е§дђЛЏ(Regularization)?ЪЧЛњЦїбЇЯАжаЖддЪМЫ№ЪЇКЏЪ§в§ШыЖюЭтаХЯЂ,вдБуЗРжЙЙ§ФтКЯКЭЬсИпФЃаЭЗКЛЏадФмЕФвЛРрЗНЗЈЕФЭГГЦЁЃвВОЭЪЧФПБъКЏЪ§БфГЩСЫдЪМЫ№ЪЇКЏЪ§+ЖюЭтЯю,ГЃгУЕФЖюЭтЯювЛАугаСНжж,гЂЮФГЦзї?1?norm?1?normКЭ?2?norm?2?norm,жаЮФГЦзїL1е§дђЛЏКЭL2е§дђЛЏ,ЛђепL1ЗЖЪ§КЭL2ЗЖЪ§(ЪЕМЪЪЧL2ЗЖЪ§ЕФЦНЗН)ЁЃ
- L2е§дђЛЏ,ФтКЯЙ§ГЬжаЭЈГЃЖМЧуЯђгкШУШЈжЕОЁПЩФмаЁ,зюКѓЙЙдьвЛИіЫљгаВЮЪ§ЖМБШНЯаЁЕФФЃаЭЁЃвђЮЊвЛАуШЯЮЊВЮЪ§жЕаЁЕФФЃаЭБШНЯМђЕЅ,ФмЪЪгІВЛЭЌЕФЪ§ОнМЏ,вВдквЛЖЈГЬЖШЩЯБмУтСЫЙ§ФтКЯЯжЯѓЁЃПЩвдЩшЯывЛЯТЖдгквЛИіЯпадЛиЙщЗНГЬ,ШєВЮЪ§КмДѓ,ФЧУДжЛвЊЪ§ОнЦЋвЦвЛЕуЕу,ОЭЛсЖдНсЙћдьГЩКмДѓЕФгАЯь;ЕЋШчЙћВЮЪ§зуЙЛаЁ,Ъ§ОнЦЋвЦЕУЖрвЛЕувВВЛЛсЖдНсЙћдьГЩЪВУДгАЯь,зЈвЕвЛЕуЕФЫЕЗЈЪЧПЙШХЖЏФмСІЧПЁЃ
- е§дђЛЏВЮЪ§ІЫдНДѓ,ІШjЫЅМѕЕУдНПь,зюКѓЧѓЕУДњМлКЏЪ§зюжЕЪБИїВЮЪ§вВЛсБфЕУКмаЁ,ЕБШЛвВВЛЪЧдНДѓдНКУ,ЬЋДѓШнвзв§Ц№ЧЗФтКЯЁЃ
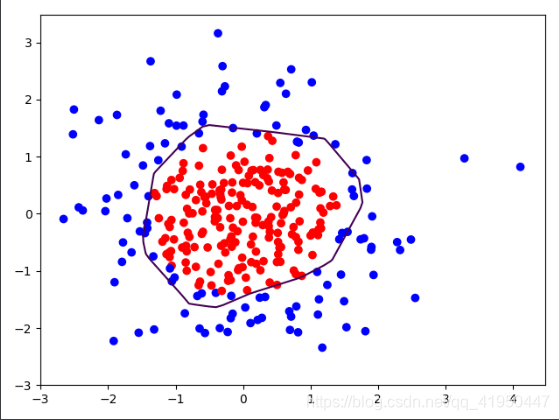
ЪЙгУТпМЛиЙщЕФР§згРДНтЪЭе§дђЛЏЮЪЬт,ИјЖЈвЛИіЪ§ОнМЏжагжx1,x2,yдкЩёОЭјТчжаНјаабЕСЗ,дйгУЭјИёжазјБъзїЮЊВтЪдМЏВтЪд,НЋдЪМЪ§Онx1,x2Нјаа0/1ЗжРр,вдЭМБэЯдЪО
вЛ.ЮДЪЙгУе§дђЛЏ
1.Y_c = [['red' if y else 'blue'] for y in y_train]
гУбеЩЋРДДњЬц0/1дЄВтжЕ [['red'], ['blue'], ['blue'], ['red'], ['red'], ['blue'],
2.h1 = tf.nn.relu(h1)
reluМЄЛюКЏЪ§
3.xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
xxдк-3ЕН3жЎМфвдВНГЄЮЊ0.01,yyдк-3ЕН3жЎМфвдВНГЄ0.01,ЩњГЩМфИєЪ§жЕЕу,зюжеxx,yyЮЊ60*60ЕФОиеѓ,np.mgridЗНЗЈЯъМћmgridгыmeshgridЩњГЩЪ§ОнЕФЧјБ№вдМАгыcontourЕШИпЯпЕФСЊЯЕ
4.xx.ravel(), yy.ravel()
ravel()ЗНЗЈЪЧНЋxx,yyОиеѓАДаагХЯШРЩьЮЊвЛЮЛЪ§зщ
5. np.c_[xx.ravel(), yy.ravel()]
np.c_ЪЧНЋОиеѓСаЪ§КЯВЂвЊЧѓааЪ§гыдОиеѓЯрЭЌ,np.rдђСаЪ§ЯрЭЌ,ШчЙћЪЧвЛЮЌЪ§зщЕФЛА,АДСНИіЪ§зщЕФЫїв§зщГЩзјБъЖдОиеѓ(shapeЮЊn*2)
6.color=np.squeeze(Y_c)
squeezeШЅЕєЮГЖШЪЧ1ЕФЮГЖШ,ЯрЕБгкШЅЕє[['red'],[''blue]],ФкВуРЈКХБфЮЊ['red','blue']ЁЃШчЙћУЛгаЮЌЖШЮЊ1ЕФЮЌЖШ,дђВЛЗЂЩњИФБфЁЃ
7.plt.scatter(x1, x2, color=np.squeeze(Y_c))
НЋдЪМЪ§Онx1,x2аЮГЩЩЂСаЕувдзјБъЭМЯёеЙЪО,ВЂБъЩЯжЎЧАдЄЩшКУЕФбеЩЋЁЃ
8.plt.contour(xx, yy, probs,levels=[.5])
ЛЗжНчЯп,Ъ§Онвд0/1ЗжРр,probsЮЊУПИізјБъЕуЕФдЄВтжЕ(0~1жЎМф),дђНЋдЄВтжЕЮЊ0.5ЕФзјБъЛЩЯЗжНчЯп,ДЫЯпвВОЭЪЧЗжРрЕуЕФЗжНчЯпЁЃ
ДњТыЧхЕЅ:
# Alleviate overfittingЛКНтЙ§ФтКЯ
# L2 е§дђЛЏЙЋЪНЗЧГЃМђЕЅ,жБНгдкдРДЕФЫ№ЪЇКЏЪ§ЛљДЁЩЯМгЩЯШЈжиВЮЪ§ЕФЦНЗНКЭ:е§дђЛЏЕФФПЕФЪЧЯожЦВЮЪ§Й§ЖрЛђепЙ§Дѓ,БмУтФЃаЭИќМгИДдг
# ЕМШыЫљашФЃПщ
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
# ЖСШыЪ§Он/БъЧЉ ЩњГЩx_train y_train
df = pd.read_csv('dot.csv')
#НЋЪ§ОнАДБъЧЉ зЊЛЛЮЊОиеѓx_data y_data
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df[['y_c']])
# print(x_data)
print(y_data)
#ЯТУцетвЛВНЦфЪЕЪЧУЛгаБивЊЕФ,ЩЯУцx_dataгыydataвбОЪЧОиеѓаЮЪНЕФСЫ,УЛБивЊдйЭЈЙ§reshapeзЊЮЊСНСавЛСаСЫ,ЩњГЩЕФЪ§ОнЦфЪЕЪЧЯрЭЌЕФ
# reshape(-1, 2)зЊЛЛЮЊСНСа,reshape(-1, 1)зЊЛЛЮЊвЛСа
#np.vstack(x_data)знЯђЖбЕўЪ§Он,аЮГЩОиеѓаЮЪН
x_train = np.vstack(x_data).reshape(-1, 2)
y_train = np.vstack(y_data).reshape(-1, 1)
print(x_train)
print(y_train)
# гУбеЩЋЧјЗж0./1.Ъ§Он
Y_c = [['red' if y else 'blue'] for y in y_train]
print(Y_c)
#гУбеЩЋРДДњЬц0/1дЄВтжЕ
#[['red'], ['blue'], ['blue'], ['red'], ['red'], ['blue'],
# зЊЛЛxЕФЪ§ОнРраЭ,ЗёдђКѓУцОиеѓЯрГЫЪБЛсвђЪ§ОнРраЭЮЪЬтБЈДэ
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)
# from_tensor_slicesКЏЪ§ЧаЗжДЋШыЕФеХСПЕФЕквЛИіЮЌЖШ,ЩњГЩЯргІЕФЪ§ОнМЏ,ЪЙЪфШыЬиеїКЭБъЧЉжЕвЛвЛЖдгІ
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
# ЩњГЩЩёОЭјТчЕФВЮЪ§,ЪфШыВуЮЊ2ИіЩёОдЊ,вўВиВуЮЊ11ИіЩёОдЊ,1ВувўВиВу,ЪфГіВуЮЊ1ИіЩёОдЊ
# гУtf.Variable()БЃжЄВЮЪ§ПЩбЕСЗ
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))
w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))
lr = 0.005 # бЇЯАТЪ
epoch = 800 # бЛЗТжЪ§
# бЕСЗВПЗж
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
with tf.GradientTape() as tape: # МЧТМЬнЖШаХЯЂ
# ЕквЛВувўВиВу
h1 = tf.matmul(x_train, w1) + b1 # МЧТМЩёОЭјТчГЫМгдЫЫу
# ШчЙћВЛгУМЄРјКЏЪ§(ЦфЪЕЯрЕБгкМЄРјКЏЪ§ЪЧf(x) = x),дкетжжЧщПіЯТФуУПвЛВуЪфГіЖМЪЧЩЯВуЪфШыЕФЯпадКЏЪ§,КмШнвзбщжЄ,ЮоТлФуЩёОЭјТчгаЖрЩйВу,ЪфГіЖМЪЧЪфШыЕФЯпадзщКЯЁЃ
# МЄЛюКЏЪ§ЪЧгУРДМгШыЗЧЯпадвђЫиЕФ,ЬсИпЩёОЭјТчЖдФЃаЭЕФБэДяФмСІ,НтОіЯпадФЃаЭЫљВЛФмНтОіЕФЮЪЬтЁЃ
h1 = tf.nn.relu(h1)#МЄЛюКЏЪ§
# ЪфШыМЄЛюКЏЪ§
y = tf.matmul(h1, w2) + b2
# ВЩгУОљЗНЮѓВюЫ№ЪЇКЏЪ§mse = mean(sum(y-out)^2)
loss = tf.reduce_mean(tf.square(y_train - y))
# МЦЫуlossЖдИїИіВЮЪ§ЕФЬнЖШ
variables = [w1, b1, w2, b2]
grads = tape.gradient(loss, variables)
# ЪЕЯжЬнЖШИќаТ
# w1 = w1 - lr * w1_grad tape.gradientЪЧздЖЏЧѓЕМНсЙћгы[w1, b1, w2, b2] Ыїв§ЮЊ0,1,2,3
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
# УП20Иіepoch,ДђгЁlossаХЯЂ
if epoch % 20 == 0:
print('epoch:', epoch, 'loss:', float(loss))
# дЄВтВПЗж
print("*******predict*******")
# xxдк-3ЕН3жЎМфвдВНГЄЮЊ0.01,yyдк-3ЕН3жЎМфвдВНГЄ0.01,ЩњГЩМфИєЪ§жЕЕу
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# НЋxx , yyРжБ,ВЂКЯВЂХфЖдЮЊЖўЮЌеХСП,ЩњГЩЖўЮЌзјБъЕу
#ravel()НЋЪ§зщЮЌЖШРГЩвЛЮЌЪ§зщ
#np.c_НЋОиеѓСаЪ§КЯВЂвЊЧѓааЪ§гыдОиеѓЯрЭЌ,np.rЯрЗД
#ШчЙћЪЧЪ§зщ,гУnp.c_ЪЧзщГЩзјБъЖд
#gridвВОЭДњБэЭјИёжаЫљгаЕФзјБъЕу,ЮЊСЫИјЯТУцЕФзјБъЕуИГжЕдЄВтжЕ,аЮГЩВтЪдМЏ
grid = np.c_[xx.ravel(), yy.ravel()]
print("xx.ravel()")
print(xx.ravel())
#ravel()НЋЪ§зщЮЌЖШРГЩвЛЮЌЪ§зщ
#[-3. -3. -3. ... 2.9 2.9 2.9]
print('=============================')
print(grid)
# print(grid)
# [[-3. -3. ]
# [-3. -2.9]
# [-3. -2.8]
# ...
# [ 2.9 2.7]
# [ 2.9 2.8]
# [ 2.9 2.9]]
grid = tf.cast(grid, tf.float32)
# НЋЭјИёзјБъЕуЮЙШыЩёОЭјТч,НјаадЄВт,probsЮЊЪфГі
probs = []
for x_test in grid:
print(x_test)
# ЪЙгУбЕСЗКУЕФВЮЪ§НјаадЄВт
h1 = tf.matmul([x_test], w1) + b1
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2 # yЮЊдЄВтНсЙћ
probs.append(y)
# ШЁЕк0СаИјx1,ШЁЕк1СаИјx2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probsЕФshapeЕїећГЩxxЕФбљзг
print("probs")
print(probs)#етРяДђгЁЕФЪЧУПвЛИіx_testЕФНсЙћ,x_testвЛЙВ3600Иі
probs = np.array(probs).reshape(xx.shape)#xx.shape 60*60
print(probs)
print(probs.shape)#60*60
#НЋдЪМЪ§ОнЖдЩњГЩЩЂСаЭМ
plt.scatter(x1, x2, color=np.squeeze(Y_c)) # squeezeШЅЕєЮГЖШЪЧ1ЕФЮГЖШ,ЯрЕБгкШЅЕє[['red'],[''blue]],ФкВуРЈКХБфЮЊ['red','blue']
#ЛГі0/1 red/blueЗжНчЯп
# АбзјБъxx yyКЭЖдгІЕФжЕprobsЗХШыcontourКЏЪ§,ИјprobsжЕЮЊ0.5ЕФЫљгаЕуЩЯЩЋ plt.show()Кѓ ЯдЪОЕФЪЧКьРЖЕуЕФЗжНчЯп
plt.contour(xx, yy, probs,levels=[.5])#ИјжЕЮЊ0.5ЕФЕШИпЯпЛЩЯЗжНчЯп
plt.show()
# ЖСШыКьРЖЕу,ЛГіЗжИюЯп,ВЛАќКЌе§дђЛЏ
# ВЛЧхГўЕФЪ§Он,НЈвщprintГіРДВщПД
?ЭЈЙ§ДЫНсЙћПЩвдПДГі,ЗжНчЯпКмЧњел,Й§ФтКЯ,УЛгаКмКУЕФФЃаЭЗКЛЏФмСІЁЃ
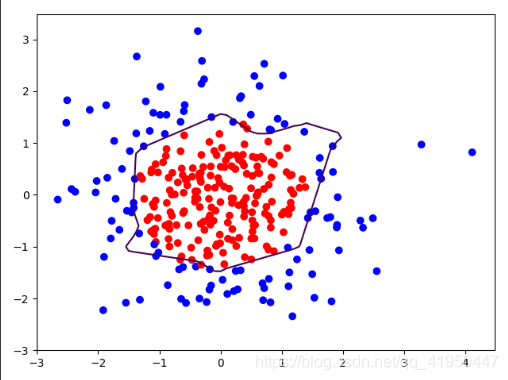
?Жў.ЪЙгУL2е§дђЛЏ
ЮЊw1,w2ЬэМгСЫL2е§дђЛЏ
loss_regularization = []
# tf.nn.l2_loss(w)=sum(w ** 2) / 2
#МђЕЅЕФПЩвдРэНтГЩеХСПжаЕФУПвЛИідЊЫиНјааЦНЗН,ШЛКѓЧѓКЭ,зюКѓГЫвЛИі1/2
loss_regularization.append(tf.nn.l2_loss(w1))
loss_regularization.append(tf.nn.l2_loss(w2))
# ЧѓКЭ
# Р§:x=tf.constant(([1,1,1],[1,1,1]))
# tf.reduce_sum(x)
# >>>6
loss_regularization = tf.reduce_sum(loss_regularization)
#е§дђЛЏВЮЪ§ЮЊ0.03
loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03ДњТыЧхЕЅ:
# ЕМШыЫљашФЃПщ
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
# ЖСШыЪ§Он/БъЧЉ ЩњГЩx_train y_train
df = pd.read_csv('dot.csv')
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])
x_train = x_data
y_train = y_data.reshape(-1, 1)
Y_c = [['red' if y else 'blue'] for y in y_train]
# зЊЛЛxЕФЪ§ОнРраЭ,ЗёдђКѓУцОиеѓЯрГЫЪБЛсвђЪ§ОнРраЭЮЪЬтБЈДэ
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)
# from_tensor_slicesКЏЪ§ЧаЗжДЋШыЕФеХСПЕФЕквЛИіЮЌЖШ,ЩњГЩЯргІЕФЪ§ОнМЏ,ЪЙЪфШыЬиеїКЭБъЧЉжЕвЛвЛЖдгІ
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
# ЩњГЩЩёОЭјТчЕФВЮЪ§,ЪфШыВуЮЊ2ИіЩёОдЊ,вўВиВуЮЊ11ИіЩёОдЊ,1ВувўВиВу,ЪфГіВуЮЊ1ИіЩёОдЊ
# гУtf.Variable()БЃжЄВЮЪ§ПЩбЕСЗ
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))
w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))
lr = 0.005 # бЇЯАТЪЮЊ
epoch = 800 # бЛЗТжЪ§
# бЕСЗВПЗж
for epoch in range(epoch):
for step, (x_train, y_train) in enumerate(train_db):
with tf.GradientTape() as tape: # МЧТМЬнЖШаХЯЂ
h1 = tf.matmul(x_train, w1) + b1 # МЧТМЩёОЭјТчГЫМгдЫЫу
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2
# ВЩгУОљЗНЮѓВюЫ№ЪЇКЏЪ§mse = mean(sum(y-out)^2)
loss_mse = tf.reduce_mean(tf.square(y_train - y))
# ЬэМгl2е§дђЛЏ
loss_regularization = []
# tf.nn.l2_loss(w)=sum(w ** 2) / 2
#МђЕЅЕФПЩвдРэНтГЩеХСПжаЕФУПвЛИідЊЫиНјааЦНЗН,ШЛКѓЧѓКЭ,зюКѓГЫвЛИі1/2
loss_regularization.append(tf.nn.l2_loss(w1))
loss_regularization.append(tf.nn.l2_loss(w2))
# ЧѓКЭ
# Р§:x=tf.constant(([1,1,1],[1,1,1]))
# tf.reduce_sum(x)
# >>>6
loss_regularization = tf.reduce_sum(loss_regularization)
#е§дђЛЏВЮЪ§ЮЊ0.03
loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03
# МЦЫуlossЖдИїИіВЮЪ§ЕФЬнЖШ
variables = [w1, b1, w2, b2]
grads = tape.gradient(loss, variables)
# ЪЕЯжЬнЖШИќаТ
# w1 = w1 - lr * w1_grad
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
# УП200Иіepoch,ДђгЁlossаХЯЂ
if epoch % 20 == 0:
print('epoch:', epoch, 'loss:', float(loss))
# дЄВтВПЗж
print("*******predict*******")
# xxдк-3ЕН3жЎМфвдВНГЄЮЊ0.01,yyдк-3ЕН3жЎМфвдВНГЄ0.01,ЩњГЩМфИєЪ§жЕЕу
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# НЋxx, yyРжБ,ВЂКЯВЂХфЖдЮЊЖўЮЌеХСП,ЩњГЩЖўЮЌзјБъЕу
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# НЋЭјИёзјБъЕуЮЙШыЩёОЭјТч,НјаадЄВт,probsЮЊЪфГі
probs = []
for x_predict in grid:
# ЪЙгУбЕСЗКУЕФВЮЪ§НјаадЄВт
h1 = tf.matmul([x_predict], w1) + b1
h1 = tf.nn.relu(h1)
y = tf.matmul(h1, w2) + b2 # yЮЊдЄВтНсЙћ
probs.append(y)
# ШЁЕк0СаИјx1,ШЁЕк1СаИјx2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probsЕФshapeЕїећГЩxxЕФбљзг
probs = np.array(probs).reshape(xx.shape)
plt.scatter(x1, x2, color=np.squeeze(Y_c))
# АбзјБъxx yyКЭЖдгІЕФжЕprobsЗХШыcontourКЏЪ§,ИјprobsжЕЮЊ0.5ЕФЫљгаЕуЩЯЩЋ plt.show()Кѓ ЯдЪОЕФЪЧКьРЖЕуЕФЗжНчЯп
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
# ЖСШыКьРЖЕу,ЛГіЗжИюЯп,АќКЌе§дђЛЏ
# ВЛЧхГўЕФЪ§Он,НЈвщprintГіРДВщПД
?ЭЈЙ§ДЫЭМРДПД,ЬэМгСЫе§дђЛЏЕФФЃаЭЯрБШНЯЮДе§дђЛЏЕФЭМЯёРДЫЕ,ДЫЭМЗжНчЯпБШНЯдВЛЌ,гжНЯЧПЕФФЃаЭЗКЛЏФмСІЁЃ