目录
前言
源码: YOLOv5源码.
导航: 【YOLOV5-5.x 源码讲解】整体项目文件导航.
这个文件是通过 k-means 聚类 + 遗传算法来生成和当前数据集匹配度更高的anchors。如果要使用这个脚本要注意两点:
-
train.py的parse_opt下的参数noautoanchor必须为False

-
hyp.scratch.yaml下的anchors参数必须注释掉

什么是k-means?
\qquad k-means是非常经典且有效的聚类方法,通过计算样本之间的距离(相似程度)将较近的样本聚为同一类别(簇)。
使用k-means时主要关注两点
- 如何表示样本与样本之间的距离(核心问题),这个一般需要根据具体场景去设计,不同的方法聚类效果也不同,最常见的就是欧式距离,在目标检测领域常见的是IOU。
- 分为几类,这个也是需要根据应用场景取选择的,也是一个超参数。
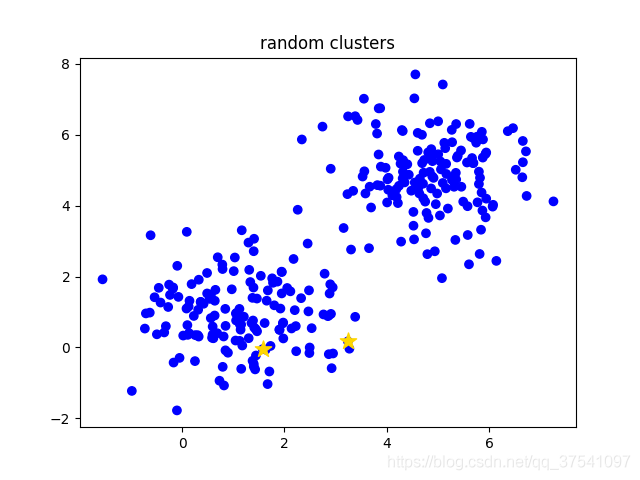
k-means算法主要流程
- 手动设定簇的个数k,假设k=2;
- 在所有样本中随机选取k个样本作为簇的初始中心,如下图(random clusters)中两个黄色的小星星代表随机初始化的两个簇中心;
- 计算每个样本离每个簇中心的距离(这里以欧式距离为例),然后将样本划分到离它最近的簇中。如下图(step 0)用不同的颜色区分不同的簇;
- 更新簇的中心,计算每个簇中所有样本的均值(方法不唯一)作为新的簇中心。如下图(step 1)所示,两个黄色的小星星已经移动到对应簇的中心;
- 重复第3步到第4步直到簇中心不在变化或者簇中心变化很小满足给定终止条件。如下图(step2)所示,最终聚类结果。



什么是bpr?
BPR(bpr best possible recall来源于论文: FCOS.
原论文解释:
BPR is defined as the ratio of the number of ground-truth boxes a detector can recall at the most divided by all ground-truth boxes. A ground-truth box is considered being recalled if the box is assigned to at least one sample (i.e., a location in FCOS or an anchor box in anchor-based detectors) during training.
\qquad bpr(best possible recall): 最多能被召回的gt框数量 / 所有gt框数量 最大值为1 越大越好 小于0.98就需要使用k-means + 遗传进化算法选择出与数据集更匹配的anchors框。
什么是白化操作whiten?
\qquad 白化的目的是去除输入数据的冗余信息。假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的;白化的目的就是降低输入的冗余性。
输入数据集X,经过白化处理后,新的数据X’满足两个性质:
- 特征之间相关性较低;
- 所有特征具有相同的方差=1
\qquad 常见的作法是:对每一个数据做一个标准差归一化处理(除以标准差)。scipy.cluster.vq.kmeans() 函数输入的数据就是必须是白化后的数据。相应的输出的anchor k也是白化后的anchor,所以需要将anchor k 都乘以标准差恢复。
0、导入需要的包
import numpy as np # numpy矩阵操作模块
import matplotlib.pyplot as plt # matplotlib画图模块
import torch # PyTorch深度学习模块
import yaml # 操作yaml文件模块
from tqdm import tqdm # Python进度条模块
from utils.general import colorstr
from utils.metrics import wh_iou
1、check_anchor_order
\qquad 这个函数用于确认当前anchors和stride的顺序是否是一直的,因为我们的m.anchors是相对各个feature map(每个feature map的感受野不同 检测的目标大小也不同 适合的anchor大小也不同)所以必须要顺序一致 否则效果会很不好。这个函数一般用于check_anchors最后阶段。
def check_anchor_order(m):
"""用在check_anchors最后 确定anchors和stride的顺序是一致的
Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
:params m: model中的最后一层 Detect层
"""
# 计算anchor的面积 anchor area [9]
# tensor([134.4, 576.3, 1302.2, 5027.15, 12354.6, 25296.5e, 77122.3, 161472, 245507])
a = m.anchor_grid.prod(-1).view(-1)
# 计算最大anchor与最小anchor面积差
da = a[-1] - a[0] # delta a tensor(245372.65625)
# 计算最大stride与最小stride差
ds = m.stride[-1] - m.stride[0] # delta s tensor(24.)
# torch.sign(x):当x大于/小于0时,返回1/-1
# 如果这里anchor与stride顺序不一致,则重新调整顺序
if da.sign() != ds.sign(): # same order
print('Reversing anchor order')
m.anchors[:] = m.anchors.flip(0)
m.anchor_grid[:] = m.anchor_grid.flip(0)
2、check_anchors
\qquad 这个函数是通过计算bpr确定是否需要改变anchors 需要就调用k-means重新计算anchors。
def check_anchors(dataset, model, thr=4.0, imgsz=640):
"""用于train.py中
通过bpr确定是否需要改变anchors 需要就调用k-means重新计算anchors
Check anchor fit to data, recompute if necessary
:params dataset: 自定义数据集LoadImagesAndLabels返回的数据集
:params model: 初始化的模型
:params thr: 超参中得到 界定anchor与label匹配程度的阈值
:params imgsz: 图片尺寸 默认640
"""
# 一些可视化: autoanchor: Analyzing anchors...
prefix = colorstr('autoanchor: ')
print(f'\n{prefix}Origin anchors... ')
# m: 从model中取出最后一层(Detect)
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
# dataset.shapes.max(1, keepdims=True) = 每张图片的较长边
# shapes: 将数据集图片的最长边缩放到img_size, 较小边相应缩放 得到新的所有数据集图片的宽高 [N, 2]
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
# 产生随机数scale [2501, 1]
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
# [6301, 2] 所有target(6301个)的wh 基于原图大小 shapes * scale: 随机化尺度变化
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
def metric(k):
"""用在check_anchors函数中 compute metric
根据数据集的所有图片的wh和当前所有anchors k计算 bpr(best possible recall) 和 aat(anchors above threshold)
:params k: anchors [9, 2] wh: [N, 2]
:return bpr: best possible recall 最多能被召回(通过thr)的gt框数量 / 所有gt框数量 小于0.98 才会用k-means计算anchor
:return aat: anchors above threshold 每个target平均有多少个anchors
"""
# None添加维度 所有target(gt)的wh wh[:, None] [6301, 2]->[6301, 1, 2]
# 所有anchor的wh k[None] [9, 2]->[1, 9, 2]
# r: target的高h宽w与anchor的高h_a宽w_a的比值,即h/h_a, w/w_a [6301, 9, 2] 有可能大于1,也可能小于等于1
r = wh[:, None] / k[None]
# x 高宽比和宽高比的最小值 无论r大于1,还是小于等于1最后统一结果都要小于1 [6301, 9]
x = torch.min(r, 1. / r).min(2)[0]
# best [6301] 为每个gt框选择匹配所有anchors宽高比例值最好的那一个比值
best = x.max(1)[0]
# aat(anchors above threshold) 每个target平均有多少个anchors
aat = (x > 1. / thr).float().sum(1).mean() # 当axis=1时,求的是每一行元素的和
# bpr(best possible recall) = 最多能被召回(通过thr)的gt框数量 / 所有gt框数量 小于0.98 才会用k-means计算anchor
bpr = (best > 1. / thr).float().mean()
fitness = (best * (best > 1. / thr).float()).mean()
return bpr, aat, fitness
# anchors: [N,2] 所有anchors的宽高 基于缩放后的图片大小(较长边为640 较小边相应缩放)
anchors = m.anchor_grid.clone().cpu().view(-1, 2) # current anchors
# 计算出数据集所有图片的wh和当前所有anchors的bpr和aat
# bpr: bpr(best possible recall): 最多能被召回(通过thr)的gt框数量 / 所有gt框数量 [1] 0.96223 小于0.98 才会用k-means计算anchor
# aat(anchors past thr): [1] 3.54360 通过阈值的anchor个数
bpr, aat, fitness = metric(anchors)
print(f"aat: {aat:.5f}, fitness: {fitness:.5f}, best possible recall: {bpr:.5f}")
print(" ".join([f"[{int(i[0])}, {int(i[1])}]" for i in anchors]))
# threshold to recompute
# 考虑这9类anchor的宽高和gt框的宽高之间的差距, 如果bpr<0.98(说明当前anchor不能很好的匹配数据集gt框)就会根据k-means算法重新聚类新的anchor
if bpr < 0.98:
print('. Attempting to improve anchors, please wait...')
na = m.anchor_grid.numel() // 2 # number of anchors
try:
# 如果bpr<0.98(最大为1 越大越好) 使用k-means + 遗传进化算法选择出与数据集更匹配的anchors框 [9, 2]
anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
except Exception as e:
print(f'{prefix}ERROR: {e}')
# 计算新的anchors的new_bpr
new_bpr = metric(anchors)[0]
# 比较k-means + 遗传进化算法进化后的anchors的new_bpr和原始anchors的bpr
# 注意: 这里并不一定进化后的bpr必大于原始anchors的bpr, 因为两者的衡量标注是不一样的 进化算法的衡量标准是适应度 而这里比的是bpr
if new_bpr > bpr: # replace anchors
anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
# 替换m的anchor_grid [9, 2] -> [3, 1, 3, 1, 1, 2]
m.anchor_grid[:] = anchors.clone().view_as(m.anchor_grid) # for inference
# 替换m的anchors(相对各个feature map) [9, 2] -> [3, 3, 2]
m.anchors[:] = anchors.clone().view_as(m.anchors) / m.stride.to(m.anchors.device).view(-1, 1, 1) # loss
# 检查anchor顺序和stride顺序是否一致 不一致就调整
# 因为我们的m.anchors是相对各个feature map 所以必须要顺序一致 否则效果会很不好
check_anchor_order(m)
print(f'{prefix}New anchors saved to model. Update model *.yaml to use these anchors in the future.')
else:
print(f'{prefix}Original anchors better than new anchors. Proceeding with original anchors.')
print('') # newline
这个函数会在train.py中调用:

3、kmean_anchors
\qquad 这个函数才是这个这个文件的核心函数,功能:使用K-means + 遗传算法 算出更符合当前数据集的anchors。
\qquad 这里不仅仅使用了k-means聚类,还使用了Genetic Algorithm遗传算法,在k-means聚类的结果上进行mutation变异。接下来简单介绍下代码流程:
- 载入数据集,得到数据集中所有数据的wh
- 将每张图片中wh的最大值等比例缩放到指定大小img_size,较小边也相应缩放
- 将bboxes从相对坐标改成绝对坐标(乘以缩放后的wh)
- 筛选bboxes,保留wh都大于等于两个像素的bboxes
- 使用k-means聚类得到n个anchors(掉k-means包 涉及一个白化操作)
- 使用遗传算法随机对anchors的wh进行变异,如果变异后效果变得更好(使用anchor_fitness方法计算得到的fitness(适应度)进行评估)就将变异后的结果赋值给anchors,如果变异后效果变差就跳过,默认变异1000次
\qquad
如果不知道什么是遗传算法,可以看看这两个b站视频:遗传算法超细致+透彻理解 和 霹雳吧啦Wz
def kmean_anchors(path='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
"""在check_anchors中调用
使用K-means + 遗传算法 算出更符合当前数据集的anchors
Creates kmeans-evolved anchors from training dataset
:params path: 数据集的路径/数据集本身
:params n: anchor框的个数
:params img_size: 数据集图片约定的大小
:params thr: 阈值 由hyp['anchor_t']参数控制
:params gen: 遗传算法进化迭代的次数(突变 + 选择)
:params verbose: 是否打印所有的进化(成功的)结果 默认传入是Fasle的 只打印最佳的进化结果即可
:return k: k-means + 遗传算法进化 后的anchors
"""
from scipy.cluster.vq import kmeans
# 注意一下下面的thr不是传入的thr,而是1/thr, 所以在计算指标这方面还是和check_anchor一样
thr = 1. / thr # 0.25
prefix = colorstr('autoanchor: ')
def metric(k, wh): # compute metrics
"""用于print_results函数和anchor_fitness函数
计算ratio metric: 整个数据集的gt框与anchor对应宽比和高比即:gt_w/k_w,gt_h/k_h + x + best_x 用于后续计算bpr+aat
注意我们这里选择的metric是gt框与anchor对应宽比和高比 而不是常用的iou 这点也与nms的筛选条件对应 是yolov5中使用的新方法
:params k: anchor框
:params wh: 整个数据集的wh [N, 2]
:return x: [N, 9] N个gt框与所有anchor框的宽比或高比(两者之中较小者)
:return x.max(1)[0]: [N] N个gt框与所有anchor框中的最大宽比或高比(两者之中较小者)
"""
# [N, 1, 2] / [1, 9, 2] = [N, 9, 2] N个gt_wh和9个anchor的k_wh宽比和高比
# 两者的重合程度越高 就越趋近于1 远离1(<1 或 >1)重合程度都越低
r = wh[:, None] / k[None]
# r=gt_height/anchor_height gt_width / anchor_width 有可能大于1,也可能小于等于1
# torch.min(r, 1. / r): [N, 9, 2] 将所有的宽比和高比统一到<=1
# .min(2): value=[N, 9] 选出每个gt个和anchor的宽比和高比最小的值 index: [N, 9] 这个最小值是宽比(0)还是高比(1)
# [0] 返回value [N, 9] 每个gt个和anchor的宽比和高比最小的值 就是所有gt与anchor重合程度最低的
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
# x.max(1)[0]: [N] 返回每个gt和所有anchor(9个)中宽比/高比最大的值
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
"""用于kmean_anchors函数
适应度计算 优胜劣汰 用于遗传算法中衡量突变是否有效的标注 如果有效就进行选择操作 没效就继续下一轮的突变
:params k: [9, 2] k-means生成的9个anchors wh: [N, 2]: 数据集的所有gt框的宽高
:return (best * (best > thr).float()).mean()=适应度计算公式 [1] 注意和bpr有区别 这里是自定义的一种适应度公式
返回的是输入此时anchor k 对应的适应度
"""
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k):
"""用于kmean_anchors函数中打印k-means计算相关信息
计算bpr、aat=>打印信息: 阈值+bpr+aat anchor个数+图片大小+metric_all+best_mean+past_mean+Kmeans聚类出来的anchor框(四舍五入)
:params k: k-means得到的anchor k
:return k: input
"""
# 将k-means得到的anchor k按面积从小到大啊排序
k = k[np.argsort(k.prod(1))]
# x: [N, 9] N个gt框与所有anchor框的宽比或高比(两者之中较小者)
# best: [N] N个gt框与所有anchor框中的最大 宽比或高比(两者之中较小者)
x, best = metric(k, wh0)
# (best > thr).float(): True=>1. False->0. .mean(): 求均值
# bpr(best possible recall): 最多能被召回(通过thr)的gt框数量 / 所有gt框数量 [1] 0.96223 小于0.98 才会用k-means计算anchor
# aat(anchors above threshold): [1] 3.54360 每个target平均有多少个anchors
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
f = anchor_fitness(k)
# print(f'{prefix}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr')
# print(f'{prefix}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, '
# f'past_thr={x[x > thr].mean():.3f}-mean: ', end='')
print(f"aat: {aat:.5f}, fitness: {f:.5f}, best possible recall: {bpr:.5f}")
for i, x in enumerate(k):
print('%i,%i' % (round(x[0]), round(x[1])), end=', ' if i < len(k) - 1 else '\n') # use in *.cfg
return k
# 载入数据集
if isinstance(path, str): # *.yaml file
with open(path) as f:
data_dict = yaml.safe_load(f) # model dict
from utils.datasets import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
else:
dataset = path # dataset
# 得到数据集中所有数据的wh
# 将数据集图片的最长边缩放到img_size, 较小边相应缩放
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
# 将原本数据集中gt boxes归一化的wh缩放到shapes尺度
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)])
# 统计gt boxes中宽或者高小于3个像素的个数, 目标太小 发出警告
i = (wh0 < 3.0).any(1).sum()
if i:
print(f'{prefix}WARNING: Extremely small objects found. {i} of {len(wh0)} labels are < 3 pixels in size.')
# 筛选出label大于2个像素的框拿来聚类,[...]内的相当于一个筛选器,为True的留下
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (np.random.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
# Kmeans聚类方法1: 使用欧式距离来进行聚类
print(f'{prefix}Running kmeans for {n} anchors on {len(wh)} gt boxes...')
# 计算宽和高的标准差->[w_std,h_std]
s = wh.std(0) # sigmas for whitening
# 开始聚类,仍然是聚成n类,返回聚类后的anchors k(这个anchor k是白化后数据的anchor框)
# 另外还要注意的是这里的kmeans使用欧式距离来计算的
# 运行k-means的次数为30次 obs: 传入的数据必须先白化处理 'whiten operation'
# 白化处理: 新数据的标准差=1 降低数据之间的相关度,不同数据所蕴含的信息之间的重复性就会降低,网络的训练效率就会提高
# 白化操作博客: https://blog.csdn.net/weixin_37872766/article/details/102957235
k, dist = kmeans(wh / s, n, iter=30) # points, mean distance
assert len(k) == n, print(f'{prefix}ERROR: scipy.cluster.vq.kmeans requested {n} points but returned only {len(k)}')
k *= s # k*s 得到原来数据(白化前)的anchor框
# Kmeans聚类方法2: 使用1-IOU来进行聚类
# k = k_means(wh, n)
wh = torch.tensor(wh, dtype=torch.float32) # filtered wh
wh0 = torch.tensor(wh0, dtype=torch.float32) # unfiltered wh0
# 输出新算的anchors k 相关的信息
k = print_results(k)
# Plot wh
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0], 400)
# ax[1].hist(wh[wh[:, 1]<100, 1], 400)
# fig.savefig('wh.png', dpi=200)
# Evolve 类似遗传/进化算法 (选择操作+变异操作)
npr = np.random # 随机工具
# f: fitness 0.62690
# sh: (9,2)
# mp: 突变比例mutation prob=0.9 s: sigma=0.1
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), desc=f'{prefix}Evolving anchors with Genetic Algorithm:') # progress bar
# 根据聚类出来的n个点采用遗传算法生成新的anchor
for _ in pbar:
# 重复1000次突变+选择 选择出1000次突变里的最佳anchor k和最佳适应度f
v = np.ones(sh) # v [9, 2] 全是1
while (v == 1).all():
# 产生变异规则 mutate until a change occurs (prevent duplicates)
# npr.random(sh) < mp: 让v以90%的比例进行变异 选到变异的就为1 没有选到变异的就为0
v = ((npr.random(sh) < mp) * npr.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
# 变异(改变这一时刻之前的最佳适应度对应的anchor k)
kg = (k.copy() * v).clip(min=2.0)
# 计算变异后的anchor kg的适应度
fg = anchor_fitness(kg)
# 如果变异后的anchor kg的适应度>最佳适应度k 就进行选择操作
if fg > f:
# 选择变异后的anchor kg为最佳的anchor k 变异后的适应度fg为最佳适应度f
f, k = fg, kg.copy()
# 打印信息
pbar.desc = f'{prefix}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k)
return print_results(k)
如下图当原始anchor bpr>0.98就不会再更新anchor:

但当原始anchor bpr<0.98就可以看到上面是通过k-means(欧式距离)聚类得到的anchors 下面是通过遗传算法得到的anchors:

总结
\qquad 这个文件主要就是 K-means_anchors 这个函数比较重要也比较难,涉及到一些机器学习的知识如:K-means、百化操作、遗传算法等需要补补课。先看我下面的Reference几篇文章和视频,再回过头来看这里的代码,加上我的注释,应该就不是很难了,有问题下面讨论区交流。
Reference
CSDN 霹雳吧啦Wz : 使用k-means聚类anchors.
Bilibili 霹雳吧啦Wz : 如何使用k-means聚类得到anchors以及需要注意的坑.
CSDN 恩泽君 : YOLOV3中k-means聚类获得anchor boxes过程详解.
Github 恩泽君: Laughing-q/yolov5_annotations.
CSDN 昌山小屋: 【玩转yolov5】请看代码之自动anchor计算.
CSDN TheOldManAndTheSea: 目标检测 YOLOv5 anchor设置
Bilibili 我家公子Q: 遗传算法超细致+透彻理解