���ò�����Ӣΰ�����ܸ����Ǿ�ϲ,������Ϊһ�����ѧϰ��ҵ���Լ���Ϸ������,����������AI��GPU�����м�����ص�����һֱ���DZȽϸ���Ȥ����Ϊ���ѧϰ��һ��Ӳ��ƽ̨��Ӣΰ��,������Ȼ��Ϥ�IJ�������Ϥ�ˡ�

Ӣΰ���Ӳ���㹻����,��Ҳ��Ҫ�㹻������������ȥ֧�Ų������������䷢չ����,�Դ�Ӣΰ���ǡ����ĵġ�����Ϊ�Ͼ�ֻ�д�Ҷ��á���Ҷ����ź��á���Ҳ���ź���,��Ż���Ӣΰ��IJ�Ʒ,�Ż�������GPUȥ��һЩ�����Ȥ������(��ȻӢΰ��Ϳ�����Ǯ��)��
��Ҳ������̬��
��ʵ���˱Ƚϳ�ʱ��Ӣΰ��IJ�Ʒ(�Կ���Ƕ��ʽ�汾ϵ��),NVIDIA������ЩӲ����Ʒ������֧�ֻ��Ǻ��Ѻúܿ��ŵġ�
����ƽ�����õ�TensorRT,���и��ֹ��߰�����DeepDream��TLT(TRANSFER LEARNING TOOLKIT)��Triton-Server-Inference�ȶ���Ӣΰ���ṩ�����ǿ��伴�õĹ���,Ҳȷʵ���á�Ψһ���²۵ľ��ǿ�Դ������(��������~)��
����Ҳ�Ƽ�����NVIDIA�����о�(����Դ�Լ��Կ�Դ)����Ŀ��ַ,�dz��ʺ������:
- https://www.nvidia.com/en-us/on-demand/
- https://www.nvidia.com/en-us/research/ai-playground/
- https://developer.nvidia.com/transfer-learning-toolkit
Ӣΰ��֮����Ҫ��
NVIDIA�кܶ��µļ�����������Դ�ļ���(δ���İ�����)���ֶ���������չʾ����,����On-Demand��Ϊɶ��ON-DEMAND?����һ��Ӣ���ֵ�,�����ǡ�������ȡ������������Ϊ,Ҳ��������Ҫ���߸���Ȥ�ļ���,��Ŷ���������!
����û�¾�����һ����һ��,������Ҫʵʱ�����������ѧϰ���𡢼��١����¼�����С���,���Ǹ��ܺõ�ѧϰ�ض���ON-DEMAND���ݽ��γ̴�ŷ�Ϊ�����⼸��:
- �Զ���ʻ��������
- �����ݡ����硢���ӻ�
- ���ݿ�ѧ
- ���ѧϰ
- GPU���
- ͼ��ͼ���Լ����
- �����ܼ���
- ���桢˼ά
�������о��ĵ�Ȼ�����ѧϰ��AI���������������,�����������ռ�������������(TensorRT��ONNXRUNTIME��ϡ�軯��������Polygraphy)NVIDIA�Ļ�ݽ�PPT,�Լ��Ľ���,ÿ���ݽ�����PPT����Ƶ���Կ�,��Դ���DZȽϷḻ�ˡ�
���еIJ��ּ�������֮ǰҲ�ᵽ����
˵����ô��,��ʵ���ĵ�Ŀ���ǽ���һЩNVIDIA�������һЩ�µļ�����,����һЩ������֪ʶ����,���˾��ź�ʵ�ú����ջ�,�����������ҡ�
����ÿһ��������Ӧ�ſγ̵���Ŀ,��ON-DEMAND�ж������ҵ�,����Ӧ��PPT�Լ���Ƶ�ݽ���PPT���Ե�������,���뵥�����ص�(��Ҫ�˻�),����Ҳ������������ĩ��
TensorRT Quick Start Guide
We��ll walk you through the TensorRT Quick Start Guide. The newly-published TensorRT Quick Start Guide provides a quick introduction to new users starting out with TensorRT. It includes Jupyter notebooks and C++ examples of the most common TensorRT workflows and examples for using TensorRT with TensorFlow, PyTorch, and ONNX.
�ٷ��Ƴ���TensorRT����ָ��,��Ȩ��Ҳ��ֱ�ӡ�����notebook��ʹ���Լ�C++�ķḻ����,�ṩ��Pytorch��TensorFlow�Լ�ONNXһ��������,���������ٺ��ʲ����ˡ�
��������Ҳд�˹���TensorRT�����Ž���,���뿴Ӣ�İ�Ŀ��Կ������:�ھ���ɶ�˻���֪��TensorRT?����ϸ����ָ��,��������!
TensorRT�ĸ��»���ͦ���,������дTensorRT-7.2.3.4��ʱ��,TensorRT�Ѿ����ij���8��EA�档��������֮ǰ�ᵽ��,�ǻ��������TensorRT-EA��,���˰���¾�����GA��,��������!�����Ѿ���TensorRT-8GA�汾,���������ܻ���������,�����һ���汾������������
��������Щ����,���ʹ����ο�����Щ�¹���,Ӣΰ���Լҵ�Ȼ��Ҫ����һ���ġ�
������ǡ�
Accelerate Deep Learning Inference with TensorRT 8.0
TensorRT is an SDK for high-performance deep learning inference used in production to minimize latency and maximize throughput. The upcoming TensorRT 8.0 release provides features such as sparsity optimized for NVIDIA Ampere GPUs, quantization-aware training, and enhanced compiler to accelerate transformer-based networks. Deep learning compilers need to have a robust method to import, optimize, and deploy models. New users can learn about the common workflow, while experienced users can learn more about new TensorRT 8.0 features.
TensorRT8�����Ƿ�����,Ӣΰ��ٷ�Ҳ����������һ��,�����в���,Ҳ��PPT�Լ���Ӧ�Ŀγ�˵����
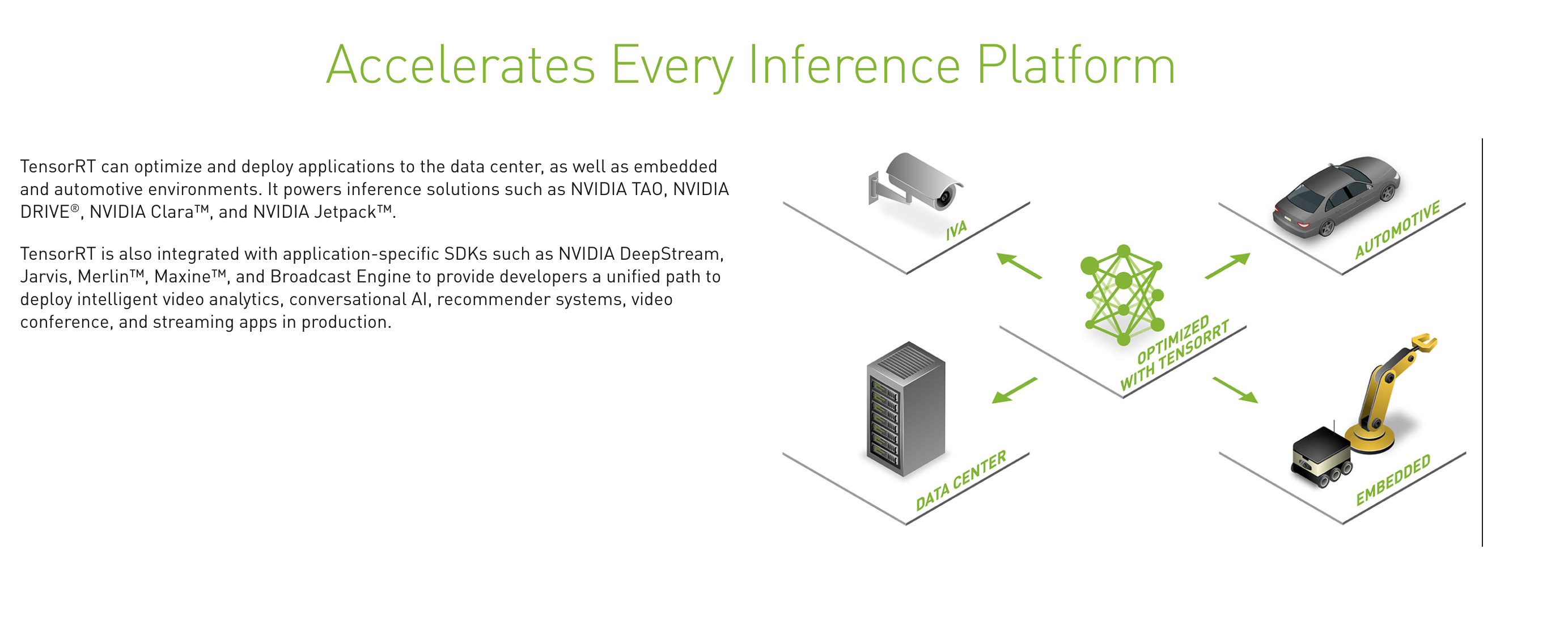
Ŀǰ��GA�汾,TensorRT-8.0.1.6�档8�汾���7�汾,�ش�ı仯������:
- ֧��QTA����(Ҳ����ѵ��������),����ֱ�ӽ����������ѵ����������ģ�͵��뵽TensorRT��ʹ��
- ���ڰ���(Ampere��)�ܹ����Կ�,֧��ϡ�軯����,������50%��������
- ����BERT��transformer���ܵ��������˸��õ��Ż�
TensorRT8�ı䶯���������,�Ͼ��Ǵ�汾�ĸ��¡���ϸ�����ݿ����ȿ�����ݽ�PPT������֮��Ҳ����ϸ������(�������)��
Introduction to TensorRT and Triton: A Walkthrough of Optimizing Your First Deep Learning Inference Model
NVIDIA TensorRT is a deep learning platform that optimizes neural network models and speeds up inference across GPU-accelerated platforms running in the data center and embedded devices. We��ll provide an overview of TensorRT, show how to optimize a PyTorch model, and demonstrate how to deploy this highly optimized model using NVIDIA Triton Inference Server. By the end of this workshop, developers will see the substantial benefits of integrating TensorRT and get started on optimizing their own deep learning models.
���˵TensorRT��������������,��ôTriton����ͬ������ķ�������ܡ�
����һ��TensorRT!����һ��Triton!��ô��������?����triton with TensorRT!���߽���������Գ�֮Ϊ��Դ����ǿ����������������
Tritonȷʵ�Ǻ��õIJ��С�Triton server�������������������������,��֧�ֵĵײ�backend��TensorRT��onnxruntime��libtorch��TensorFlow��Pytorch��Openvino��,֧��http��grpcЭ��,Ҳ�����Զ���Э��(�Ͼ���Դ��),֧�ֶ,֧�ֶ�ʵ��,֧���ȼ��ء�
����һ����Ҫ���ص�,�����֮ǰ���Ʒ�����TensorFlow-Server�Ѿ�����ȫ����������:

triton���°�21.06������:

�Ͼ�Triton-server��NVIDIA�Լҵ�,����TensorRT������֧�������������Ч��,���TensorRTģ����Ҫ������,��ôtriton-server�ǵ�һѡ��
����triton������Ҳ�ر��,ֻҪ��Ϥ����һ��,֮��ģ�Ͳ��������ر��:

��֮triton��һ������Ŀ�Դ������,TensorRT�ķ����������һѡ�������,��Ȼ�������Ҳ����ʹ�á�
����triton,����֮��Ҳ����ϸ����һ�¡�
Quantization Aware Training in PyTorch with TensorRT 8.0
Quantization is used to improve latency and resource requirements of Deep Neural Networks during inference. Quantization Aware Training (QAT) improves accuracy of quantized networks by emulating quantization errors in the forward and backward passes during training. TensorRT 8.0 brings improved support for QAT with PyTorch, in conjunction with NVIDIA��s open-source pytorch-quantization toolkit. This session gives an overview of the improvements in QAT with TensorRT 8.0, and walks through an end-to-end usage example.
ѵ��������(QTA)��TensorRT8�е�һ��������,���֮ǰTensorRT7�ṩ��ѵ��������(PTQ,Ҳ����ͨ���������ݼ�У����������),ѵ�����������Ը��õ�Ѱ�������߶���Ϣ��
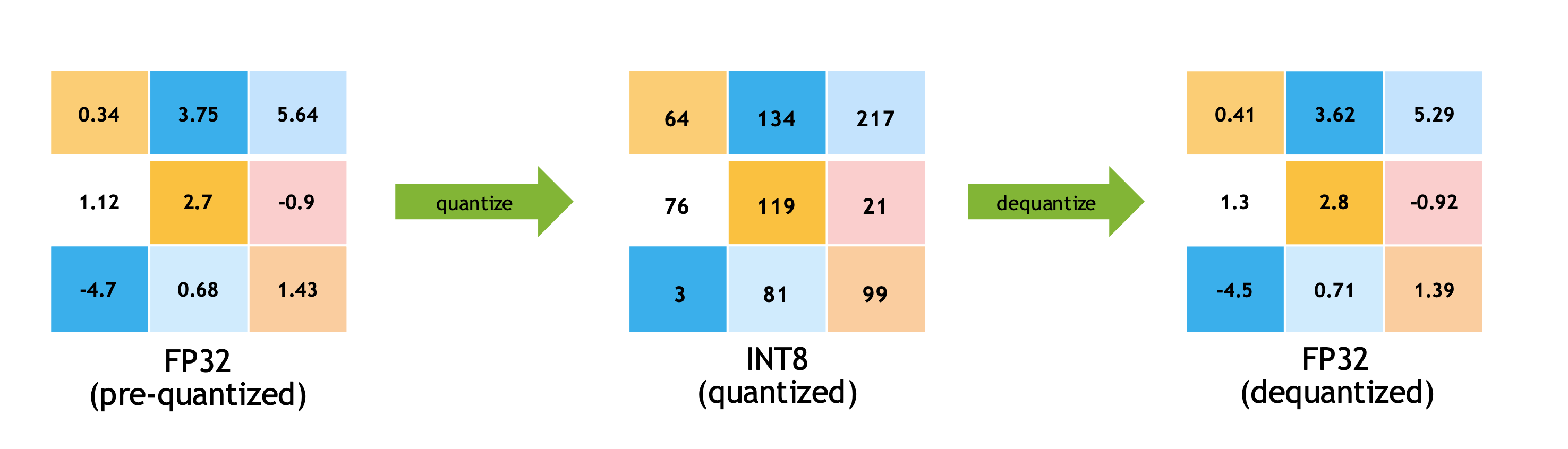
��ͼ���ǿ���֪��,����һ����������,���������FP32��������ΪINT8,����ٽ��з�������INT8�������ڱ�ΪFP32��ʵ��������ѵ��ʹ�õľ��Ȼ���FP32,ֻ�����������������ѵ���п���ѧϰ�������ͷ������ij߶���Ϣ,���ֱ��ѵ����У,���ֵ�ҵĸ�һЩ��
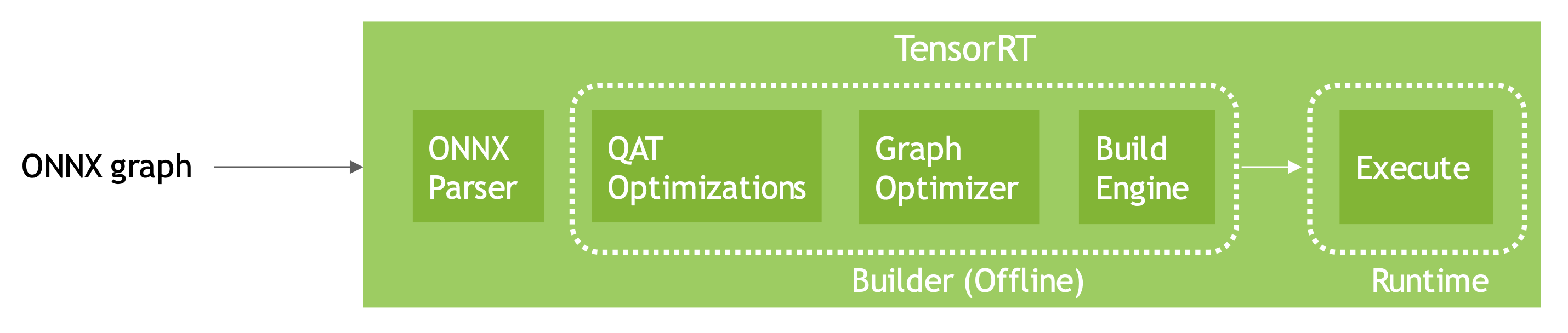
TensorRT8����ֱ�Ӽ���ͨ��QTA�������ҵ���ΪONNX��ģ��,�ٷ�Ҳ�ṩ��Pytorch����������,��ν��һ����λ��
���������ϸ�ڿ��Կ�����γ�,����֮��Ҳ��дһƪ����������,�������~
Making the Most of Structured Sparsity in the NVIDIA Ampere Architecture
In this session, we��ll share details of Sparse Tensor Cores in the NVIDIA Ampere Architecture and the unique 2:4 sparse format they support. Learn how we��ve simplified maintaining accuracy when pruning all types of networks, including classification networks, language models, and GANs. Finally, find out how to accelerate your own workloads using Sparse Tensor Cores from start to finish with ASP and TensorRT 8.0 and cuSPARSELt.
ϡ�軯�����ڼ�֦������,��һ������������,���Լ���ģ�͵IJ���,��ʱ��Ҳ��������ģ�͵������ٶȡ�ֻ����ϡ�軯����TensorRT�ڲ��������ʧ��,������Tensorֵ��Ϊ0,����ڼ�֦,��Ҫ�����Ӳ���ſ��Լ��١�
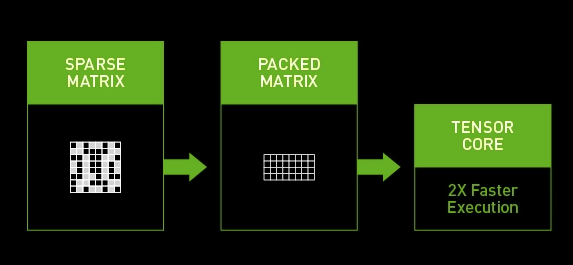
ϡ�軯��������ں���֮ǰ�ͳ�����,��CUDA��ϡ�軯��֧����ǰ���������
Ӣΰ�ﲿ���Կ���֧��ϡ�軯������,Ӣΰ���A100 GPU�Կ�������bert��ʱ��,ϡ�軯����������֮ǰ��dense����Ҫ��50%�����ǵ��Կ�֧��ô?ֻҪ��Ampere architecture�ܹ����Կ�����֧�ֵ�(����30XX�Կ�)��
����30ϵ���Կ���ʵ�ʼ�����,���Խ�������ǰϡ���˵ľ�����Compressed,���ѹ����ľ����Լ�������,�漴����ͨ��Ӳ��������һ�����㡣��Ϊ����������,�����ٶ����֮ǰ�϶��ǿ��˲��١�
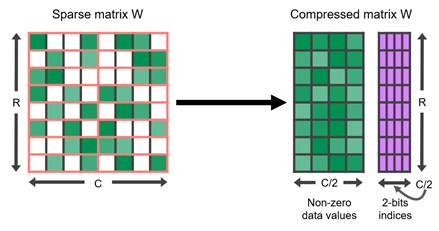
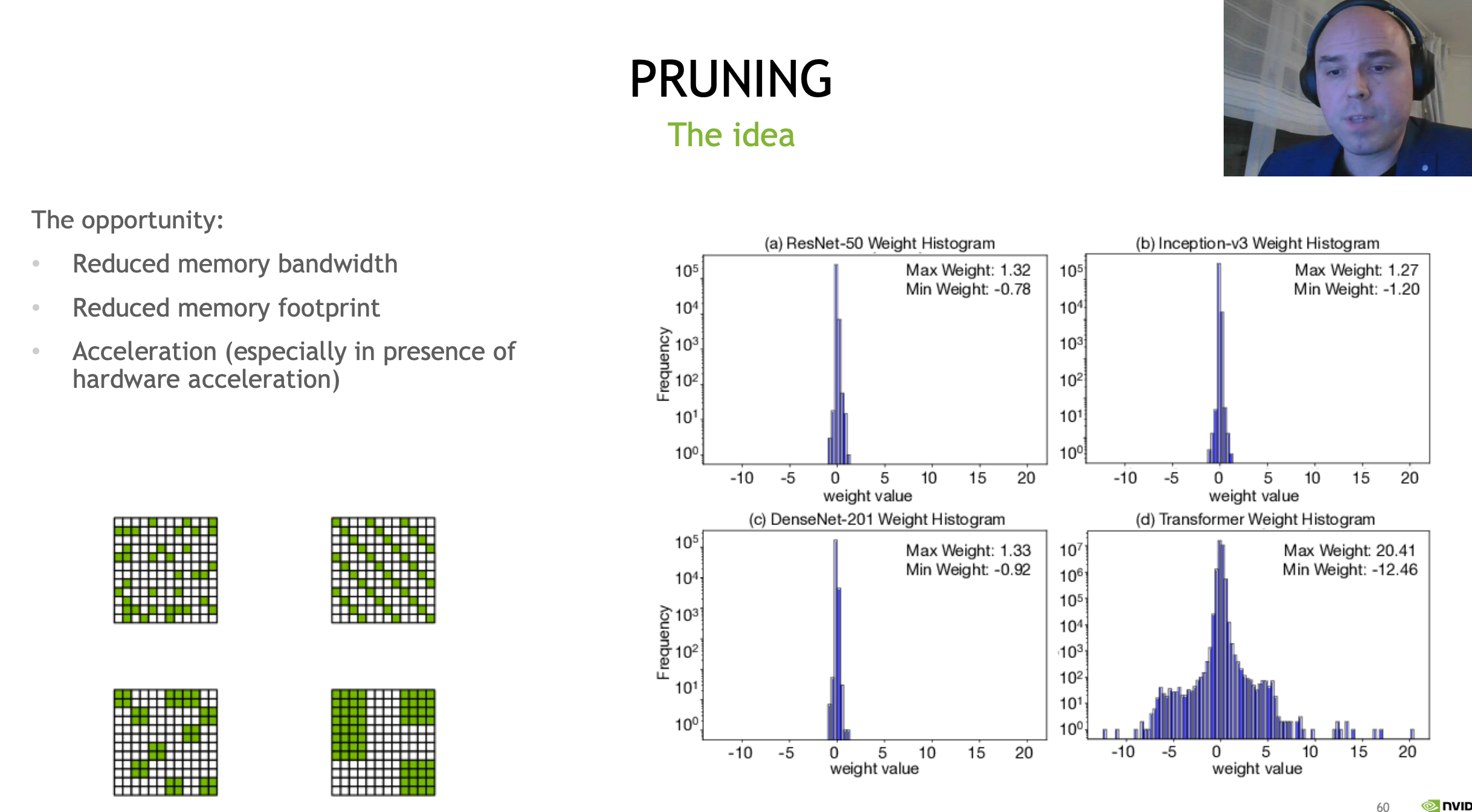
���� NVIDIA ����ṹ�� NVIDIA TensorRT ����ϡ������
Prototyping and Debugging Deep Learning Inference Models Using TensorRT��s ONNX-Graphsurgeon and Polygraphy Tools
Deep learning researchers and engineers usually have to spend a significant amount of time debugging accuracy and performance of their deep learning inference models before deploying them. TensorRT recently open-sourced some more tools to assist with the development and debugging of deep neural networks for inference. ONNX GraphSurgeon is a tool that allows you to easily generate new ONNX graphs, or modify existing ones. This can be useful in scenarios like using custom implementations for parts of the ONNX graph, in place of those provided by TensorRT. Polygraphy is a toolkit designed to assist in running and debugging deep learning models in various frameworks. It includes a Python API and several command-line tools built using this API. These tools allow displaying information about models, such as network structure; determining which layers of a TensorRT network need to be run in a higher precision for accuracy; and comparing inference results across frameworks, among other features.
Polygraphy��һ���dz�ǿ��Ĺ��ߡ�ǿ���Ƽ�,������߿��ܻ��ڹ�����ʡ����һ��debug��ʱ�䡣Ŀǰ����������ߵ��ƹ�ͽ��ܲ����Ǻܶ�,�ܶ��˻���֪����
������������ܸ�ɶ:

���Կ�ONNX��TRT������ṹ,�����ġ���ONNXģ��,���Բ���debugת���õ�trtģ����ʲô���⡭��֮,�������trt��ONNX���ض�ʹ����,�������ǧ���ܴ���������������ҵ��,������ߵ�˼��Ҳ��ֵ�ý��!
���������~
- �鿴ONNX�ṹ polygraphy inspect model mymodel.onnx
- �鿴һ��engine�ṹ polygraphy inspect model mytrt.trt --model-type engine
- ͨ��onnx�鿴����trt������� polygraphy inspect model mymodel.onnx --display-as=trt --mode basic
- ����trt��onnx�Ľ��
��������onnx�Ľ����Ϣ
polygraphy run mymodel.onnx --onnxrt --save-outputs onnx_res.json
Ȼ��תһ��ģ�ͽ��жԱ�
polygraphy run mytrt.trt --model-type engine --trt --load-outputs onnx_res.json --abs 1e-4 - ��onnx�ṹ
polygraphy surgeon sanitize modele2-nms.onnx
�Coverride-input-shapes input_name:[1,3,224,224]
-o modele2-nms-static-shape.onnx
����Ľ����뿴PPT���ߵȴ����˵Ľ�����~
Achieve Best Inference Performance on NVIDIA GPUs by Combining TensorRT with TVM Compilation Using SageMaker Neo
Amazon SageMaker Neo allows customers to compile models from any framework for optimized inference on many compilation targets, including NVIDIA Jetson devices and T4 GPU instances. We��ll dive into the details of how Neo uses the open-source deep learning compiler TVM and NVIDIA TensorRT together to provide the best inference performance across popular deep learning model types.
TVM��TensorRT�Ľ��,����ͻ��к�ǿ��TVM��TensorRT��Ϊҵ����һ�����ļ����������,���߽����������ʲô���Ļ���?
TVM����֮ǰ�ᵽ��,������������ѧϰ��������TensorRT������˵�������߽�Ϻ��������е�һ��,��������integration����Partitioning�ķ�ʽ�����ּ���ͼ������TVM������������TensorRT��,����ȡ������

����Ҳ��Ҫ��̫��,�Ͼ�����ܷ�����ʵȴ�ܹǸС���������Ҳ��һЩcaseʹ�ù����ߵĽ��(�Ƚϸ��ӵ�ģ��),�����ò��ˡ�TensorRT�Ż������op��֧�ֵ�TVMҲ��֧��,��Ҳû��ʱ��ȥ�о��Լ�д,ֻ�ܳ������������ˡ�
����Ҳ���ܾ���,�Ͼ�ÿ���˵�ģ�Ͳ�һ��,���������������и���op,TensorRT��֧�ֻ���TVM��֧�ֵ����,�����ȳ��Կ�����
New Features in TRTorch, a PyTorch/TorchScript Compiler Targeting NVIDIA GPUs Using TensorRT
We��ll cover new features of TRTorch, a compiler for PyTorch and TorchScript that optimizes deep learning models for inference on NVIDIA GPUs. Programs are internally optimized using TensorRT but maintain full compatibility with standard PyTorch or TorchScript code. This allows users to continue to feel like they��re writing PyTorch code in their inference applications while fully leveraging TensorRT. We��ll discuss new capabilities enabled in recent releases of TRTorch, including direct integration into PyTorch and post-training quantization.
TRTorch,�տ�ʼ����������ָо�����֡�������ϸ�˽�����,���������ض������DZȽ�ʵ�õ�,תTRT�����̱�Ϊ:
- Pytorch->torchscript->tensorrt
�����ֶ���һ��·��תPytorchģ�͵�TRT��!
��֮ǰ�ù�torch2trt���������ת��pytorchģ�͵�trt,��ôTRTORCH������˵��ʲô��ô?��֮����pytorch->trt,Ϊʲô��ֱ����torch2trt��?��Ҫ��ô����ͨ��һ��torchscript?
��ʵTRTorch���ʺ�һ�ֳ���,�Ǿ���pytorch��һЩop,TensorRT��֧��,���ֲ����ƹ�ȥ���������ǾͿ�����TRTorch�������и���ͼ,ʹ����ͼһ����������TensorRT�ж���һ����������libtorch�С�
�Dz��Ǻ�����һ��TVM+TensorRT�Ĺ���,������Щ�����ܶ����Ǻܳ���,�ܶ�bug,Ŀǰ���������Ǻܺ��á�

Low-Latency, High-Throughput Inferencing for Transformer-Based Models
Transformer-based models provide state-of-the-art accuracy for many NLP tasks. Recent models contain a large number of parameters, which makes meeting low latency requirements challenging for online inferencing. We��ll cover highly optimized inferencing solutions for transformer-based models to tackle online and offline inferencing scenarios. We��ll demonstrate that low latency and high throughput can be achieved with the combination of NVIDIA hardware and software. We��ll briefly go over BERT inferencing with FasterTransformer, TensorRT, and MXNet, and also present performance data from the latest NVIDIA GPUs.
TransformerҲ���ö�˵,ĿǰΪֹ����õ�encoder��decoder�����塣����transformer��ģ��Ҳ�кܶ�,BERT�����������һ��,������NLP,������������,ֻҪ�漰������߽���IJ��ֶ���������ʹ��transformer����ģ�;��ȡ���Ȼtransformer�ٶȿ쾫�ȸ߷���GPU�ļ�������,Ψһ����ľ����ٶ���ȴ����������Ǻܿ졣
TensorRT8���Transformer�ṹ�����˸���ȵ��Ż�,ֵ������:
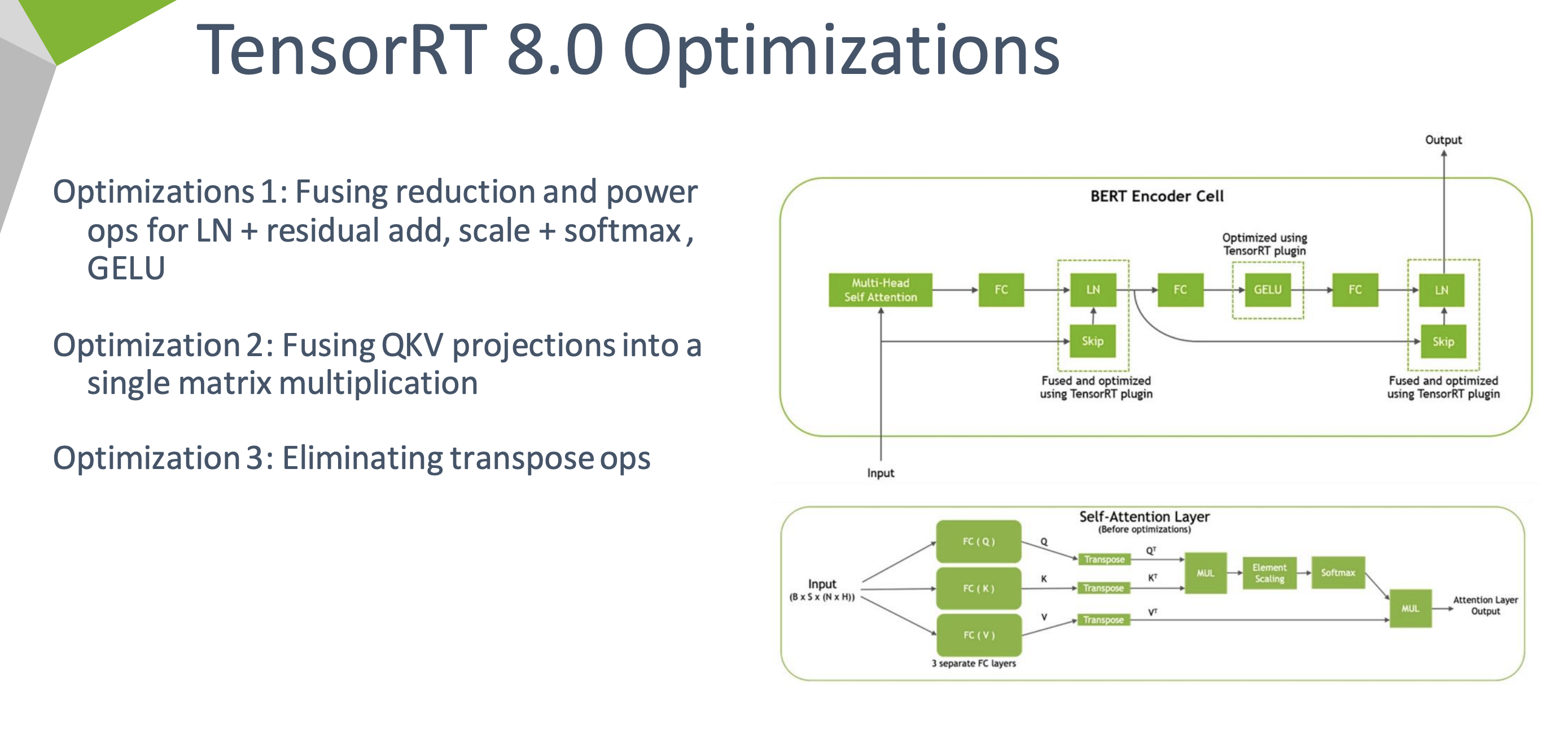
TensorRT����Transformer�Ŀ�Դ��Ŀ����:
- https://github.com/NVIDIA/FasterTransformer
- https://github.com/NVIDIA/TensorRT/tree/master/demo/BERT
Inference with Tensorflow 2 Integrated with TensorRT Session
Learn how to inference using Tensorflow 2 with TensorRT integrated and the performance this can offer. Tensorflow is a machine learning platform and TensorRT is an SDK for high-performance deep learning inference using NVIDIA GPUs. Tensorflow models are usually written in FP32 precision to work for both training and inference. Tensorflow-TensorRT integration automatically offloads portions of the Tensorflow graph to run with TensorRT using precisions FP16 or INT8 to improve inference throughput without sacrificing much accuracy. We��ll describe: how to use Tensorflow-TensorRT integration in Tensorflow 2; the dynamic shape feature we recently added to better handle Tensorflow graph with unknown shapes; the lazy calibration mode we recently added to improve the workflow for inferencing with INT8 precision; some details on how Tensorflow-TensorRT works; and the performance benefits of using Tensorflow-TensorRT for inference.
TensorFlow2���˲��Ǻ���Ϥ,����Ҳ�Ͳ���˵�ˡ���������ʹ��TensorFlow2��ͯЬ����˵,ʹ��TRT���ٸ��ӷ�����,������ϸ�����ݿ��Կ�PPT��
Designing and Optimizing Deep Neural Networks for High-Throughput and Low-Latency Production Deployment
When integrating DNNs into applications the project teams need to consider much more than just model accuracy. Factors such as throughput affect the size and the cost of the infrastructure required to host the application. Similarly, latency of model response is important for a wide range of time-sensitive application and a hard requirement when building safety-critical applications. We��ll discuss how to select efficient models that allow us to meet the throughput and latency requirements (including multitask DNNs) as well as key approaches for their further optimization, such as quantification-aware training, post-training quantification, pruning, distillation, and other forms of model compression. We��ll explain how those techniques interact with the GPU architecture. Finally, we��ll reprise key tools that can simplify the model optimization and deployment process, such as TensorRT or Triton Inference Server.
�����Ʋ����Ż������µ��ӳٵIJ�Ʒģ��,�漰����TensorRT�Լ�Triton Inference Server��
���ڵ�ģ��Խ��Խ����,û�취��Ҫ�߾���,�����ϴ�ģ�͡�
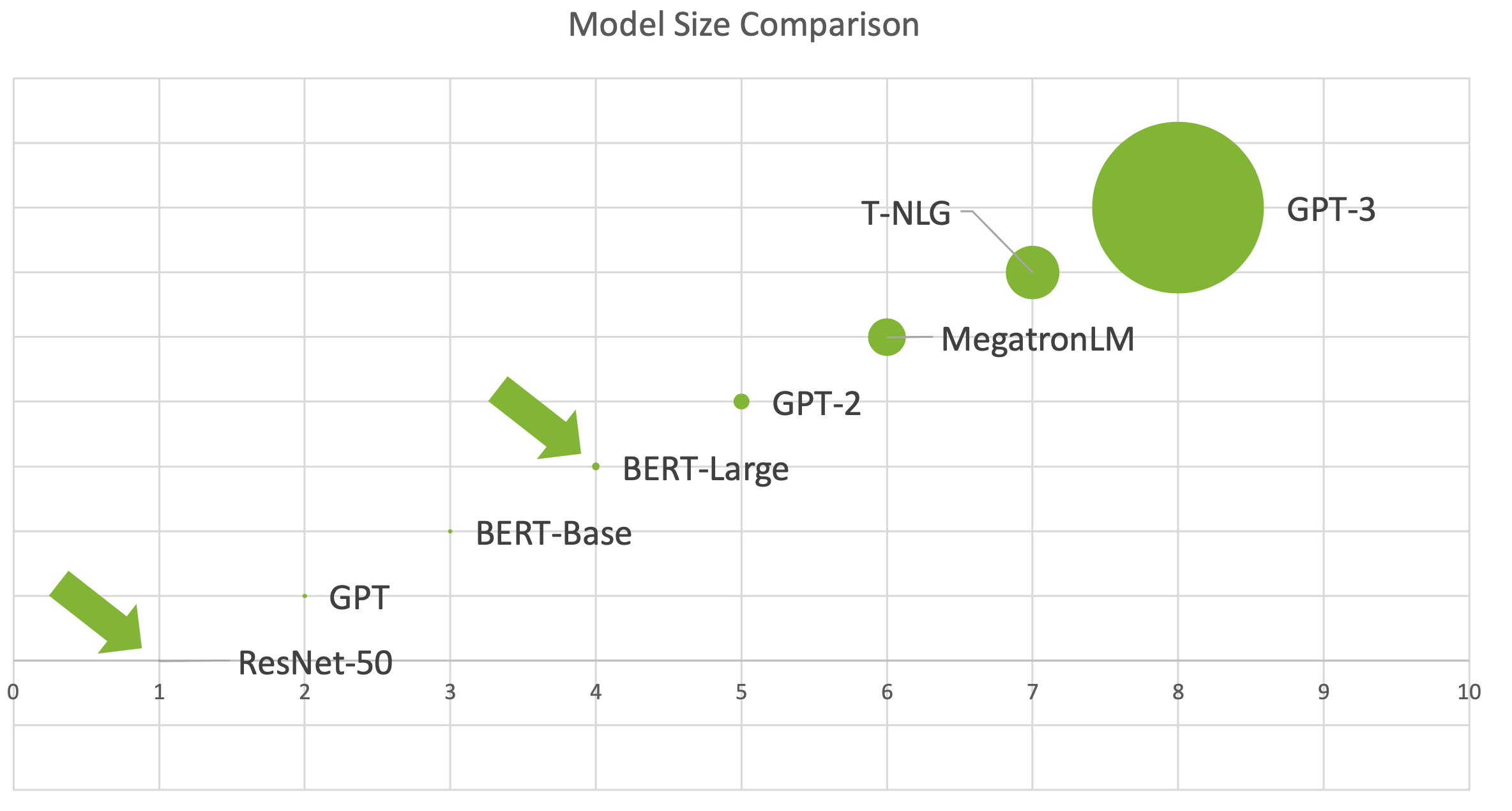
���Ǵ�ģ�͵��ӳ��ֺܸ�,���ѡ�����ŵķ�����������?�����ᵽ������Ҫ��:
����γ����������ݺ�AI��ҵ�����ν���������,�漰���ܶ�֮ǰ��֪ʶ��(������ϡ�軯��TensorRT��triton�ȼ���),����һƪ���ӻ�ɡ������˺ܶ�Ŀǰ��ǰ�ص�AI������,���Ǻ���ϸ,����������֪ʶ�㶼�г����ˡ�
��ʵ��֪ʶ��ǰ��Ŀγ̶��н��ܵ�,�о�Ӣΰ���Ѿ����Լҹ��ڲ�����ĵ���ȫ�������ˡ��о��������Ұ���õIJ����������ṩ������,��ֻҪ��Ӳ�����ܺܺø�,������������Ӣΰ����Կ�???
���
����������PPT,���ںŻظ�024��ȡ~
AI�˳�����û��ֹͣ��,����AI�㷨�Լ�AI������ص�ǰ�ؼ���������Ҫ����̽������,�����Ų��������ʱ����
����Ҫ���ֶ��¼��������ֱ����,ҲҪ�����¼����Ķ����ͼ���,����̽���ʹ��²��Ǻϸ���㷨����ʦ,��ô�����������ʲô��?֪�����Ѿ����˴�:

���Ұ�
- ���������־ͬ�����ڴ�,���˺�Ը�����㽻��
- �����ϲ�����˵�����,��ӭ��ע��֧��,���������~
����Ҳ������һЩ�Լ���˽��,ϣ���ܰ��������,�ڴ����ش�������