CONTENTS
Leaky Units and Other Strategies for Multiple Time Scales
- One way to deal with long-term dependencies is to design a model that operates at multiple time scales, so that some parts of the model operate at fine-grained time scales and can handle small details, while other parts operate at coarse time scales and transfer information from the distant past to the present more efficiently. Various strategies for building both fine and coarse time scales are possible. These include the addition of skip connections across time, ЁАleaky unitsЁБ that integrate signals with different time constants, and the removal of some of the connections used to model fine-grained time scales.
Adding Skip Connections through Time
- One way to obtain coarse time scales is to add direct connections from variables in the distant past to variables in the present. The idea of using such skip connections dates back to Lin et al. (1996) and follows from the idea of incorporating delays in feedforward neural networks (Lang and Hinton, 1988 ). In an ordinary recurrent network, a recurrent connection goes from a unit at time t t t to a unit at time t + 1 t+1 t+1. It is possible to construct recurrent networks with longer delays (Bengio, 1991 ). As we have seen in section 8.2.5 8.2 .5 8.2.5, gradients may vanish or explode exponentially with respect to the number of time steps. Lin et al. (1996) introduced recurrent connections with a time-delay of d d d to mitigate this problem. Gradients now diminish exponentially as a function of Іг d \frac{\tau}{d} dІг? rather than Іг \tau Іг. Since there are both delayed and single step connections, gradients may still explode exponentially in Іг \tau Іг. This allows the learning algorithm to capture longer dependencies although not all long-term dependencies may be represented well in this way.
Leaky Units and a Spectrum of Different Time Scales
-
Another way to obtain paths on which the product of derivatives is close to one is to have units with linear self-connections and a weight near one on these connections. When we accumulate a running average ІЬ ( t ) \mu^{(t)} ІЬ(t) of some value v ( t ) v^{(t)} v(t) by applying the update ІЬ ( t ) Ёћ ІС ІЬ ( t ? 1 ) + ( 1 ? ІС ) v ( t ) \mu^{(t)} \leftarrow \alpha \mu^{(t-1)}+(1-\alpha) v^{(t)} ІЬ(t)ЁћІСІЬ(t?1)+(1?ІС)v(t) the ІС \alpha ІС parameter is an example of a linear selfconnection from ІЬ ( t ? 1 ) \mu^{(t-1)} ІЬ(t?1) to ІЬ ( t ) \mu^{(t)} ІЬ(t).
When ІС \alpha ІС is near one, the running average remembers information about the past for a long time,
and when ІС \alpha ІС is near zero, information about the past is rapidly discarded.
Hidden units with linear self-connections can behave similarly to such running averages. Such hidden units are called leaky units. -
Skip connections through d d d time steps are a way of ensuring that a unit can always learn to be influenced by a value from d d d time steps earlier.
The use of a linear self-connection with a weight near one is a different way of ensuring that the unit can access values from the past. The linear self-connection approach allows this effect to be adapted more smoothly and flexibly by adjusting the real-valued ІС \alpha ІС rather than by adjusting the integer-valued skip length. -
These ideas were proposed by Mozer (1992) and by El Hihi and Bengio (1996). Leaky units were also found to be useful in the context of echo state networks (Jaeger et al., 2007).
-
There are two basic strategies for setting the time constants used by leaky units.
One strategy is to manually fix them to values that remain constant, for example by sampling their values from some distribution once at initialization time.
Another strategy is to make the time constants free parameters and learn them. Having such leaky units at different time scales appears to help with long-term dependencies (Mozer, 1992; Pascanu et al., 2013)
Removing Connections
-
Another approach to handle long-term dependencies is the idea of organizing the state of the RNN at multiple time-scales (El Hihi and Bengio, 1996 ), with information flowing more easily through long distances at the slower time scales.
-
This idea differs from the skip connections through time discussed earlier because it involves actively removing length-one connections and replacing them with longer connections. Units modified in such a way are forced to operate on a long time scale. Skip connections through time a d d a d d add edges. Units receiving such new connections may learn to operate on a long time scale but may also choose to focus on their other short-term connections.
-
There are different ways in which a group of recurrent units can be forced to operate at different time scales.
One option is to make the recurrent units leaky, but to have different groups of units associated with different fixed time scales. This was the proposal in Mozer (1992) and has been successfully used in Pascanu et al. (2013).
Another option is to have explicit and discrete updates taking place at different times, with a different frequency for different groups of units. This is the approach of El Hihi and Bengio (1996) and Koutnik et al. (2014). It worked well on a number of benchmark datasets.
The Long Short-Term Memory and Other Gated RNNs
-
As of this writing, the most effective sequence models used in practical applications are called gated RNNs. These include the long short-term memory and networks based on the gated recurrent unit.
-
Like leaky units, gated RNNs are based on the idea of creating paths through time that have derivatives that neither vanish nor explode.
Leaky units did this with connection weights that were either manually chosen constants or were parameters.
Gated RNNs generalize this to connection weights that may change at each time step. -
Leaky units allow the network to accumulate information (such as evidence for a particular feature or category) over a long duration. However, once that information has been used, it might be useful for the neural network to forget the old state. For example, if a sequence is made of sub-sequences and we want a leaky unit to accumulate evidence inside each sub-subsequence, we need a mechanism to forget the old state by setting it to zero. Instead of manually deciding when to clear the state, we want the neural network to learn to decide when to do it. This is what gated RNNs do.
LSTM
-
The clever idea of introducing self-loops to produce paths where the gradient can flow for long durations is a core contribution of the initial long short-term memory (LSTM) model (Hochreiter and Schmidhuber, 1997). A crucial addition has been to make the weight on this self-loop conditioned on the context, rather than fixed (Gers et al., 2000). By making the weight of this self-loop gated (controlled by another hidden unit), the time scale of integration can be changed dynamically.
-
In this case, we mean that even for an LSTM with fixed parameters, the time scale of integration can change based on the input sequence, because the time constants are output by the model itself. The LSTM has been found extremely successful in many applications, such as unconstrained handwriting recognition (Graves al., 2009 ), speech recognition (Graves et al., 2013; Graves and Jaitly, 201 handwriting generation (Graves, 2013), machine translation (Sutskever et al., 2014), image captioning (Kiros et al., 2014b; Vinyals et al., 2014b; Xu et al., 2015) and parsing (Vinyals et al., 2014a).
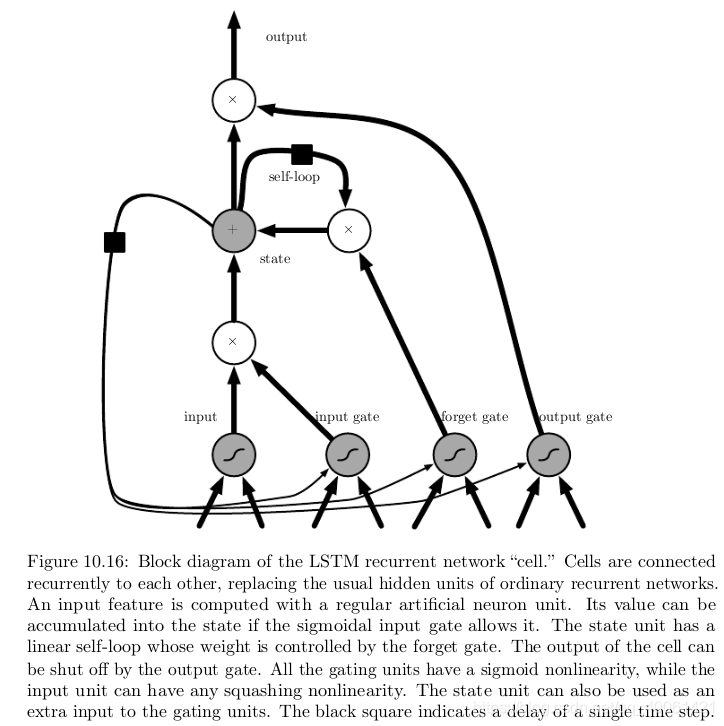
-
The LSTM block diagram is illustrated in figure 10.16 10.16 10.16. The corresponding forward propagation equations are given below, in the case of a shallow recurrent network architecture. Deeper architectures have also been successfully used (Grave al., 2013; Pascanu et al. 2014 a 2014 \mathrm{a} 2014a ). Instead of a unit that simply applies an elementwise nonlinearity to the affine transformation of inputs and recurrent units, LSTM recurrent networks have "LSTM cells" that have an internal recurrence (a self-loop), in addition to the outer recurrence of the RNN. Each cell has the same inputs and outputs as an ordinary recurrent network, but has more parameters and a system of gating units that controls the flow of information. The most important component is the state unit s i ( t ) s_{i}^{(t)} si(t)? that has a linear self-loop similar to the leaky units described in the previous section. However, here, the self-loop weight (or the associated time constant) is controlled by a forget gate unit f i ( t ) f_{i}^{(t)} fi(t)? (for time step t t t and cell i i i ), that sets this weight to a value between 0 and 1 via a sigmoid unit:
f i ( t ) = Ів ( b i f + ЁЦ j U i , j f x j ( t ) + ЁЦ j W i , j f h j ( t ? 1 ) ) f_{i}^{(t)}=\sigma\left(b_{i}^{f}+\sum_{j} U_{i, j}^{f} x_{j}^{(t)}+\sum_{j} W_{i, j}^{f} h_{j}^{(t-1)}\right) fi(t)?=Ів(bif?+jЁЦ?Ui,jf?xj(t)?+jЁЦ?Wi,jf?hj(t?1)?)
where x ( t ) \boldsymbol{x}^{(t)} x(t) is the current input vector and h ( t ) \boldsymbol{h}^{(t)} h(t) is the current hidden layer vector, containing the outputs of all the LSTM cells, and b f , U f , W f \boldsymbol{b}^{f}, \boldsymbol{U}^{f}, \boldsymbol{W}^{f} bf,Uf,Wf are respectively biases, input weights and recurrent weights for the forget gates. The LSTM cell internal state is thus updated as follows, but with a conditional self-loop weight f i ( t ) f_{i}^{(t)} fi(t)?
s i ( t ) = f i ( t ) s i ( t ? 1 ) + g i ( t ) Ів ( b i + ЁЦ j U i , j x j ( t ) + ЁЦ j W i , j h j ( t ? 1 ) ) s_{i}^{(t)}=f_{i}^{(t)} s_{i}^{(t-1)}+g_{i}^{(t)} \sigma\left(b_{i}+\sum_{j} U_{i, j} x_{j}^{(t)}+\sum_{j} W_{i, j} h_{j}^{(t-1)}\right) si(t)?=fi(t)?si(t?1)?+gi(t)?Ів(bi?+jЁЦ?Ui,j?xj(t)?+jЁЦ?Wi,j?hj(t?1)?)
where b , U \boldsymbol{b}, \boldsymbol{U} b,U and W \boldsymbol{W} W respectively denote the biases, input weights and recurrent weights into the LSTM cell. The external input gate unit g i ( t ) g_{i}^{(t)} gi(t)? is computed similarly to the forget gate (with a sigmoid unit to obtain a gating value between 0 and 1 ), but with its own parameters:
g i ( t ) = Ів ( b i g + ЁЦ j U i , j g x j ( t ) + ЁЦ j W i , j g h j ( t ? 1 ) ) g_{i}^{(t)}=\sigma\left(b_{i}^{g}+\sum_{j} U_{i, j}^{g} x_{j}^{(t)}+\sum_{j} W_{i, j}^{g} h_{j}^{(t-1)}\right) gi(t)?=Ів(big?+jЁЦ?Ui,jg?xj(t)?+jЁЦ?Wi,jg?hj(t?1)?) -
The output h i ( t ) h_{i}^{(t)} hi(t)? of the LSTM cell can also be shut off, via the output gate q i ( t ) q_{i}^{(t)} qi(t)?, which also uses a sigmoid unit for gating:
h i ( t ) = tanh ? ( s i ( t ) ) q i ( t ) q i ( t ) = Ів ( b i o + ЁЦ j U i , j o x j ( t ) + ЁЦ j W i , j o h j ( t ? 1 ) ) \begin{aligned} &h_{i}^{(t)}=\tanh \left(s_{i}^{(t)}\right) q_{i}^{(t)} \\ &q_{i}^{(t)}=\sigma\left(b_{i}^{o}+\sum_{j} U_{i, j}^{o} x_{j}^{(t)}+\sum_{j} W_{i, j}^{o} h_{j}^{(t-1)}\right) \end{aligned} ?hi(t)?=tanh(si(t)?)qi(t)?qi(t)?=Ів(bio?+jЁЦ?Ui,jo?xj(t)?+jЁЦ?Wi,jo?hj(t?1)?)?
which has parameters b o , U o , W o \boldsymbol{b}^{o}, \boldsymbol{U}^{o}, \boldsymbol{W}^{o} bo,Uo,Wo for its biases, input weights and recurrent weights, respectively. Among the variants, one can choose to use the cell state s i ( t ) s_{i}^{(t)} si(t)? as an extra input (with its weight) into the three gates of the i i i -th unit, as shown in figure 10.16 10.16 10.16. This would require three additional parameters. -
LSTM networks have been shown to learn long-term dependencies more easily than the simple recurrent architectures, first on artificial data sets designed for testing the ability to learn long-term dependencies (Bengio et al., 1994; Hochreiter and Schmidhuber, 1997; Hochreiter et al., 2001), then on challenging sequence processing tasks where state-of-the-art performance was obtained (Graves, 2012; Graves et al. 2013; Sutskever et al., 2014). Variants and alternatives to the LSTM have been studied and used and are discussed next.
Other Gated RNNs
- Which pieces of the LSTM architecture are actually necessary?
What other successful architectures could be designed that allow the network to dynamically control the time scale and forgetting behavior of different units? - Some answers to these questions are given with the recent work on gated RNNs, whose units are also known as gated recurrent units or GRUs (Cho et al., 2014b; Chung et al.
2014
,
2015
a
;
2014,2015 \mathrm{a} ;
2014,2015a; Jozefowicz et al. 2015 ; Chrupala et al., 2015).
The main difference with the LSTM is that a single gating unit simultaneously controls the forgetting factor and the decision to update the state unit. The update equations are the following:
h i ( t ) = u i ( t ? 1 ) h i ( t ? 1 ) + ( 1 ? u i ( t ? 1 ) ) Ів ( b i + ЁЦ j U i , j x j ( t ? 1 ) + ЁЦ j W i , j r j ( t ? 1 ) h j ( t ? 1 ) ) h_{i}^{(t)}=u_{i}^{(t-1)} h_{i}^{(t-1)}+\left(1-u_{i}^{(t-1)}\right) \sigma\left(b_{i}+\sum_{j} U_{i, j} x_{j}^{(t-1)}+\sum_{j} W_{i, j} r_{j}^{(t-1)} h_{j}^{(t-1)}\right) hi(t)?=ui(t?1)?hi(t?1)?+(1?ui(t?1)?)Ів(bi?+jЁЦ?Ui,j?xj(t?1)?+jЁЦ?Wi,j?rj(t?1)?hj(t?1)?)
where u \boldsymbol{u} u stands for ЁАupdateЁБ gate and r r r for ЁАresetЁБ gate. Their value is defined as usual:
u i ( t ) = Ів ( b i u + ЁЦ j U i , j u x j ( t ) + ЁЦ j W i , j u h j ( t ) ) u_{i}^{(t)}=\sigma\left(b_{i}^{u}+\sum_{j} U_{i, j}^{u} x_{j}^{(t)}+\sum_{j} W_{i, j}^{u} h_{j}^{(t)}\right) ui(t)?=Ів(biu?+jЁЦ?Ui,ju?xj(t)?+jЁЦ?Wi,ju?hj(t)?)
and
r i ( t ) = Ів ( b i r + ЁЦ j U i , j r x j ( t ) + ЁЦ j W i , j r h j ( t ) ) r_{i}^{(t)}=\sigma\left(b_{i}^{r}+\sum_{j} U_{i, j}^{r} x_{j}^{(t)}+\sum_{j} W_{i, j}^{r} h_{j}^{(t)}\right) ri(t)?=Ів(bir?+jЁЦ?Ui,jr?xj(t)?+jЁЦ?Wi,jr?hj(t)?) - The reset and updates gates can individually ЁАignoreЁБ parts of the state vector.
The update gates act like conditional leaky integrators that can linearly gate any dimension, thus choosing to copy it (at one extreme of the sigmoid) or completely ignore it (at the other extreme) by replacing it by the new ЁАtarget stateЁБ value (towards which the leaky integrator wants to converge).
The reset gates control which parts of the state get used to compute the next target state, introducing an additional nonlinear effect in the relationship between past state and future state. - Many more variants around this theme can be designed. For example the reset gate (or forget gate) output could be shared across multiple hidden units. Alternately, the product of a global gate (covering a whole group of units, such as an entire layer) and a local gate (per unit) could be used to combine global control and local control. However, several investigations over architectural variations of the LSTM and GRU found no variant that would clearly beat both of these across a wide range of tasks (Greff et al., 2015; Jozefowicz et al., 2015). Grefl et al. (2015) found that a crucial ingredient is the forget gate, while Jozefowicz et al. (2015) found that adding a bias of 1 to the LSTM forget gate, a practice advocated by Gers et al. (2000), makes the LSTM as strong as the best of the explored architectural variants.
Optimization for Long-Term Dependencies
-
Section 8.2.5 and section 10.7 10.7 10.7 have described the vanishing and exploding gradient problems that occur when optimizing RNNs over many time steps.
-
An interesting idea proposed by Martens and Sutskever (2011) is that second derivatives may vanish at the same time that first derivatives vanish. Second-order optimization algorithms may roughly be understood as dividing the first derivative by the second derivative (in higher dimension, multiplying the gradient by the inverse Hessian). If the second derivative shrinks at a similar rate to the first derivative, then the ratio of first and second derivatives may remain relatively constant. Unfortunately, second-order methods have many drawbacks, including high computational cost, the need for a large minibatch, and a tendency to be attracted to saddle points. Martens and Sutskever (2011) found promising results using second-order methods. Later, Sutskever et al. (2013) found that simpler methods such as Nesterov momentum with careful initialization could achieve similar results. See Sutskever (2012) for more detail. Both of these approaches have largely been replaced by simply using SGD (even without momentum) appliec to LSTMs. This is part of a continuing theme in machine learning that it is often much easier to design a model that is easy to optimize than it is to design a more powerful optimization algorithm.
Clipping Gradients
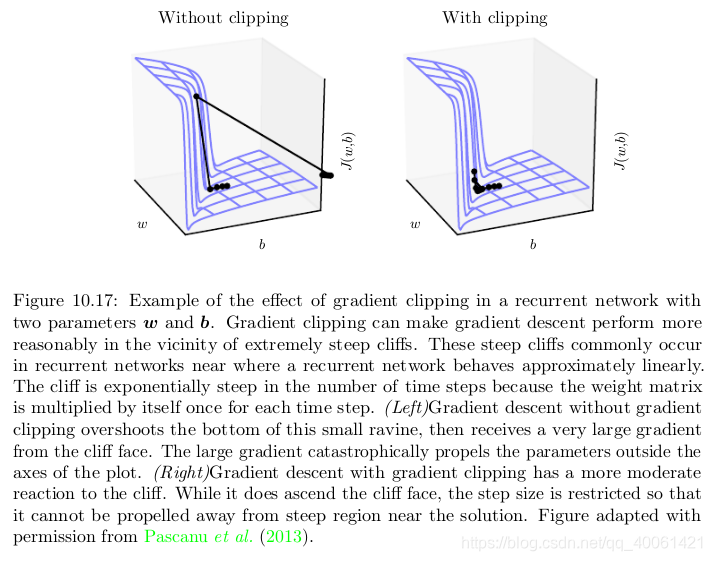
-
As discussed in section 8.2.4, strongly nonlinear functions such as those computed by a recurrent net over many time steps tend to have derivatives that can be either very large or very small in magnitude. This is illustrated in figure 8.3 8.3 8.3 and figure 10.17 10.17 10.17, in which we see that the objective function (as a function of the parameters) has a ЁАlandscapeЁБ in which one finds ЁАcliffsЁБ: wide and rather flat regions separated by tiny regions where the objective function changes quickly forming a kind of cliff.
-
The difficulty that arises is that when the parameter gradient is very large, gradient descent parameter update could throw the parameters very far, into region where the objective function is larger, undoing much of the work that had been done to reach the current solution. The gradient tells us the direction that corresponds to the steepest descent within an infinitesimal region surrounding the current parameters. Outside of this infinitesimal region, the cost function may begin to curve back upwards. The update must be chosen to be small enough to avoid traversing too much upward curvature. We typically use learning rates that decay slowly enough that consecutive steps have approximately the same learning rate. A step size that is appropriate for a relatively linear part of the landscape is often inappropriate and causes uphill motion if we enter a more curved part of the landscape on the next step.
-
A simple type of solution has been in use by practitioners for many years: clipping the gradient. There are different instances of this idea (Mikolov, 2012; Pascanu et al., 2013).
One option is to clip the parameter gradient from a minibatch element-wise (Mikolov, 2012) just before the parameter update.
Another is to clip the norm ЁЮ g ЁЮ \|\boldsymbol{g}\| ЁЮgЁЮ of the gradient g \boldsymbol{g} g (Pascanu et al., 2013) just before the parameter update:
?if? ЁЮ g ЁЮ > v g Ёћ g v ЁЮ g ЁЮ \begin{array}{r} \text { if }\|\boldsymbol{g}\|>v \\ \boldsymbol{g} \leftarrow \frac{\boldsymbol{g} v}{\|\boldsymbol{g}\|} \end{array} ?if?ЁЮgЁЮ>vgЁћЁЮgЁЮgv??
where v v v is the norm threshold and g \boldsymbol{g} g is used to update parameters. Because the gradient of all the parameters (including different groups of parameters, such as weights and biases) is renormalized jointly with a single scaling factor, the latter method has the advantage that it guarantees that each step is still in the gradient direction, but experiments suggest that both forms work similarly. -
Although the parameter update has the same direction as the true gradient, with gradient norm clipping, the parameter update vector norm is now bounded. This bounded gradient avoids performing a detrimental step when the gradient explodes. In fact, even simply taking a random step when the gradient magnitude is above a threshold tends to work almost as well. If the explosion is so severe that the gradient is numerically Inf or Nan (considered infinite or not-a-number), then a random step of size v v v can be taken and will typically move away from the numerically unstable configuration.
-
Clipping the gradient norm per-minibatch will not change the direction of the gradient for an individual minibatch. However, taking the average of the norm-clipped gradient from many minibatches is not equivalent to clipping the norm of the true gradient (the gradient formed from using all examples). Examples that have large gradient norm, as well as examples that appear in the same minibatch as such examples, will have their contribution to the final direction diminished. This stands in contrast to traditional minibatch gradient descent, where the true gradient direction is equal to the average over all minibatch gradients.
-
Put another way, traditional stochastic gradient descent uses an unbiased estimate of the gradient, while gradient descent with norm clipping introduces a heuristic bias that we know empirically to be useful.
With elementwise clipping, the direction of the update is not aligned with the true gradient or the minibatch gradient, but it is still a descent direction. It has also been proposed (Graves, 2013) to clip the back-propagated gradient (with respect to hidden units) but no comparison has been published between these variants; we conjecture that all these methods behave similarly.
Regularizing to Encourage Information Flow
- Gradient clipping helps to deal with exploding gradients, but it does not help with vanishing gradients. To address vanishing gradients and better capture long-term dependencies, we discussed the idea of creating paths in the computational graph of the unfolded recurrent architecture along which the product of gradients associated with arcs is near 1 .
- One approach to achieve this is with LSTMs and other selfloops and gating mechanisms, described above in section 10.10.
Another idea is to regularize or constrain the parameters so as to encourage ЁАinformation flow.ЁБ In particular, we would like the gradient vector ? h ( t ) L \nabla_{\boldsymbol{h}^{(t)}} L ?h(t)?L being back-propagated to maintain its magnitude, even if the loss function only penalizes the output at the end of the sequence. - Formally, we want
( ? h ( t ) L ) ? h ( t ) ? h ( t ? 1 ) \left(\nabla_{\boldsymbol{h}^{(t)}} L\right) \frac{\partial \boldsymbol{h}^{(t)}}{\partial \boldsymbol{h}^{(t-1)}} (?h(t)?L)?h(t?1)?h(t)?
to be as large as
? h ( t ) L \nabla_{\boldsymbol{h}^{(t)}} L ?h(t)?L
With this objective, Pascanu et al. (2013) propose the following regularizer:
ІИ = ЁЦ t ( ЈO ЈO ( ? h ( t ) L ) ? h ( t ) ? h ( t ? 1 ) ЈO ЈO ЁЮ ? h ( t ) L ЈO ЈO ? 1 ) 2 \Omega=\sum_{t}\left(\frac{||\left(\nabla_{\boldsymbol{h}^{(t)}} L\right) \frac{\partial h^{(t)}}{\partial \boldsymbol{h}^{(t-1)}}||}{\| \nabla_{\boldsymbol{h}^{(t)}} L||}-1\right)^{2} ІИ=tЁЦ?(ЁЮ?h(t)?LЈOЈOЈOЈO(?h(t)?L)?h(t?1)?h(t)?ЈOЈO??1)2 - Computing the gradient of this regularizer may appear difficult, but Pascanu et al. (2013) propose an approximation in which we consider the back-propagated vectors ? h ( t ) L \nabla_{\boldsymbol{h}^{(t)}} L ?h(t)?L as if they were constants (for the purpose of this regularizer, so that there is no need to back-propagate through them). The experiments with this regularizer suggest that, if combined with the norm clipping heuristic (which handles gradient explosion), the regularizer can considerably increase the span of the dependencies that an RNN can learn. Because it keeps the RNN dynamics on the edge of explosive gradients, the gradient clipping is particularly important. Without gradient clipping, gradient explosion prevents learning from succeeding. A key weakness of this approach is that it is not as effective as the LSTM for tasks where data is abundant, such as language modeling.
Explicit Memory
-
Intelligence requires knowledge and acquiring knowledge can be done via learning, which has motivated the development of large-scale deep architectures. However, there are different kinds of knowledge.
Some knowledge can be implicit, subconscious, and difficult to verbalize-such as how to walk, or how a dog looks different from a cat.
Other knowledge can be explicit, declarative, and relatively straightforward to put into words - every day commonsense knowledge, like ЁАa cat is a kind of animal,ЁБ or very specific facts that you need to know to accomplish your current goals, like "the meeting with the sales team is at 3 : 00 P M 3: 00 \mathrm{PM} 3:00PM in room 141. " 141 . " 141." -
Neural networks excel at storing implicit knowledge. However, they struggle to memorize facts. Stochastic gradient descent requires many presentations of the same input before it can be stored in a neural network parameters, and even then, that input will not be stored especially precisely. Graves et al. ( 2014b ) hypothesized that this is because neural networks lack the equivalent of the working memory system that allows human beings to explicitly hold and manipulate pieces of information that are relevant to achieving some goal. Such explicit memory components would allow our systems not only to rapidly and ЁАintentionallyЁБ store and retrieve specific facts but also to sequentially reason with them. The need for neural networks that can process information in a sequence of steps, changing the way the input is fed into the network at each step, has long been recognized as important for the ability to reason rather than to make automatic, intuitive responses to the input (Hinton, 1990 1990 1990 )
-
To resolve this difficulty, Weston et al. (2014) introduced memory networks that include a set of memory cells that can be accessed via an addressing mechanism. Memory networks originally required a supervision signal instructing them how to use their memory cells. Graves et al. ( 2014b ) introduced the neural Turing machine, which is able to learn to read from and write arbitrary content to memory cells without explicit supervision about which actions to undertake, and allowed end-to-end training without this supervision signal, via the use of a content-based soft attention mechanism (see Bahdanau et al. (2015) and section 12.4.5.1). This soft addressing mechanism has become standard with other related architectures emulating algorithmic mechanisms in a way that still allows gradient-based optimization( Sukhbaatar et al. , 2015 ; Joulin and Mikolov , 2015 ; Kumar et al., 2015 ; Vinyals et al., 2015a ; Grefenstette et al., 2015 ).
-
Each memory cell can be thought of as an extension of the memory cells in LSTMs and GRUs. The difference is that the network outputs an internal state that chooses which cell to read from or write to, just as memory accesses in a digital computer read from or write to a specific address.
-
It is difficult to optimize functions that produce exact, integer addresses.
To alleviate this problem, NTMs actually read to or write from many memory cells simultaneously.
To read, they take a weighted average of many cells.
To write, they modify multiple cells by different amounts.
The coefficients for these operations are chosen to be focused on a small number of cells, for example, by producing them via a softmax function. Using these weights with non-zero derivatives allows the functions controlling access to the memory to be optimized using gradient descent. The gradient on these coefficients indicates whether each of them should be increased or decreased, but the gradient will typically be large only for those memory addresses receiving a large coefficient. -
These memory cells are typically augmented to contain a vector, rather than the single scalar stored by an LSTM or GRU memory cell. There are two reasons to increase the size of the memory cell.
One reason is that we have increased the cost of accessing a memory cell. We pay the computational cost of producing a coefficient for many cells, but we expect these coefficients to cluster around a small number of cells. By reading a vector value, rather than a scalar value, we can offset some of this cost.
Another reason to use vector-valued memory cells is that they allow for content-based addressing, where the weight used to read to or write from a cell is a function of that cell. Vector-valued cells allow us to retrieve a complete vector-valued memory if we are able to produce a pattern that matches some but not all of its elements. This is analogous to the way that people can recall the lyrics of a song based on a few words. We can think of a content-based read instruction as saying, ЁАRetrieve the lyrics of the song that has the chorus 'We all live in a yellow submarine.ЁБ Content-based addressing is more useful when we make the objects to be retrieved large - if every letter of the song was stored in a separate memory cell, we would not be able to find them this way. By comparison, location-based addressing is not allowed to refer to the content of the memory. We can think of a location-based read instruction as saying ЁАRetrieve the lyrics of the song in slot 347 .ЁБ Location-based addressing can often be a perfectly sensible mechanism even when the memory cells are small. -
If the content of a memory cell is copied (not forgotten) at most time steps, then the information it contains can be propagated forward in time and the gradients propagated backward in time without either vanishing or exploding.
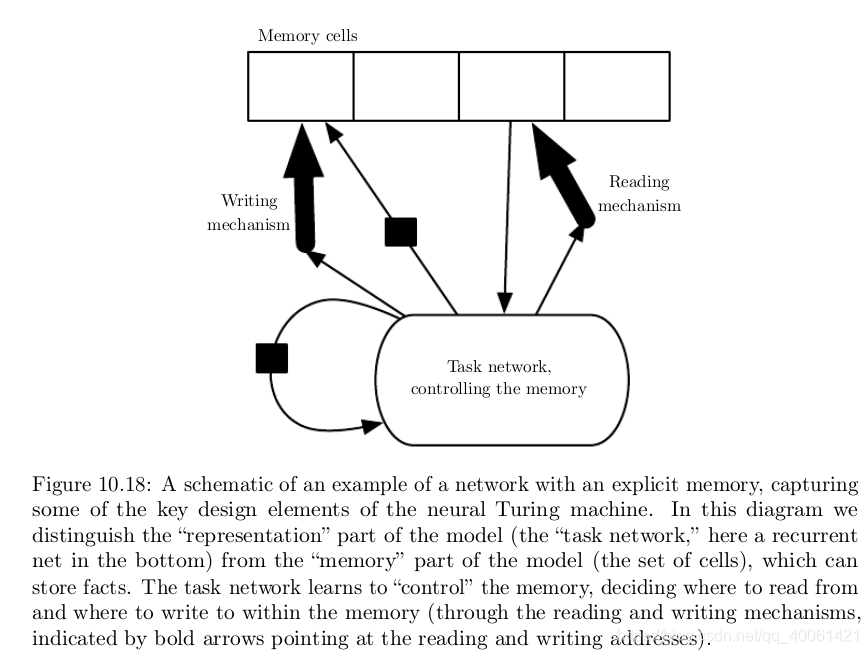
-
The explicit memory approach is illustrated in figure 10.18 10.18 10.18, where we see that a ЁАtask neural networkЁБ is coupled with a memory. Although that task neural network could be feedforward or recurrent, the overall system is a recurrent network. The task network can choose to read from or write to specific memory addresses. Explicit memory seems to allow models to learn tasks that ordinary RNNs or LSTM RNNs cannot learn. One reason for this advantage may be because information and gradients can be propagated (forward in time or backwards in time, respectively) for very long durations.
-
As an alternative to back-propagation through weighted averages of memory cells, we can interpret the memory addressing coefficients as probabilities and stochastically read just one cell (Zaremba and Sutskever, 2015). Optimizing models that make discrete decisions requires specialized optimization algorithms, described in section 20.9.1. So far, training these stochastic architectures that make discrete decisions remains harder than training deterministic algorithms that make soft decisions.
-
Whether it is soft (allowing back-propagation) or stochastic and hard, the mechanism for choosing an address is in its form identical to the attention mechanism which had been previously introduced in the context of machine translation ( Bahdanau et al. , 2015 ) and discussed in section 12.4.5.1 . The idea of attention mechanisms for neural networks was introduced even earlier, in the context of handwriting generation (Graves , 2013 ), with an attention mechanism that was constrained to move only forward in time through the sequence. In the case of machine translation and memory networks, at each step, the focus of attention can move to a completely different place, compared to the previous step.
-
Recurrent neural networks provide a way to extend deep learning to sequential data. They are the last major tool in our deep learning toolbox. Our discussion now moves to how to choose and use these tools and how to apply them to real-world tasks.