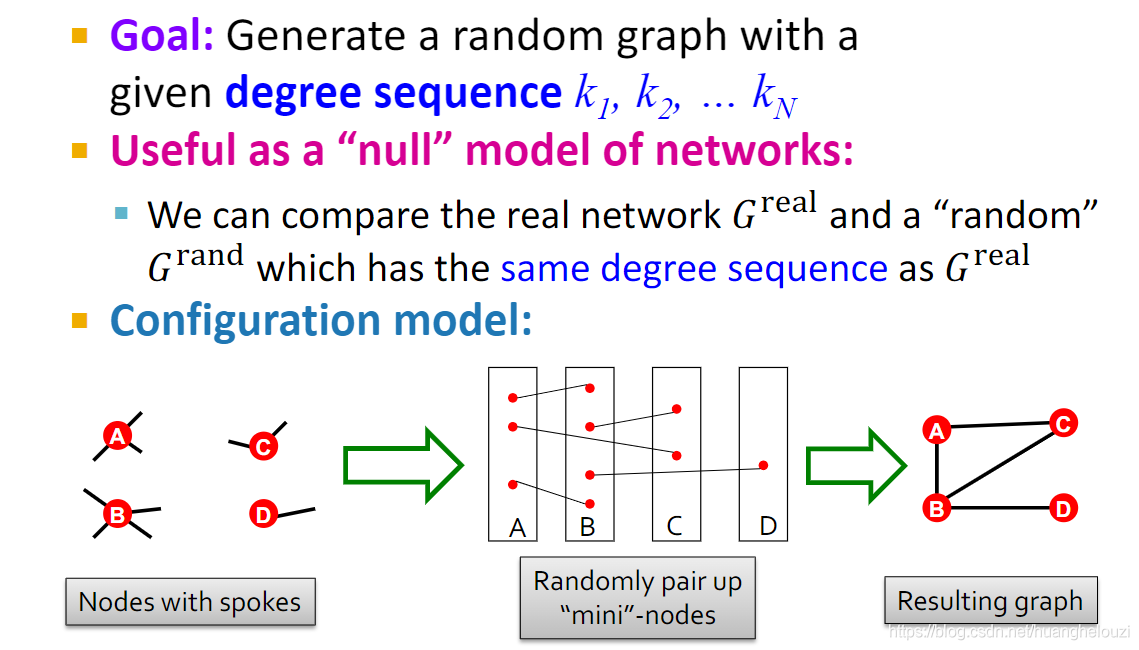
��ô��ο��ٵ��������ͼ,���Ժ������ıȽ���?���ͼ����ģ����Ҫ������:Erd?s�CR��nyi (ER) random graphs��Configuration model��
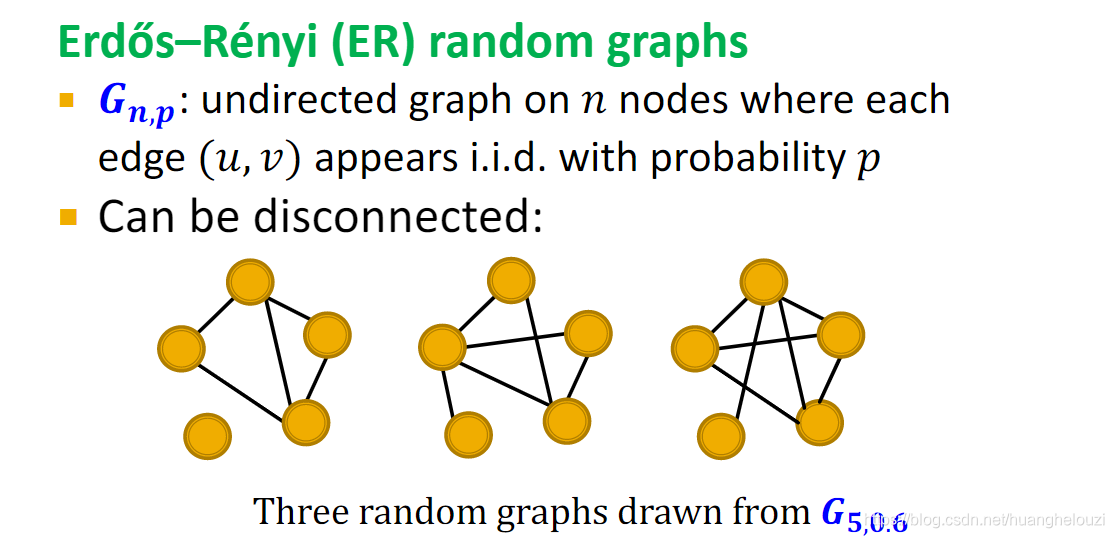
Erd?s�CR��nyi (ER) random graphs�Ƚϼ�,��������n���ڵ�,Ȼ�������ڵ�֮���Ը���p���ɱߡ�
Configuration model�Ƚϸ���,��Ҫ�����ڵ�����n֮��,����Ҫ�����ڵ�Ķ�������Ҫע�����:�ڵ����ɱߵĹ�����,���ܻ�����ظ��ߺ���ѭ����,�ɺ������������ͱ�,��Ϊ������߳��ָ��ʺܵ͡�
Motif��Ҫ�Լ����������:



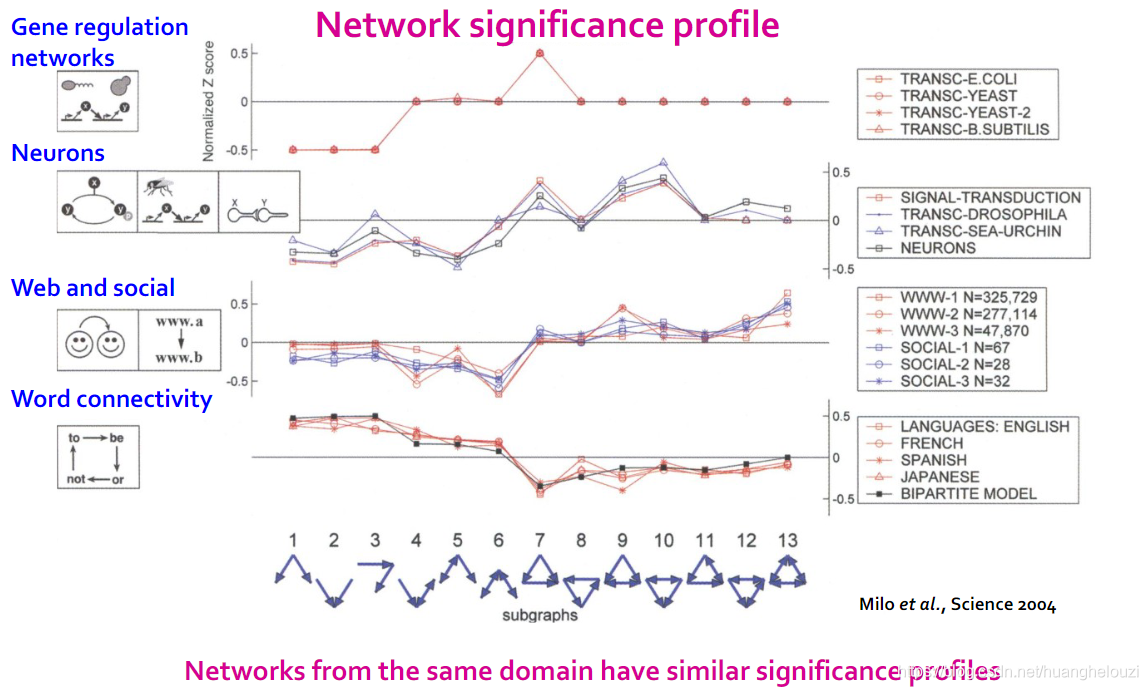
�������significance profile��Ҫ�Ե�����,����ΪSP(significance profile,Ҳ���ǹ�һ����Z Score)ֵ,����Ϊ13���ڵ�����Ϊ3����ͼ,�������µķ���:
- ����ͬһ���������������Ƶ�significance profiles
- significance profilesֵ��С������������֪��ͬ���������罻������,������������,��ô�����������֮��Ӧ�úܴ����Ҳ�����ѹ�ϵ,���ڵ���������ͼ6��SPֵ��С��ͼ13��SPֵ�ܴ�,��˵����ͼ13���罻����ͼ�к���Ҫ,����ͼ13���罻�����motif��
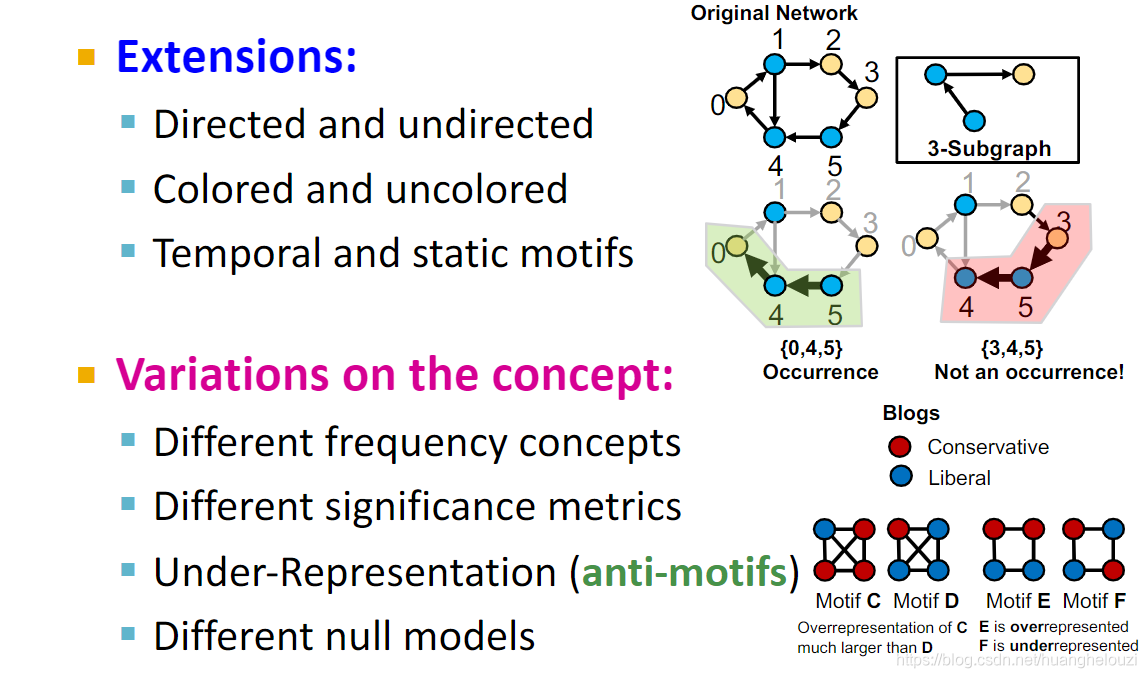
���ܽ�һ��motif�ļ������,��Ҫע��IJ���2����ʹ�ö�����ͼ���м����;����3�м�����ͼ��Ҫ�Է�������ʹ�ù�һ����Z-score�ȡ�

ͬ��motif���������չ��������ͬ��ͼ��
�ܽ�:

Neural Subgraph Matching
��ͼƥ����������:һ����С����ͼ�Ƿ���һ����ͼ����ͼ���������������,��ѯͼ��ͼ����ͼ,ͼ����ͬ��ɫ�ڵ���һһӳ���ϵ��
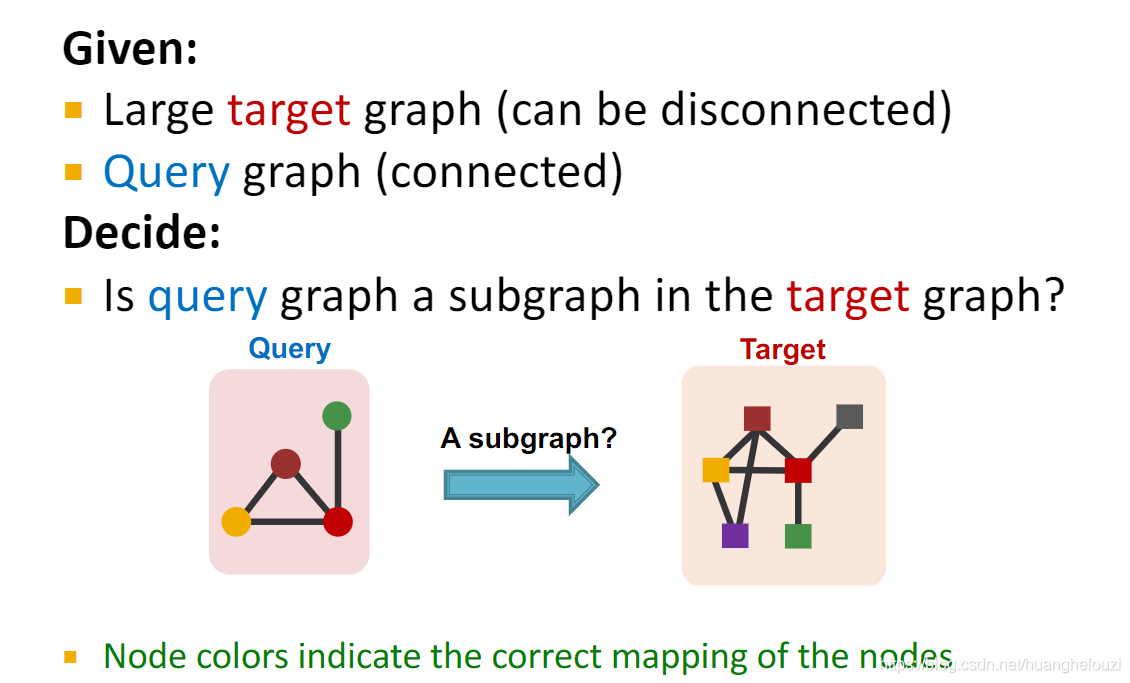
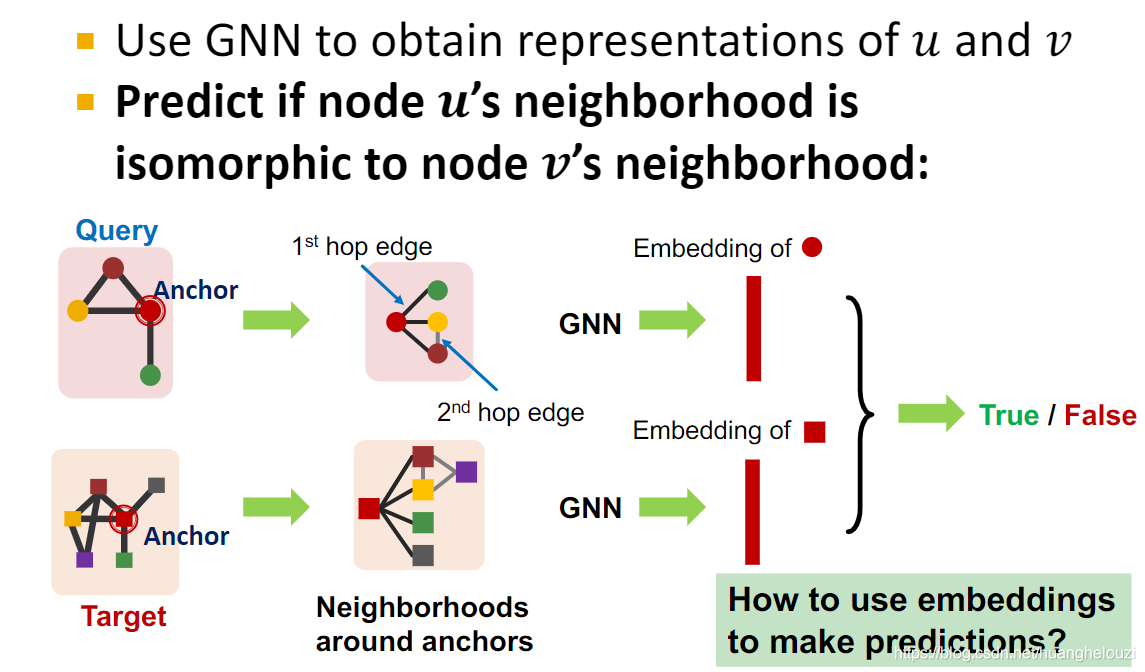
ͬʱ�����ͼƥ���������ʹ��GNNʵ��,ʹ�õ��ǽڵ�Ƕ����бȽϡ�����GNN����ͨ����Ҫ��ڵ���߽��бȽϡ�
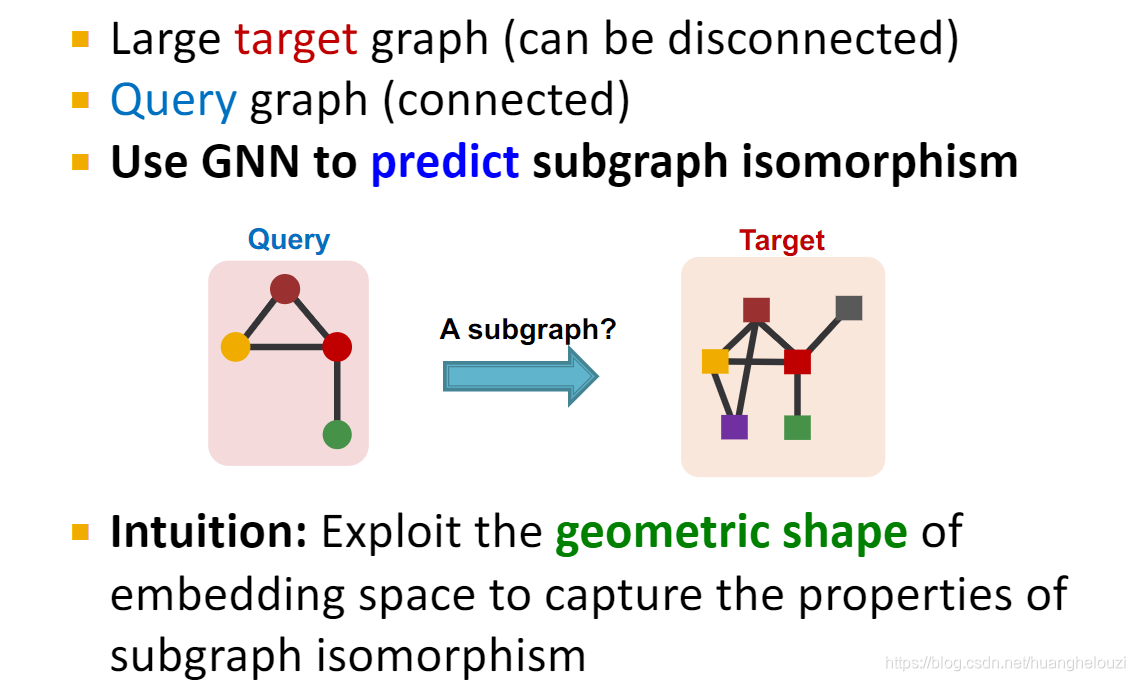
��GNN��ͼƥ��ͨ�����ǵ���:��ͼ�Ƿ������ͼ��,������ע��ͼ��ͼ�е�ʲôλ�á�
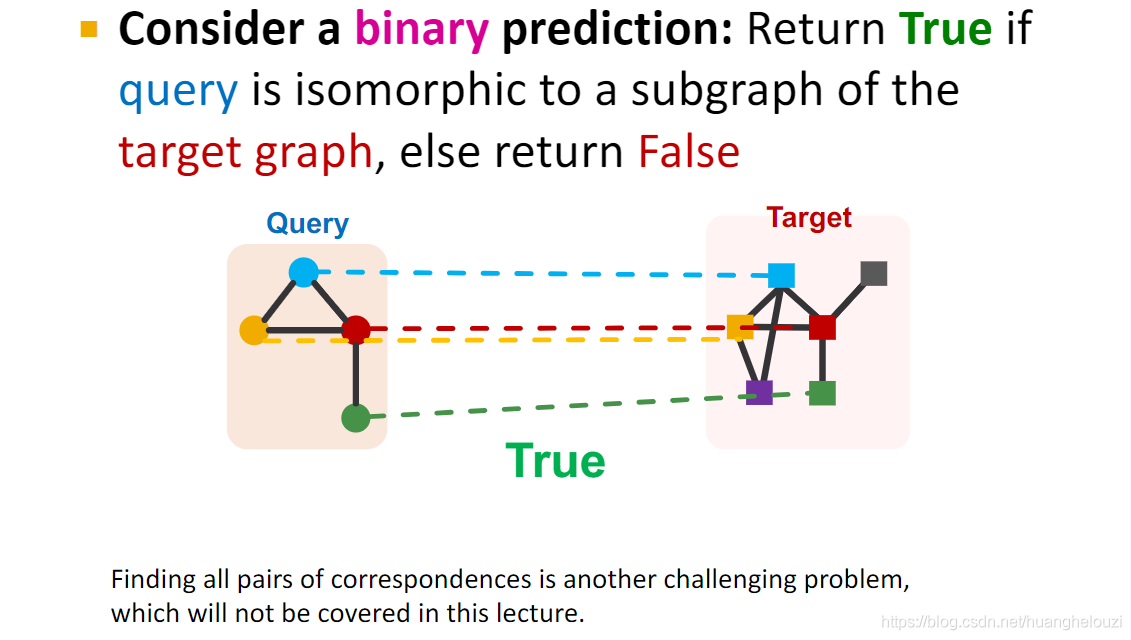
GNN�����ͼƥ��������Ҫ��Ϊ������,ʹ��Ƕ�����Ԥ�����ͨGNNһ����
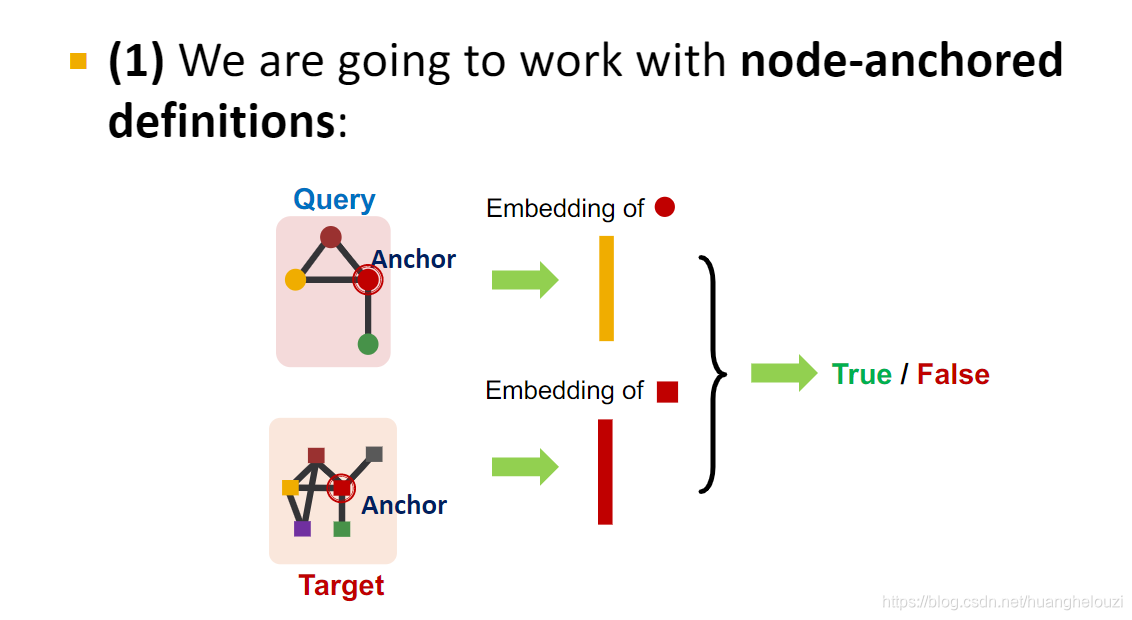
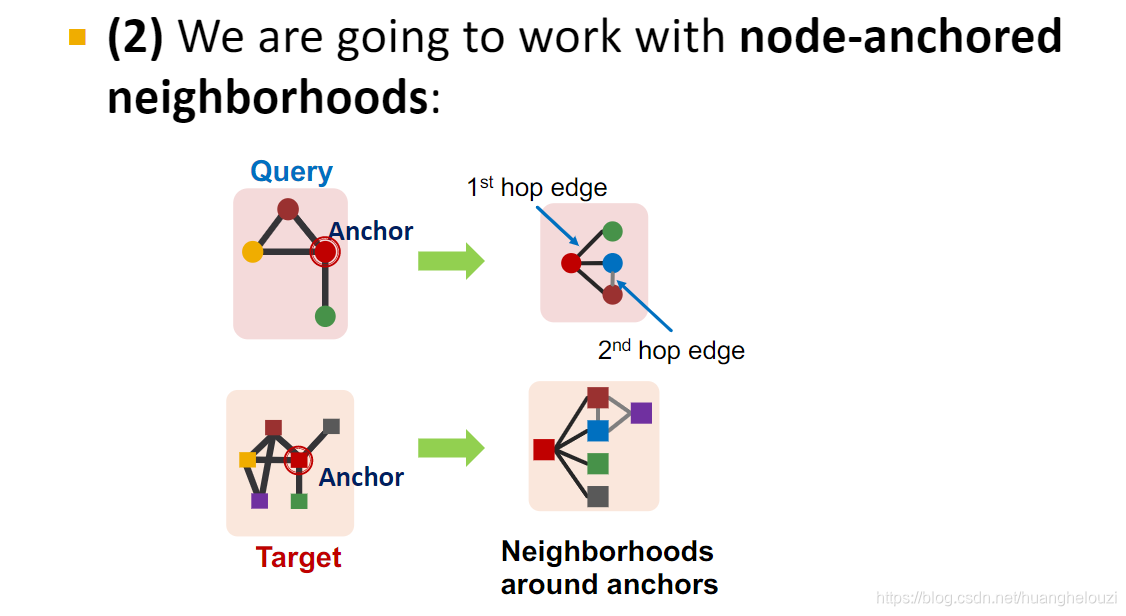
��ΪʲôҪѡȡê�ڵ���?
����ÿ��ê�ڵ�,����ʹ�üĹ�����������㷨��ȡ����Χk���ھӡ�Ȼ��ʹ��k���ھӼ���ÿ��ê�ڵ��Ƕ�롣

��������������Ƕ��ռ�(Order Embedding Space),������Ҫʹ��GNN��ͼӳ�䵽�����ά��Ƕ��ռ���,Ȼ�������Ƕ��ռ��н��бȽ�,�����½ǵ�ͼ(Ƕ��)�����Ϸ���ͼ(Ƕ��)����ͼ��
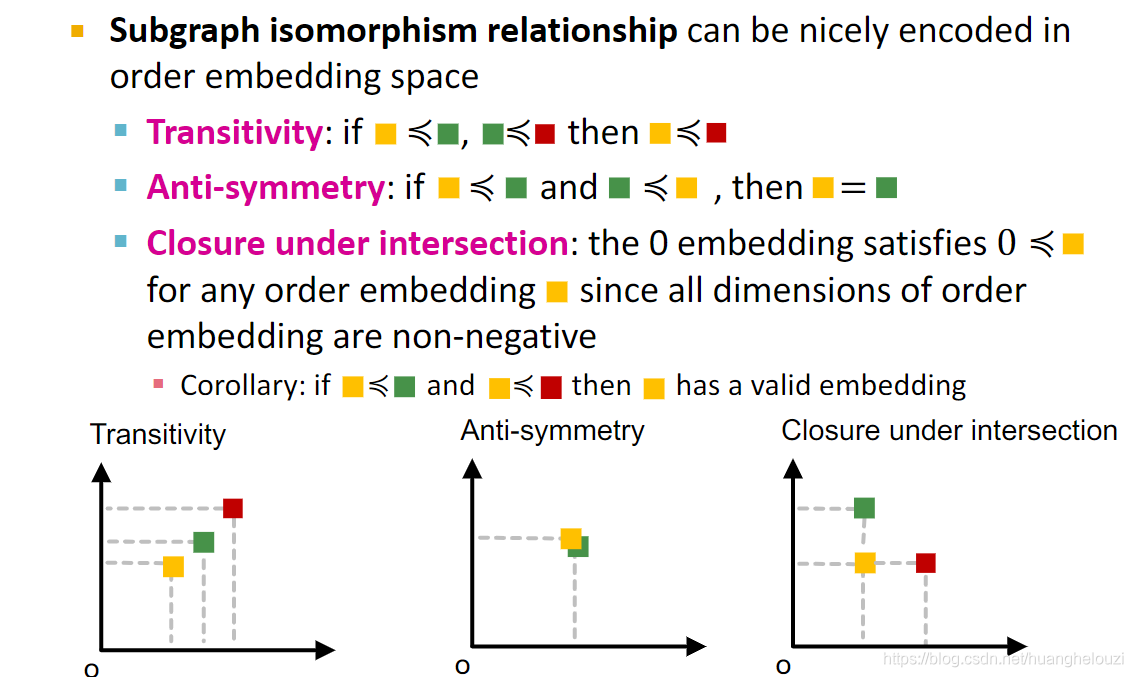
����Ƕ��ռ�(Order Embedding Space)����ʹ��ÿ��ͼǶ���ÿһ��ά�ȶ����ڵ���0,��ʹ�����ǿ���ͨ���Ƚ�Ƕ��Ĵ�С(Ҳ����λ��)������ȷ���ж��Ƿ�������ͼͬ����ϵ��ͬʱ��Ҳʹ����ͼ��ϵ���д�����(transitivity),�������Ǽ���������ͼǶ��a��b��c,����������Ƕ��ռ�Ĺ�ϵ��a��b,b��c,���ǿ��Եõ�a��c,���仰˵b��a����ͼ��ͬʱ,c����b����ͼ,�����Ƴ�cҲ��a����ͼ��

�ٸ�����,������������ѯͼ,���ǵ�Ƕ��ֱ�ʹ����ɫԲȦ�ͻ�ɫԲȦ��ʾ,Ŀ��ͼ
G
T
G_T
GT?��Ƕ��ʹ�ú�ɫ�����ʾ����Ϊ��ɫԲȦ�ں�ɫ��������·�(��ɫԲȦ�ܺ�ɫ����),����ɫԲȦ��Ӧ��ͼ��Ŀ��ͼ����ͼ��
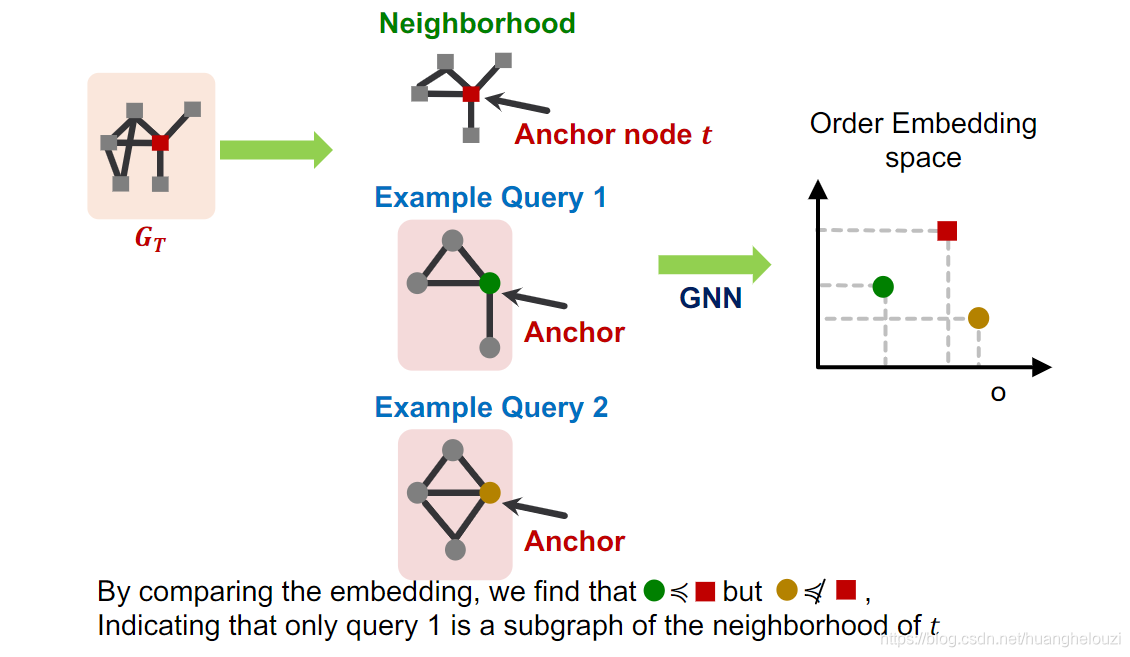
ʹ������Ƕ��ռ�����Ϊ�������Ч�ı�����ͼͬ����ϵ�� ͬʱ����Ƕ��ռ仹��Transitivity(������)��Anti-symmetry(���Գ���)��Closure under intersection�����ԡ�

������GNN��Loss����֮ǰ,��˵һ������Ƕ��ռ��Լ�������Corder constraint,��Ϊ���������ʧ�����������Լ��,���Լ��Ӧ��ʹ�����ǻ�õ�ͼǶ����Ժܺõķ�Ӧ��ͼ��ϵ��

order constraint�����֮����:���ҽ���ͼ
G
Q
G_Q
GQ?��ͼ
G
T
G_T
GT?����ͼʱ,
G
Q
G_Q
GQ?��Ƕ��
z
q
z_q
zq?��ÿһ��ά���ϵ�ֵ��С�ڵ���ͼ
G
T
G_T
GT?��Ƕ��
z
u
z_u
zu?��Ӧ��ֵ,��Ƕ��ռ��Ƕ�ά��,���ǾͿ��Եõ�
z
q
z_q
zq?һ����
z
u
z_u
zu?�����·���
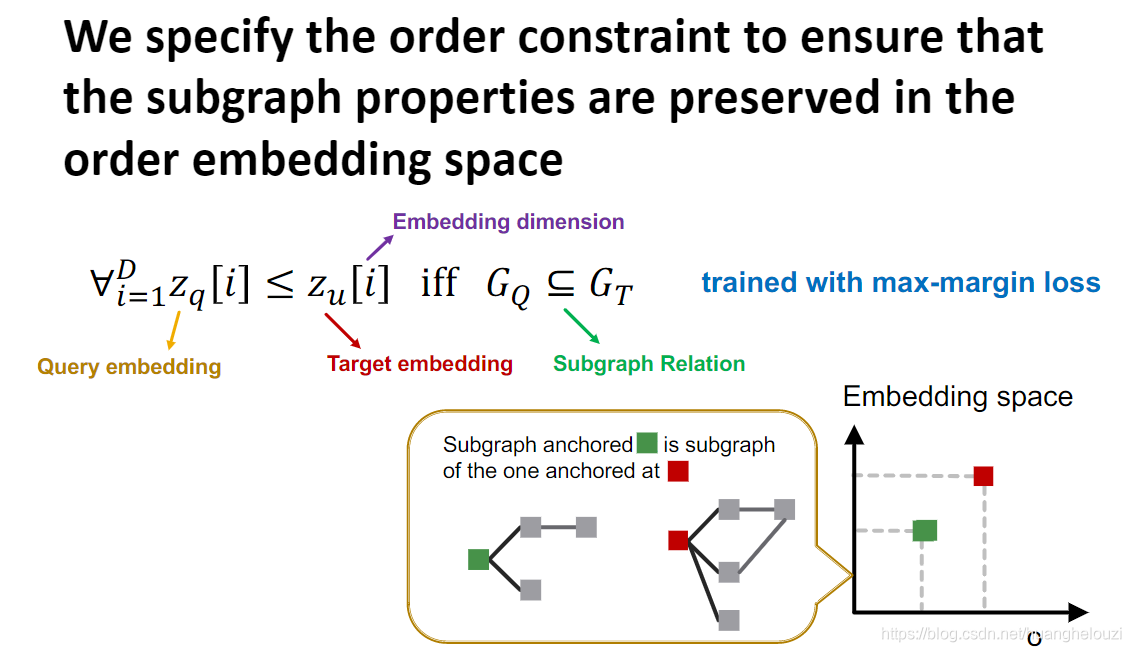
���������Լ��order constraint���ǿ�����Ƴ�ʹ������������ͼƥ��������ʹ�õ�Loss����:max-margin loss��������Ͳ����ϱ�
D
D
D�Ǹ�άǶ��ռ�ά��,ֻҪ��ͼǶ�벻��Ŀ��ͼǶ������·�,��Ȼ��ʹ�óͷ���
E
(
G
q
,
G
t
)
E(G_q, G_t)
E(Gq?,Gt?)>0,��Ϊ������һ��ά�ȵ���ͼǶ�����ͼǶ���ֵ��

����ƺ���ʧ������,�������ʹ�ý����ͼƥ��������������ѵ�����̡�ע������������Ҫ����ƽ��,����Ҳ������������������ķ�����

ѵ��������������: �������ݼ�
G
G
G�е�ÿһ��ѵ������
(
G
q
,
G
t
)
(G_q, G_t)
(Gq?,Gt?),��labelȡֵΪ0����1,1������ѯͼ
G
q
G_q
Gq?ΪĿ��ͼ
G
t
G_t
Gt?����ͼ,0��֮��
ÿ���������������·������:
Ŀ��ͼ
G
t
G_t
Gt?�������ݼ�ͼ
G
G
G�����ѡȡ��ê�ڵ�(anchor)
v
v
v�Լ���
k
k
k���ھӽڵ㹹�ɡ�
��������ѯͼ G q G_q Gq?(���Ǽ�Ϊ G q p G_{qp} Gqp?)����Ŀ��ͼ G t G_t Gt?���ɹ�������㷨��һ�����ʲ�������,����Ա�֤ G q p G_{qp} Gqp?һ����Ŀ��ͼ G t G_t Gt?����ͼ��
��������ѯͼ
G
q
G_q
Gq?(���Ǽ�Ϊ
G
q
n
G_{qn}
Gqn?)�Ƕ���������ѯͼ
G
q
p
G_qp
Gq?p�����Ŷ�(����ӱߡ�����,���ӽڵ�,ɾ���ڵ�)�õ���,����Ա�֤
G
q
n
G_{qn}
Gqn?һ������Ŀ��ͼ
G
t
G_t
Gt?����ͼ��
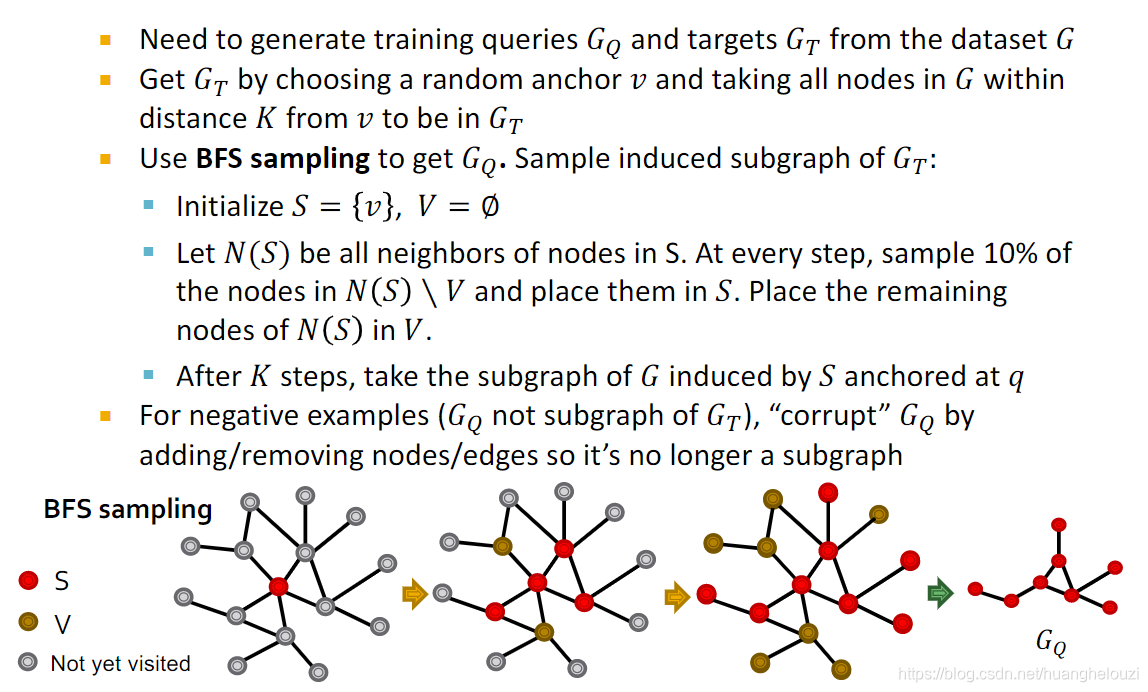
ѵ��������һЩϸ�ڲ���:

Ԥ���������Ĺ���:

�����ʹ�������������ͼƥ���������һ���ܽ�:

Finding Frequent Subgraphs
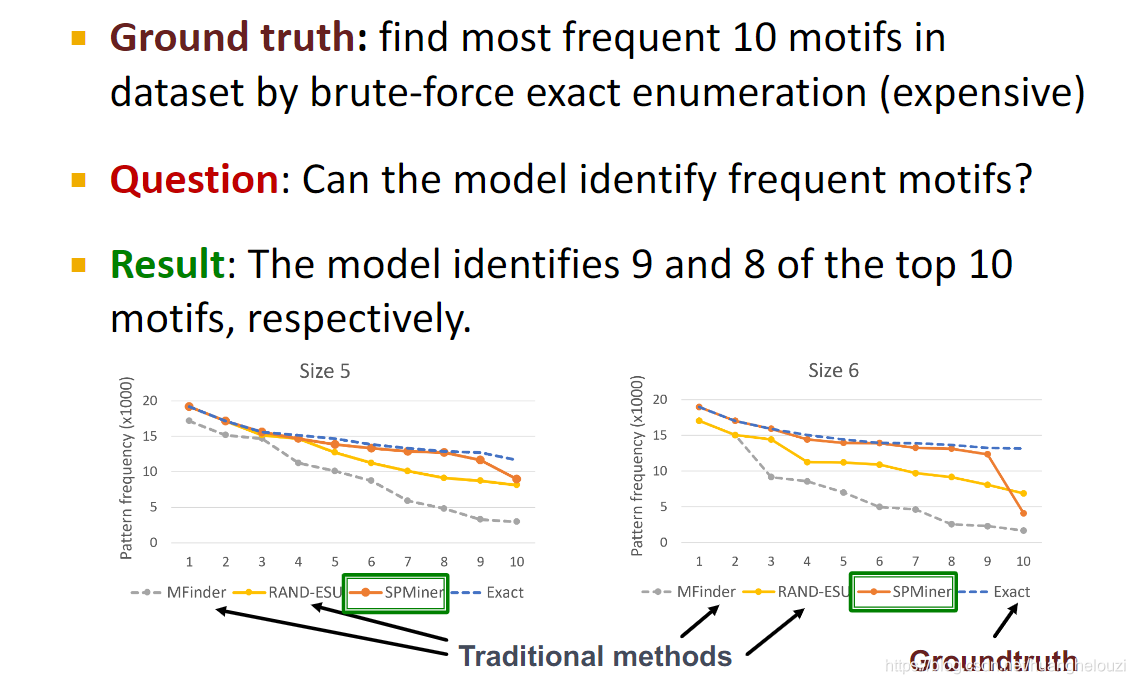
Ѱ��ͼ��Ƶ�����ֵ�ǰk��motif��һ��������ս�Ե�����,��Ϊ��Ѱ��һ���ض�motif���ֵ�Ƶ�ʶ���һ����Ҫ������������⡣
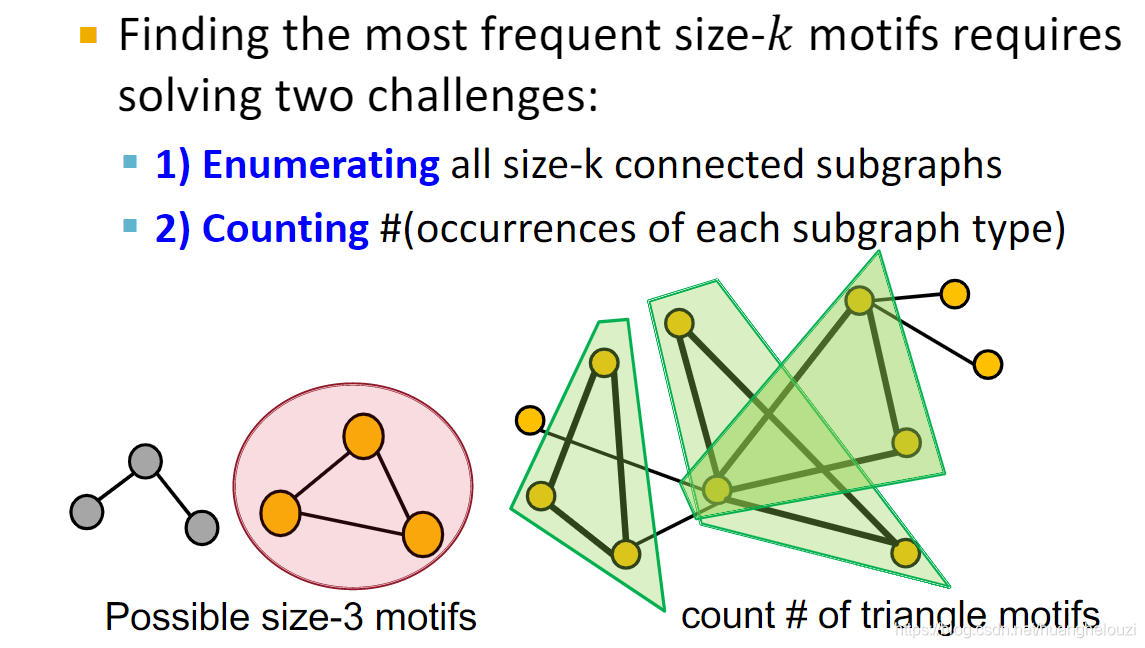

��ʹ��������(��ȷ�е�˵�DZ���ѧϰ)��Ѱ��Ƶ����ͼ���Խ��ͼ��㸴���ԡ�

���ǵ�Ŀ������Ŀ��ͼ
G
T
G_T
GT?��ʶ���Ƶ��Ϊǰ
r
r
r���Ҵ�СΪ
k
k
k���ڵ����ͼ����������Ҫѧϰ��ͼ��node-levelǶ��,��Ϊnode-levelǶ�������˵�����Ƚ���,���Խ�ʡ�ܶ������Դ��
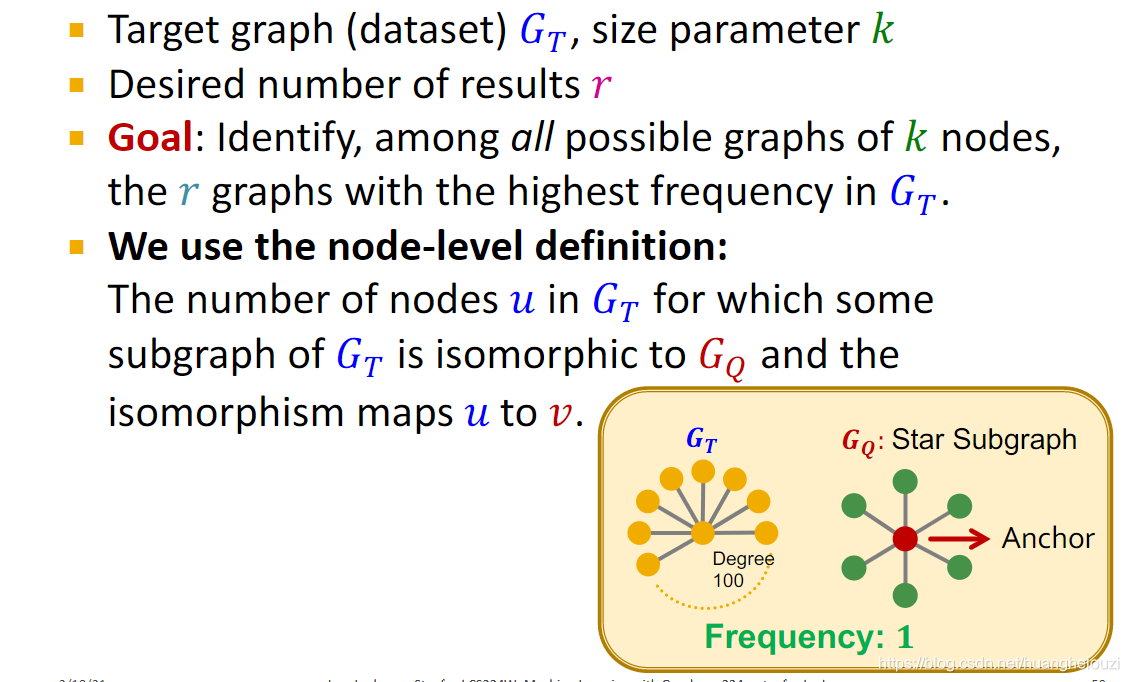
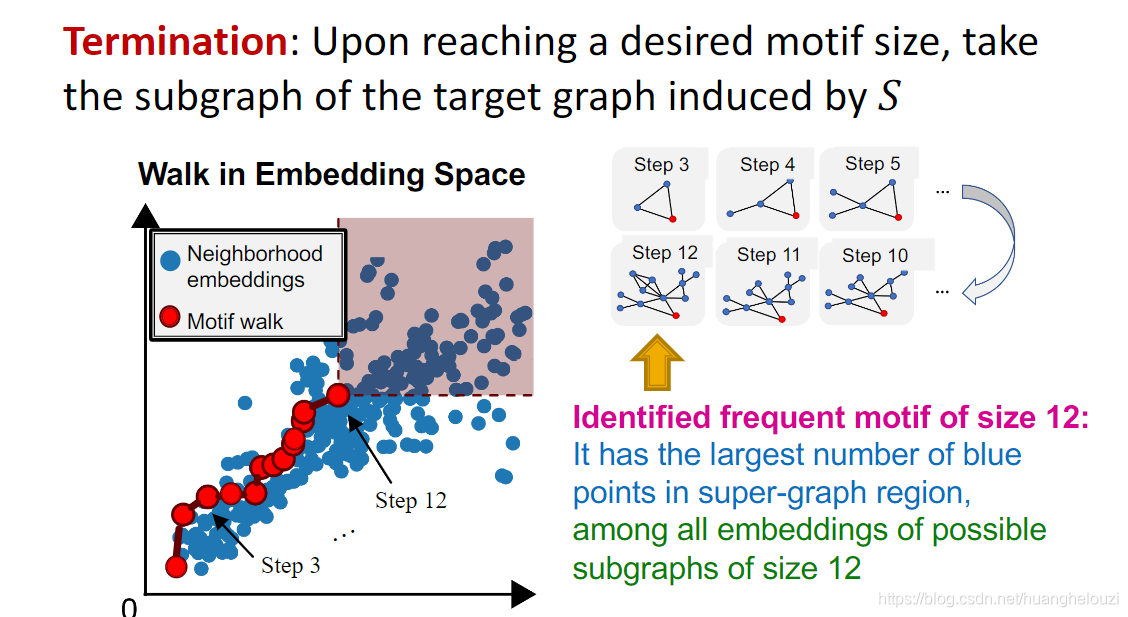
SPMiner����һ��ʶ���Ƶmotif��������ģ�͡�SPMiner��ǰ����������ͼƥ����������һ��,���µ������һ����Search Procedure����Search Procedure��һ���ݹ�Ĺ���,��һ�ε���ʱ�ҳ�һ���ڵ�anchor(һ���ڵ�������ͼ����ͼ),Ȼ���ҳ�anchorֱ�������Ľڵ�,ʹ���������ڵ㹹�ɵ���ͼΪĿ��ͼ�����Ƶ��ͼ(size=2);�ڶ��ε��������ҳ�����һ�������ڵ�ֱ��������һ���ڵ�,ʹ���������ڵ㹹�ɵ���ͼΪĿ��ͼ�����Ƶ��ͼ(size=3);����ִ��,ֱ������k��,�������ҳ�һ����k���ڵ㹹�ɵ����Ƶ��ͼ��(����̰���㷨,ÿһ�����ǵ�ǰ���ŵĽ��,�����Ľ����һ�������ŵ�)
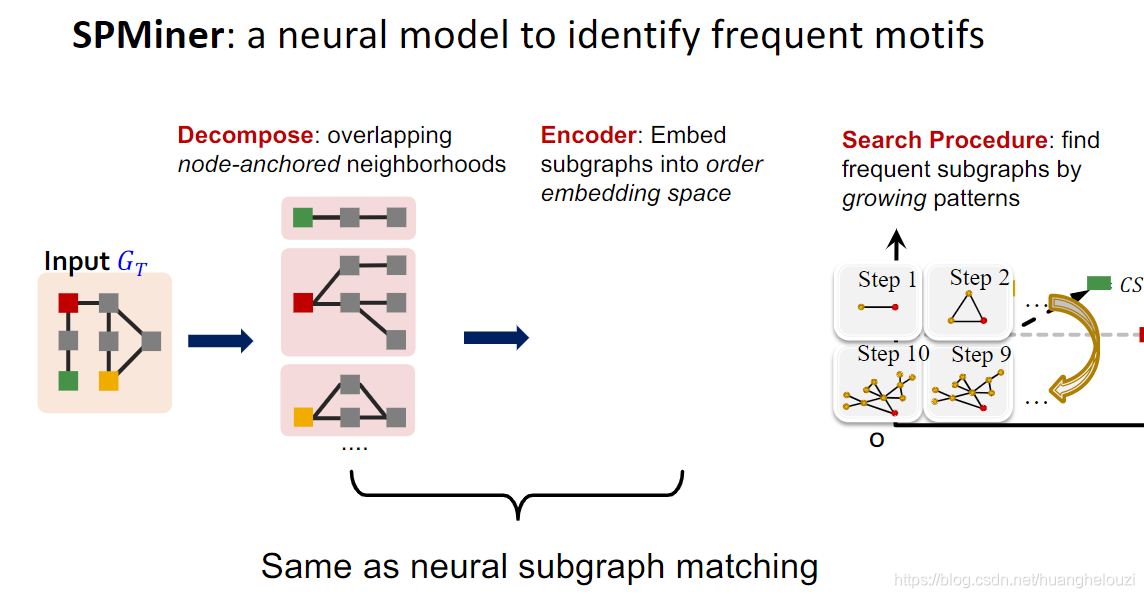
������SPminer����Ҫ˼��:

SPminer��Ƕ��Ŀ����:ʹ��motif��Ƕ��λ�����д�Ŀ��ͼ�г����õ�����ͼǶ������·���
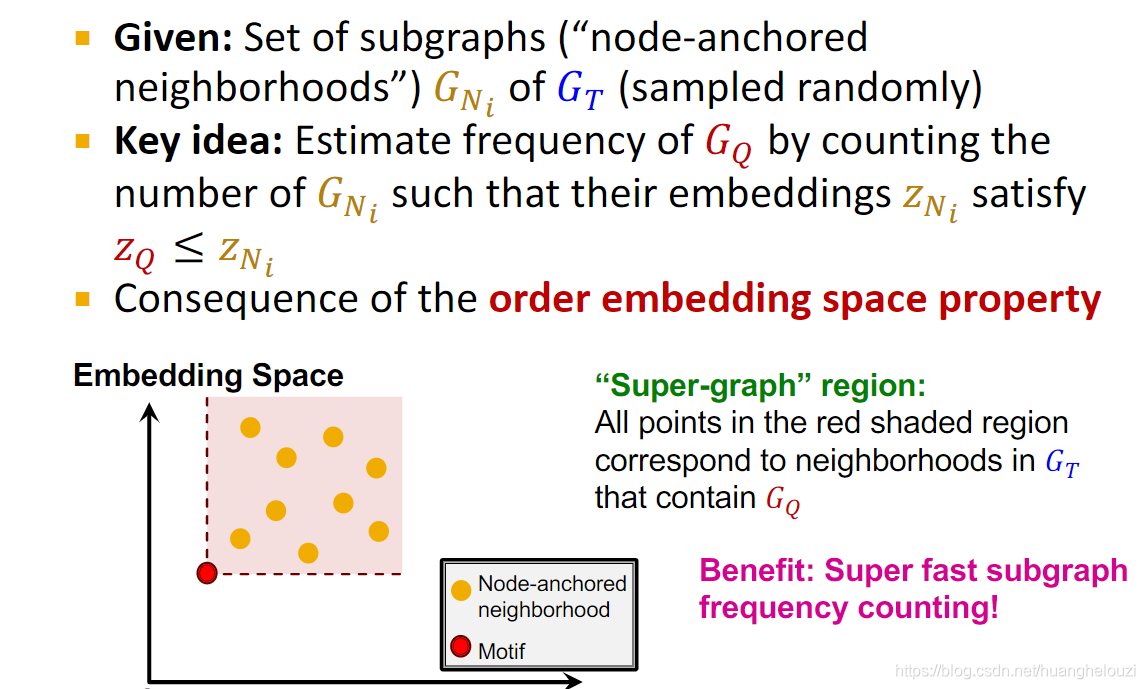
��������ϸ˵��Search Procedure��
�ڳ�ʼ��ʱ,���ѡȡһ���ڵ���Ϊê�ڵ㡣��Ҫע�����,�����ڵ�һ��������ͼ(������û�нڵ��ͼ)����ͼ
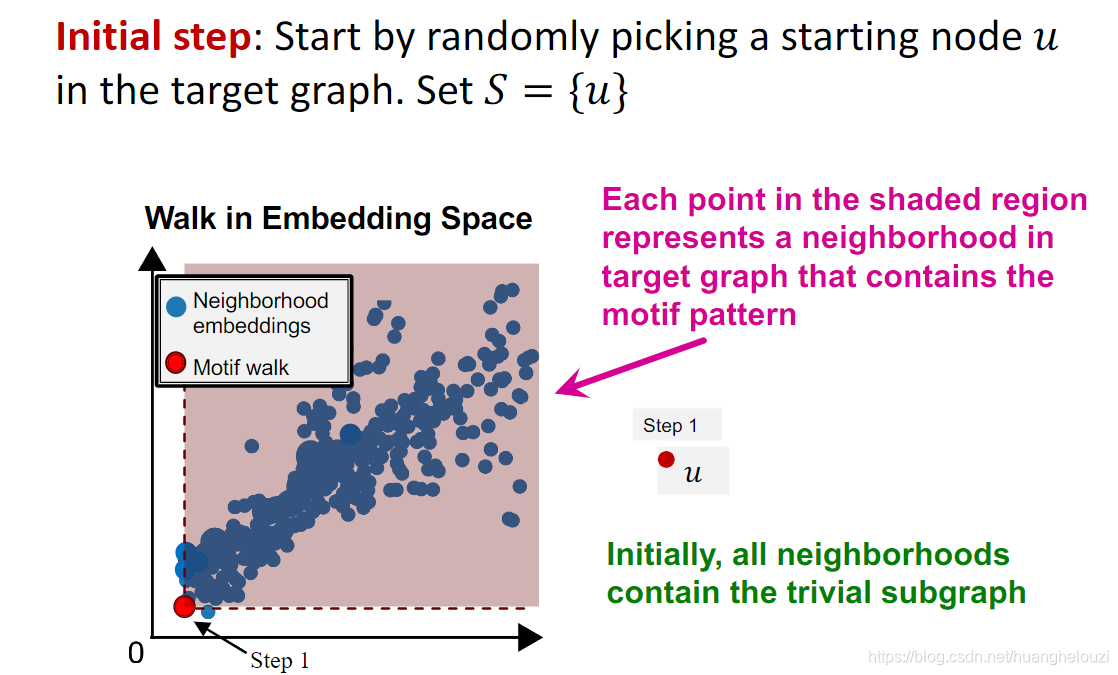
Ȼ�����k��,����������Ҫ����:��ɫ��Ӱ��������ɫȦȦ�������
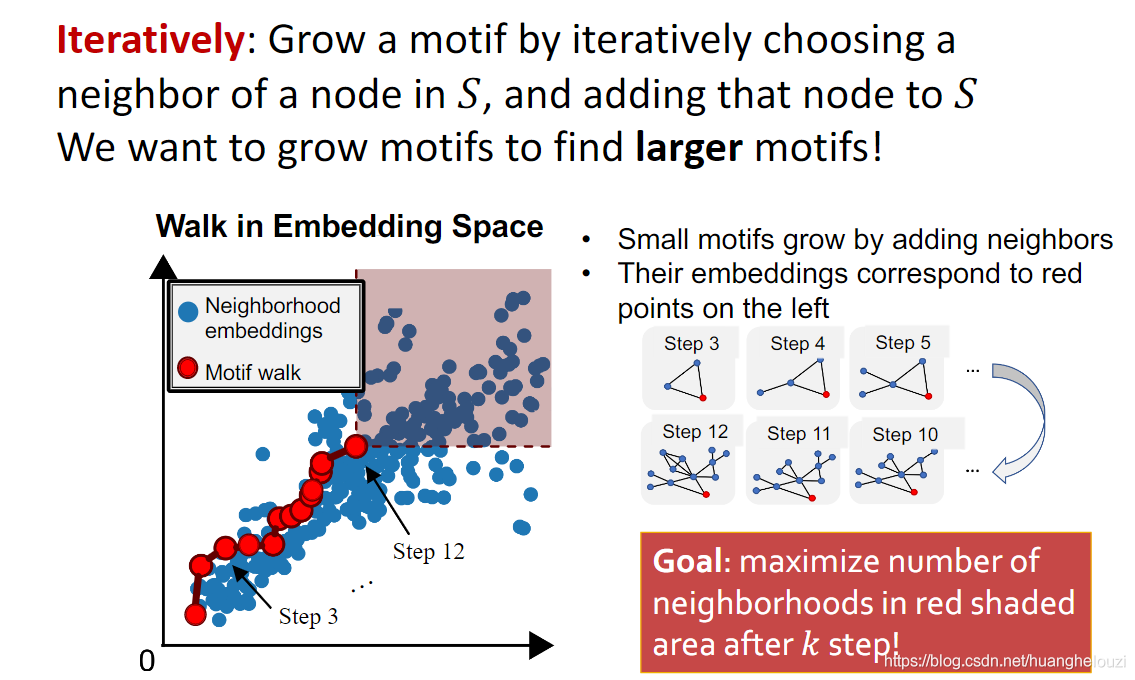
��ֹ������:����k��,���仰˵�����ҵ���һ���ڵ�����Ϊk�Ľڵ��յ���ͼ,ʹ����Ƕ��ռ��нڵ��յ���ͼ���Ϸ���ɫ��Ӱ�����е���ɫ���������
�ڱȽ�С��motif��,���Է���SPMiner���Դﵽ�ܸ߾���,�ֱ�����ҳ�Ƶ����ͼǰʮ���е�ǰ�Ÿ�����ǰ�˸���
�ڲ��Ҵ��motifʱ,SPMinerҲ����Ҫ���ڴ�ͳ������