Ŀ¼
ժҪ
֮ǰ�ĶԱȷ�������һ������ƫ������,���������ܿ�����������������ͬ������ṹ,�Ӷ����������½���Ϊ�˼���ó���ƫ��,���������һ��ԭ��ͼ�Ա�ѧϰ(PGCL)������
������˵,PGCLͨ�����������Ƶ�ͼ���ൽͬһ��������ͼ���ݵĵײ�����ṹ���н�ģ,ͬʱ����ͬһͼ�IJ�ͬ��ǿ�ľ���һ���ԡ�Ȼ��,����һ��������,ͨ������Щ����������Ⱥ��ͬ�ļ�Ⱥ����ȡͼ��ִ�и�����,��ȷ����������������֮���������졣����,����һ��������,PGCL��������������ԭ��(��������)��������ԭ��֮��ľ�������ĸ��������¸���Ȩ��,ʹ����Щ�����е�ԭ�;���ĸ����������Խϴ��Ȩ��,�Ա�֤�������븺����֮���������졣�������¸���Ȩ�ز��Ա�֤���Ⱦ��ȳ�������Ч��
1 ����
���е��Լලͼ�Ա�ѧϰ�����������¾�����:
- ���еķ�����Ҫ��ע��ʵ�����ṹ�����ԵĽ�ģ,ֻ����ʵ����Χ�ľֲ�������,��δ�ܷ����������ݷֲ��еĵײ�ȫ�ֽṹ������ʵ����,����������,ͼ�����ж�����DZ�ڵ�ȫ�ֽṹ��
- ��ͼ��ʾ1,���������ݷֲ��о��Ȳ������������ܻᵼ�¸������������������������ơ�
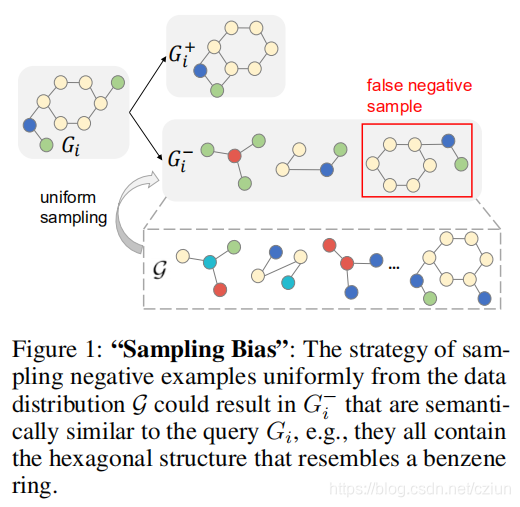
�������ݼ���ȫ������ṹ��PGCL��ԭ������(����ѵ���ľ�������)��������
2 ��ع���
���ھ���ĶԱ�ѧϰ: GraphLoGӦ��K-means����������ͼ������ṹ,��ʹ��K-means���ܻᵼ��ԭ�͵ķ��䲻ƽ�⡣��GraphLoG���,PGCL������ԭ�ͷ�����뻮��Ϊ��ͬ��С���Ӽ���Լ������,���������Ϊ���Ŵ������⡣����,PGCL��Ŀ����ͨ��������������Ⱥ��ͬ�ļ�Ⱥ�в���������,��������ԭ�;������¸�Ȩ������,���������ƫ�
3 ������
3.1 ���ⶨ��
�ֲ�ʵ���ṹ�� ���ǽ���ͬͼ��֮��ľֲ��ɶ������Գ�Ϊ�ֲ�ʵ���ṹ���ڶԱ�ѧϰ�ķ�ʽ��,���Ƶ�ͼ�Ե�Ƕ��Ԥ����DZ�ڿռ��кܽӽ�,����ͬ��ͼ��Ӧ��ӳ��ú�Զ��
���Ծֲ�ʵ���ṹ���н�ģͨ�������Է����������ݼ��ײ��ȫ�����塣���Ƿdz�ϣ���������ݵ�ȫ������ṹ,�䶨������:
ȫ������ṹ�� ������ʵ�����ͼ�ṹ����ͨ�����Ա���֯Ϊ�������弯Ⱥ��DZ�ڿռ����ڽ�ͼ��Ƕ��Ӧ������ȫ�ֽṹ,�Ӷ���ӳԭʼ���ݵ�����ģʽ��
�������á� ����һ��δ���ͼ G = { G i } i = 1 N \mathcal{G}=\{G_i\}^N_{i=1} G={Gi?}i=1N?,�ලͼ��ʾѧϰ��Ŀ����ѧϰÿ��ͼ G i �� G G_i��\mathcal{G} Gi?��G�ĵ�ά���� z i �� R D z_i��\mathbb{R}^D zi?��RD,��������ͼ�������������
3.2 GNN
���ǽ�һ��ͼʵ����ʾΪ
G
=
(
V
,
E
)
G=(\mathcal{V},\mathcal{E})
G=(V,E),�ڵ㼯Ϊ
V
\mathcal{V}
V,��Ϊ
E
\mathcal{E}
E���ڵ�
k
k
k�ε���ʱ,�ڵ�
v
v
v�ڵ�
k
k
k���Ƕ��Ϊ:
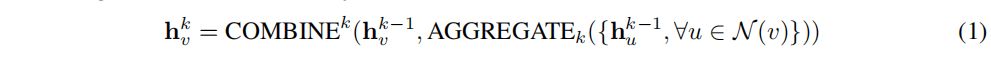
Ȼ��,����ͨ��ʹ�ö��������ۺ����нڵ��ʾ�����ͼ����ʾ,��:
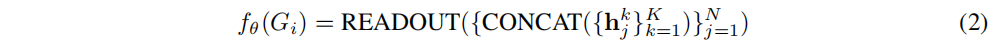
READOUT��ʾƽ��������ӵ�ͼ���ػ�������
3.3 ͼ�Ա�ѧϰ

4 PGCL
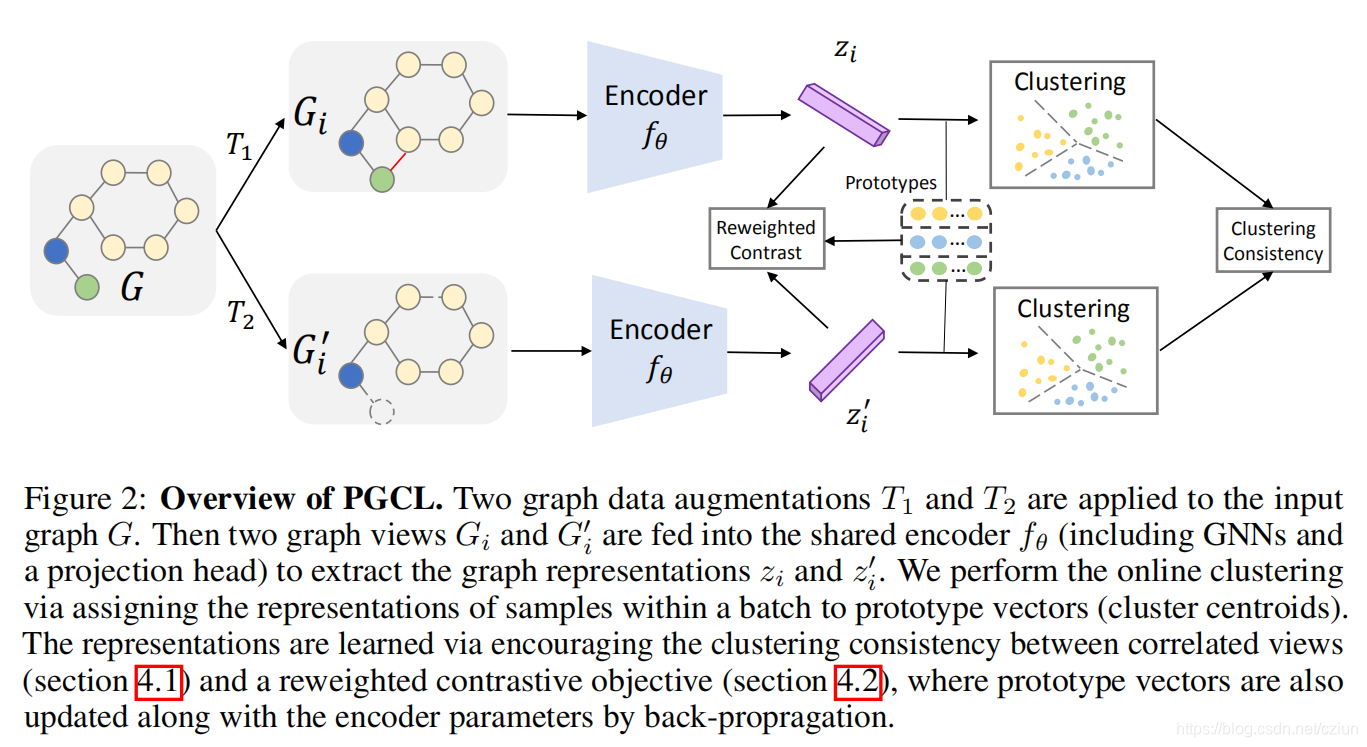
��ͼ2��ʾ,��������ǿ��ͼ�ı�ʾ���о���,�Ծ�����ͬ��ԭ��(��������)��
4.1 �����ͼ�ľ���һ����
��ʽ��,����һ����ͼ��
G
i
G_i
Gi?ӳ�䵽��ʾ����
z
i
��
R
D
z_i��\mathbb{R}^D
zi?��RD��ͼ������
z
i
=
f
��
(
G
i
)
z_i=f_��(G_i)
zi?=f��?(Gi?)�����ǿ��Խ����б�ʾ
z
i
z_i
zi?�����
K
K
K����,��������һ���ѵ��ԭ������
{
c
1
,
��
,
c
K
}
\{c_1,��,c_K\}
{c1?,��,cK?}��ʾ��Ϊ�˼�����,������
C
��
R
K
��
D
C��\mathbb{R}^{K��D}
C��RK��D��ʾ����ʵ����,
C
C
C����ͨ���������Բ���ʵ�֡�����,����һ��
G
i
G_i
Gi?ͼ,���ǿ���ͨ�������ʾ
z
i
=
f
��
(
G
i
)
z_i=f_��(G_i)
zi?=f��?(Gi?)��
K
K
Kԭ��֮�����������ִ�о���,����:
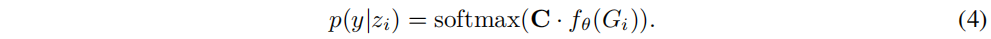
ͬ����,��
G
i
��
G_i'
Gi��?�����ԭ�͵�Ԥ��
p
(
y
�O
z
i
��
)
p(y|z_i')
p(y�Ozi��?)Ҳ����ͨ��
z
i
��
z_i'
zi��?�����㡣Ϊ�˹������������ͼ
G
i
G_i
Gi?��
G
i
��
G_i'
Gi��?֮��ľ���һ����,������
z
i
z_i
zi?(������
z
i
��
z_i'
zi��?)��Ԥ��
G
i
��
G_i'
Gi��?�ľ������,��֮��Ȼ����ʽ��,����ͨ����С��ƽ����������ʧ���������һ����Ŀ��:
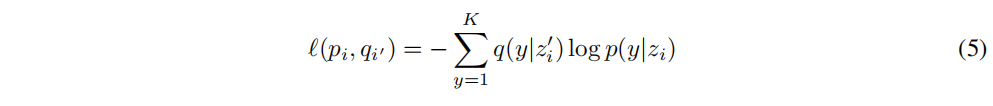
����,
q
(
y
�O
z
i
��
)
q(y|z_i')
q(y�Ozi��?)����ͼ
G
i
��
G_i'
Gi��?��ԭ�ͷ���,������Ϊ
z
i
z_i
zi?��Ԥ��
p
(
y
�O
z
i
)
p(y|z_i)
p(y�Ozi?)��Ŀ�ꡣһ����Ŀ����Ϊһ��������,��������ͬһͼ����ͼ�������ԡ�������ǽ�������(5)��
z
i
z_i
zi?��
z
i
��
z_i'
zi��?��λ��,���ǿ��Եõ���һ�����Ƶ�Ŀ�ꡣ���յ�һ��������������ͨ������Ŀ��ĺ͵���:
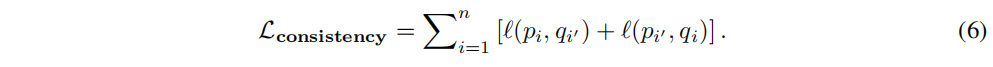
һ�������������Խ���Ϊͨ���Ƚϼ�Ⱥ��������DZ�ʾ���Ƚ϶��ͼ����ͼ����ʵ��Ӧ����,�ֲ�
q
q
q���Ż������Ŵ��ڵļ�������,��Ϊͨ�����������ݵ�����һ��(�����)ԭ��,�Ϳ��Լ���С��(5)��Ϊ�˱����������,����������ԭ�ͷ�����뱻ƽ��������Լ����������С�����ķ�ʽ����Ŀ��,��ʵ����Ч���Ż�:
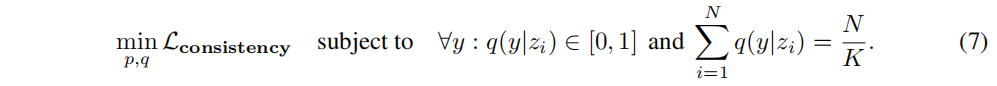
����(7)�е�Ŀ����
q
q
q������ϵ�,��˿��ܺ����Ż���Ȼ��,�������Ŵ��������һ��ʵ��,���������Ч�ؽ����Ϊ�˸�����ؿ�����,���ǽ��������ϸ��ʵ�
K
��
N
K��N
K��N�����ʾΪ:
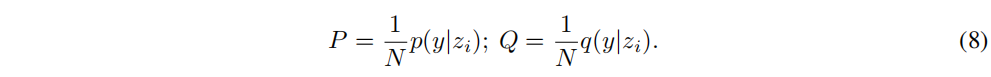
Ȼ��,���ǿ���ͨ����С������ʽ������
Q
Q
QԼ��Ϊ�����������ʵ����ȵķָ�:
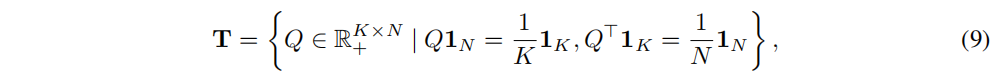
����,
1
K
1_K
1K?��ʾά��Ϊ
K
K
K��ȫ��1����������ЩԼ��Ҫ��ÿ��ԭ������������ƽ��ѡ������
N
K
\frac{N}{K}
KN?�Ρ�Ȼ��,����(7)�е�Ŀ�꺯����������дΪ:
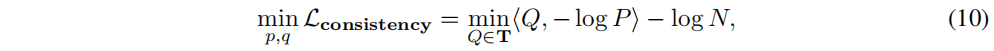
����,
?
?
?
\langle��\rangle
???����������֮���Frobenius���,
l
o
g
log
log������Ԫ�ؼ��ġ��Ż�����(10)���ǵ���һ��������,���ܽ�
Q
Q
Q�ſ�������������
T
T
T��������ɢ�����塣����ͨ������Sinkhorn-Knopp�㷨�Ŀ��ٰ汾�������������,���ҷ���(10)�Ľ���ù淶���������ʽ,������ʾ:
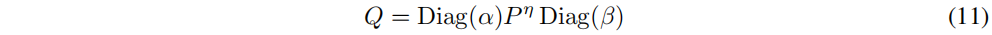
����,
��
��
����
��
��
������������������,ָ������Ԫ�ؼ��ġ�ѡ��
��
��
����Ϊ��Ȩ�������ٶ���ԭʼ��������Ľӽ��̶�,�����ǵ�������,����һ���̶���ֵ����������������ʹ�õ�����Sinkhorn-Knopp�㷨,ʹ�������ľ���˷������㡣
4.2 �ؼ�Ȩ�Ա�Ŀ��
�ڱ�����,���ǽ��������ͨ���Ӳ�ͬ�ļ�Ⱥ����ͼ,���Ը������������¼�Ȩ���������ƫ�����⡣����һ�����������伯Ⱥ,���ǿ��Լ�ͨ���Ӳ�ͬ�ļ�Ⱥ����ȡ����ȷ�ġ���������ʵ����һ�㡣����(3)������չΪ:
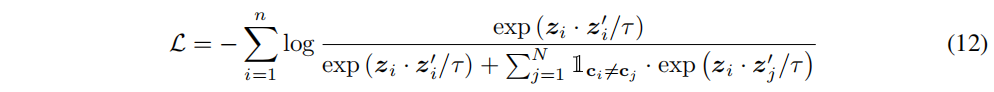
����,
c
i
c_i
ci?��
c
j
c_j
cj?�ֱ�Ϊͼ
G
i
G_i
Gi?��
G
j
G_j
Gj?��ԭ������,
1
c
i
��
c
j
\mathbb{1}_{c_i��c_j}
1ci?��?=cj??�DZ�ʾ���������Ƿ����Բ�ͬ�ص�ָ�ꡣ
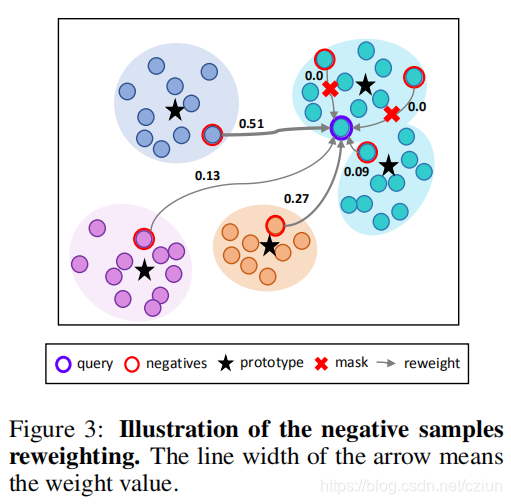
���˸����伯Ⱥ��������ѡ��������,���ǻ�ϣ��������DZ�ڿռ���ѡ��Զ����������̫��������ֱ�۵�˵,����ĸ�����Ӧ�������������ʶȵľ��롣Ϊ��ʵ����һ����,���������ڿ������ǵ�ԭ�;���,���������ǵ�ֱ�Ӿ��롣��ͼ3��ʾ,һ����,�����������ԭ��̫�ӽ�query��ԭ��,��������Ȼ������query�������Ƶ�����ṹ(����,��������ɫ��Ⱥ)����һ����,�����������ԭ��(����ɫ��)��query��ԭ�ͺ�Զ,����ζ�Ÿ�������query�˴�����Զ,���Ժܺõ�����,��ʵ���϶Ա�ʾѧϰû�а�����
Ϊ��,���ǽ�һ�����¼��㷽��(12)�и��������Ȩ��,�������¼�Ȩ��Ŀ�궨��Ϊ:
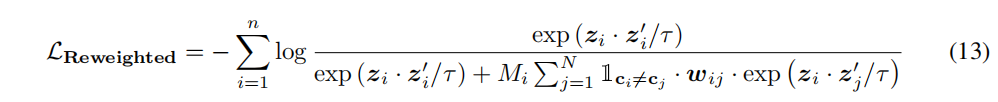
����,
w
i
j
w_{ij}
wij?����
(
G
i
,
G
j
)
(G_i,G_j)
(Gi?,Gj?)��Ȩ��,
M
i
=
N
��
j
=
1
N
w
i
j
M_i=\frac{N}{\sum_{j=1}^Nw_{ij}}
Mi?=��j=1N?wij?N?�ǹ�һ�����ӡ������������Ҿ�������������ԭ��֮��ľ���,��:
D
(
c
i
,
c
j
)
=
1
?
c
i
?
c
j
�O
�O
c
i
�O
�O
2
�O
�O
c
j
�O
�O
2
\mathcal{D}(c_i,c_j)=1-\frac{c_i��c_j}{||c_i||_2||c_j||_2}
D(ci?,cj?)=1?�O�Oci?�O�O2?�O�Ocj?�O�O2?ci??cj??��Ȼ���������ԭ�;���,��
w
i
j
w_{ij}
wij?�����˹��������ʽ:
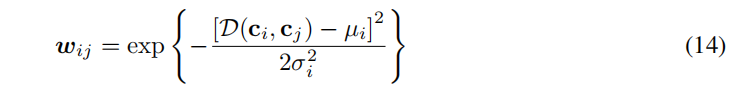
����,
��
i
\mu_i
��i?��
��
i
\sigma_i
��i?�ֱ�Ϊ
D
(
c
i
,
c
j
)
\mathcal{D}(c_i,c_j)
D(ci?,cj?)��ƽ��ֵ�ͱ��
���յ�ѵ��Ŀ��Ϊ:
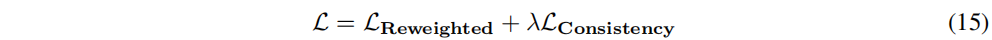
��С������ʧ�������Ż�ԭ��
C
C
C��ͼ�������IJ���
��
��
����
5 ʵ��