еЊвЊ: БОеТжївЊЪЧЙигкздБрТыЦїЕФдРэМАЦфгІгУ,здБрТыЦїЪЧвЛжжЮоМрЖНбЇЯАЗНЗЈ,ПЩгУгкЪ§ОнНЕЮЌМАЬиеїГщШЁЁЃЦфжаздБрТыЦїгЩБрТыЦї(Encoder)КЭНтТыЦї(Decoder)СНВПЗжзщГЩЁЃБрТыЦїЭЈГЃЖдЪфШыЖдЯѓНјаабЙЫѕБэЪО,НтТыЦїЖдОбЙЫѕБэЪОКѓЕФcodeНјааНтТыжиЙЙЁЃ
Auto-encoderЛЙПЩвдЖдФЃаЭНјаадЄбЕСЗ,ЕУЕНКУЕФФЃаЭГѕЪМЛЏЕФВЮЪ§ЁЃвдМАAuto-encoderПЩвдЖдЪ§ОнНјааНЕЮЌДІРэ,ЧвНЕЮЌКѓЕФЪ§ОнПЩвдКмЭъећЕФБЃСєдЪМЪ§ОнЕФаХЯЂЁЃБОеТНЋЛсНщЩмAuto-encoderдкЮФБОМьЫї(Text Retrieval)ЁЂЭМЯёЫбЫї(Image Search)ЁЂдЄбЕСЗЩюЖШЩёОЭјТч(Pre-training DNN)вдМАдкОэЛ§ЩёОЭјТч(CNN)ЩЯЕФгІгУЁЃ
ЮФеТФПТМ
1. здБрТыЦї(Auto-encoder)
1.1 ЛљБОЫМЯы
Auto-encoderБОжЪЩЯОЭЪЧвЛИіздЮвбЙЫѕКЭНтбЙЕФЙ§ГЬ,вЊЧѓЪфШыКЭЪфГіЕФЭМЦЌдННгНќдНКУ,зюКѓЕУЕНЕФcodeОЭЪЧИУinputЭМЦЌЕФНЕЮЌНсЙћЁЃЦфжабЙЫѕЕУЕНЕФcodeДњБэСЫЖддЪМЪ§ОнЕФФГжжНєДеОЋМђЕФгааЇБэДя,МДНЕЮЌНсЙћЁЃетИіЙ§ГЬашвЊБрТыЦї(Encoder)КЭНтТыЦї(Decoder):
- Encoder(БрТыЦї),ЫќПЩвдАбдЯШЕФЭМЯёбЙЫѕГЩИќЕЭЮЌЖШЕФЯђСП
- Decoder(НтТыЦї),ЫќПЩвдАббЙЫѕКѓЕФЯђСПЛЙдГЩЭМЯё

EncoderКЭDecoderЕЅЖРФУГівЛИіЖМЮоЗЈНјаабЕСЗ,ЮвУЧашвЊАбЫќУЧСЌНгЦ№РД,етбљећИіЩёОЭјТчЕФЪфШыКЭЪфГіЖМЪЧЮвУЧвбгаЕФЭМЯёЪ§Он,ОЭПЩвдЭЌЪБЖдEncoderКЭDecoderНјаабЕСЗ,ЖјНЕЮЌКѓЕФБрТыНсЙћОЭПЩвдДгзюжаМфЕФФЧВуhidden layerжаЛёШЁЁЃ
1.2 Compare with PCA
ЪЕМЪЩЯPCAгУЕНЕФЫМЯыгыжЎЗЧГЃРрЫЦ,PCAЕФЙ§ГЬБОжЪЩЯОЭЪЧАДзщМўВ№Зж,дйАДзщМўжиЙЙЕФЙ§ГЬЁЃ
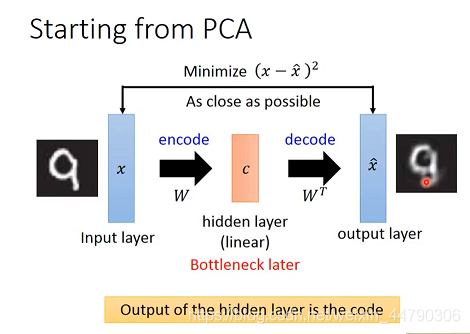
дкPCAжа,ЮвУЧЯШАбОљвЛЛЏКѓЕФ x x xИљОнзщМў W W WЗжНтЕНИќЕЭЮЌЖШЕФc,ШЛКѓдйНЋзщМўШЈжиcГЫЩЯзщМўЕФЗДжУ W T W^T WTЕУЕНжизщКѓЕФ x ^ \hat x x^ ЭЌбљЮвУЧЦкЭћжиЙЙКѓЕФ x ^ \hat x x^ гыдЪМЕФxдННгНќдНКУЁЃ
ЩЯЪіЙ§ГЬПДзїЪЧЩёОЭјТч,ФЧУДдЪМЕФxОЭЪЧinput layer,жиЙЙ x ^ \hat x x^ ОЭЪЧoutput layer,жаМфзщМўЗжНтШЈжиcОЭЪЧhidden layer,дкPCAжаЫќЪЧlinearЕФ,ЭЈГЃгжНаЫќЦПОБВу(Bottleneck layer)ЁЃ
2. ЩюЖШздБрТыЦї(Deep Auto-encoder)
2.1 Deep Auto-encoderЕФЛљБОЫМЯы
здБрТыЦїПЩвдЪЧЩюЖШНсЙЙ,ЖдdeepЕФздБрТыЦїРДЫЕ,ЪЕМЪЩЯОЭЪЧЭЈЙ§ЖрМЖБрТыНЕЮЌ,дйОЙ§ЖрМЖНтТыЛЙдЕФЙ§ГЬЁЃ
- Дгinput layerЕНbottleneck layerЕФВПЗжЖМЪєгкEncoder
- Дгbottleneck layerЕНoutput layerЕФВПЗжЖМЪєгкDecoder
- bottleneck layerЕФoutputОЭЪЧздБрТыНсЙћCode
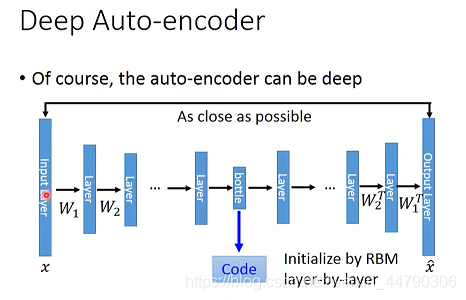
зЂвт:АДееPCAЕФЫМТЗ,дђEncoderЕФВЮЪ§ W i W_i Wi?ашвЊКЭDecoderЕФВЮЪ§ W i T W_i^T WiT?БЃГжвЛжТЕФЖдгІЙиЯЕ,етПЩвдЭЈЙ§ИјСНепЯрЭЌЕФГѕЪМжЕВЂЩшжУЭЌбљЕФИќаТЙ§ГЬЕУЕН,етбљзіЕФКУДІЪЧ,ПЩвдНкЪЁвЛАыЕФВЮЪ§,НЕЕЭoverfittingЕФИХТЪЁЃ(ЕЋЪЕМЪЩЯгжВЛЪЧБивЊЕФ,жБНгЗДЯђДЋВЅЙ§ГЬШЅбЕСЗ)
2.2 DeepздБрТыЦїЕФгХЪЦ
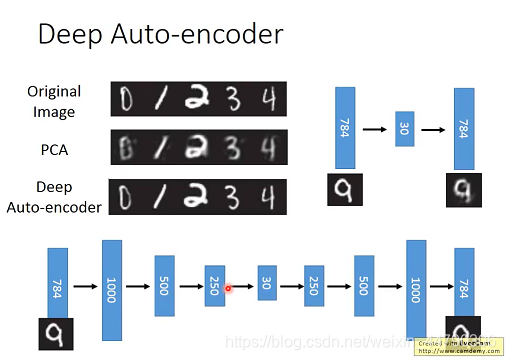
ЯТЭМЗжБ№ВЩгУPCAКЭDeep Auto-encoderЖдЪжаДЪ§зжБцЪЖНјааБрТыНтТыКѓЕФНсЙћ,гУAuto-encoderзюКѓЪфГіЕФЭМЦЌЯрБШЪфШыЪЧВЛЧхЮњЕФ,вВОЭЪЧЫЕЪфШыЕФЭМЦЌОЙ§НЕЮЌКѓЕФБрТыЪЧУЛАьЗЈдйЭъШЋЛЙдГідРДЭМЦЌЕФКмЖраХЯЂЕФ;ЖјзюЯТУцЪЙгУDeep Auto-encoder,зюКѓЪфГіЕФЭМЦЌЛЙЪЧКмЧхЮњЕФ,вВОЭЪЧЫЕЕУЕНЕФЕЭЮЌcodeЪЧЛЙЪЧБШНЯЭъећЕФБЃСєСЫдЪМЭМЦЌаХЯЂЁЃПЩвдПДГі,DeepЕФздБрТыЦїЛЙдаЇЙћБШPCAвЊИќКУЁЃ
3. Auto-encoderЕФгІгУ
3.1 ЮФБОМьЫї(Text Retrieval)
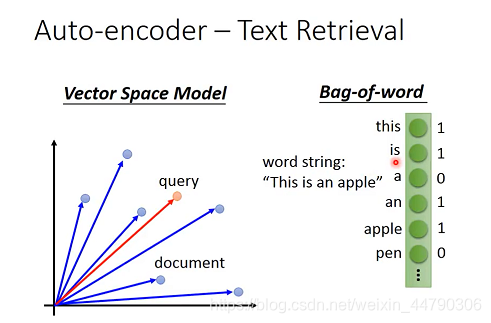
вЛАуЕФЮФБОМьЫїЗНЗЈгаЯђСППеМфФЃаЭ(Vector Space Model),ЩЯЭМжаРЖЩЋЕФЕуДњБэЕФЪЧЮФЕЕ(ОЙ§НЕЮЌКѓ),НгзХМЦЫувЊВщбЏЕФЮФЕЕгыЦфЫћЕФОрРы,бЁдёНЯЮЊНгНќ,ЯрЫЦГЬЖШИпЕФ,ЕЋетИіФЃаЭЕФКУЛЕЙиМќШЁОігкЯђСПЛЏЕФКУЛЕ;ЕЅДЪАќ(Bag-of-word),ЭЈЙ§НЈСЂвЛИіДЪЯђСП,ШєЮФЕЕжаДцдкФГаЉДЪМЧ1ЗёдђМЧ0,ШЛКѓдйМЦЫуЯрЫЦад,ЕЋДЫФЃаЭВЛФмКмКУЕФБэДягявхВуУцЁЃ
- Vector Space Mode: АбУПвЛЦЊЮФеТЖМБэЪОГЩПеМфжаЕФвЛИіvector,ЪфШыФГИіВщбЏДЪЛу,ФЧЮвУЧОЭАбИУВщбЏДЪЛувВБфГЩПеМфжаЕФвЛИіЕу,ВЂМЦЫуqueryКЭУПвЛЦЊdocumentжЎМфЕФФкЛ§(inner product)ЛђгрЯвЯрЫЦЖШ(cos-similarity)ЁЃ
- Bag-of-word: ЮЌЪ§ЕШгкЫљгаДЪЛуЕФзмЪ§,ФГвЛЮЌЕШгк1дђБэЪОИУДЪЛудкетЦЊЮФеТжаГіЯж,ДЫЭтЛЙПЩвдИљОнДЪЛуЕФживЊадНЋЦфМгШЈЁЃ
3.1.1 Auto-encoderаЇЙћКУ
здБрТыЦїПЩвдКмКУЕФЪЕЯжЮФБОЫбЫїЁЃОпгаЯрЭЌжїЬтЕФЮФЕЕЛсгаЯрНќЕФcodeЁЃ
ЫфШЛBag-of-wordВЛФмжБНггУгкБэЪОЮФеТ,ЕЋЮвУЧПЩвдАбЫќзїЮЊAuto-encoderЕФinput,ЭЈЙ§НЕЮЌРДГщШЁгааЇаХЯЂ,вдЛёШЁЫљашЕФvectorЁЃ
ЭЌбљЮЊСЫПЩЪгЛЏ,етРяНЋBag-of-wordНЕЮЌЕНЖўЮЌЦНУцЩЯ,ЯТЭМжаУПИіЕуЖМДњБэвЛЦЊЮФеТ,ВЛЭЌбеЩЋдђДњБэВЛЭЌЕФЮФеТРраЭЁЃ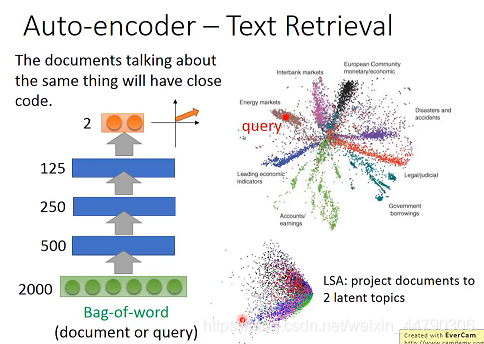
гУЛЇзіВщбЏ,ОЭАбВщбЏЕФгяОфгУЯрЭЌЕФЗНЪНгГЩфЕНИУЖўЮЌЦНУцЩЯ,ВЂевГіЪєгкЭЌвЛРрБ№ЕФЫљгаЮФеТМДПЩЁЃ(БШLSAЫуЗЈаЇЙћвЊКУКмЖр)
3.2 ЭМЯёЫбЫї(Image Search)
вдЭМевЭМзюМђЕЅЕФзіЗЈОЭЪЧжБНгЖдЪфШыЕФЭМЦЌгыЪ§ОнПтжаЕФЭМЦЌМЦЫуpixelЕФЯрЫЦЖШ,ВЂЬєГізюЯёЕФЭМЦЌ,ЕЋетжжЗНЗЈЕФаЇЙћЪЧВЛКУЕФ,вђЮЊЕЅДПЕФpixelЫљФмЙЛБэДяЕФаХЯЂЬЋЩйСЫЁЃШчЯТЭМ:

ЪЙгУAuto-encoderЖдЭМЯёНјааНЕЮЌКЭЬиеїЬсШЁ,ВЂдкБрТыЕУЕНЕФcodeЫљдкПеМфзіМьЫїЁЃ
ЯТЭМеЙЪОСЫEncoderЕФЙ§ГЬ,ВЂИјГіСЫдЭМгыDecoderКѓЕФЭМЯёЖдБШЁЃ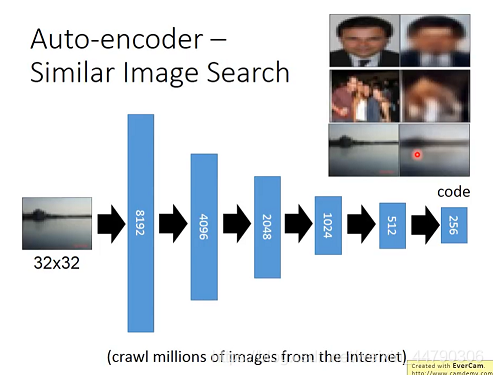
- Auto-encoderПЩвдЭЈЙ§НЕЮЌЬсШЁГівЛеХЭМЯёжазюгагУЕФЬиеїаХЯЂ
- НЕЮЌжЎКѓЪ§ОнЕФsizeБфаЁСЫ,етвтЮЖзХФЃаЭЫљашЕФВЮЪ§вВБфЩйСЫ
ДгвддЭМЕФpixelМЦЫуЯрЫЦЖШКЭвдauto-encoderКѓЕФcodeМЦЫуЯрЫЦЖШЕФСНжжЗНЗЈдкЭМЯёМьЫїЩЯЕФНсЙћЁЃПЩвдПДГіЭЈЙ§дкcodeЩЯМЦЫуЯрЫЦЖШ,газХКмКУЕФаЇЙћЁЃ
3.3 дЄбЕСЗЩюЖШЩёОЭјТч(Pre-training DNN)
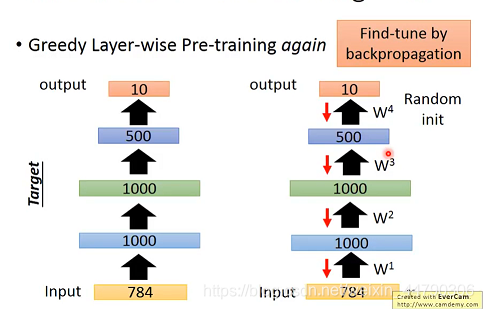
дкЩюЖШбЇЯАжа,здБрТыЦїПЩгУгкдкбЕСЗНзЖЮПЊЪМЧА,ШЗЖЈШЈжиОиеѓWЕФГѕЪМжЕЁЃ
вдMNISTЪ§ОнМЏЮЊР§,ЮвУЧЖдУПВуhidden layerЖМзівЛДЮauto-encoder,ЯъЯИНщЩмЦфЙЄзїЙ§ГЬ:
ЮЊСЫЗНБуБэЪі,етРягУ x ? z ? x ^ x?z?\hat x x?z?x^РДБэЪОвЛИіздБрТыЦї,Цфжа x ^ \hat x x^БэЪіЪфГіВуЕФЮЌЪ§,z БэЪОвўВиВуЕФЮЌЪ§ЁЃ
- ЪзЯШЪЙinputЭЈЙ§вЛИі784?1000?784ЕФздБрТыЦї,ЕБИУздБрТыЦїбЕСЗЮШЖЈКѓ,ОЭАбВЮЪ§
w
1
w^1
w1ЙЬЖЈзЁ,ШЛКѓНЋЪ§ОнМЏжаЫљга784ЮЌЕФЭМЯёЖМзЊЛЏЮЊ1000ЮЌЕФvector
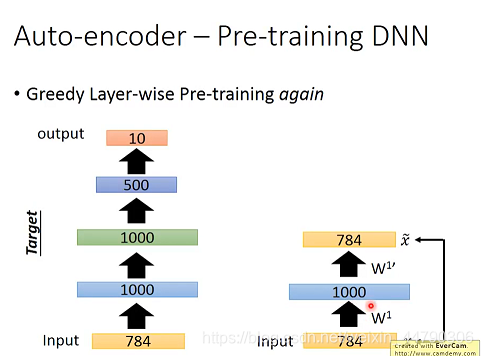
- НгЯТРДдйШУетаЉ1000ЮЌЕФvectorЭЈЙ§вЛИі1000?1000?1000ЕФздБрТыЦї,ЕБЦфбЕСЗЮШЖЈКѓ,дйАбВЮЪ§ w 2 w^2 w2ЙЬЖЈзЁ,ЖдЪ§ОнМЏдйзівЛДЮзЊЛЛ

- НгЯТРДдйгУзЊЛЛКѓЕФЪ§ОнМЏШЅбЕСЗЕкШ§Иі1000?500?1000ЕФздБрТыЦї,бЕСЗЮШЖЈКѓЙЬЖЈВЮЪ§
w
3
w^3
w3,Ъ§ОнМЏдйДЮИќаТзЊЛЏЮЊ500ЮЌ
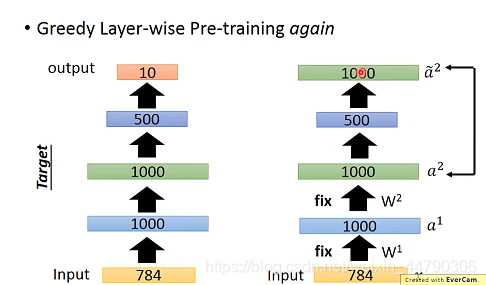
етЪЧвЛжжЬАРЗЕиж№ВудЄбЕСЗЁЃдкдЄбЕСЗКѓЕУЕНШЈжиГѕЪМжЕКѓ,НгзХгУBackpropagationЗДЯђДЋВЅЫуЗЈЖдЭјТчНјааЮЂЕї(fine-tune)ЁЃЙ§ГЬШчЯТ:
зЂвт:
ЕЋЪЧЯжШчНёЧПДѓЕФМЦЫуФмСІ,ЪЙЕУЩюЖШбЇЯАВЂВЛЪЙгУздБрТыРДдЄбЕСЗЁЃдкДѓСПЮоБъЧЉЕФЪ§ОнЧщПіЯТ,ЩюЖШздБрТыЦїШдШЛгавЛЖЈзїгУЁЃ
3.4 Auto-decoder for CNN
дкОэЛ§ЩёОЭјТчжа,вВПЩвдгІгУздБрТыЦїЁЃ
ДІРэЭМЯёЭЈГЃЖМЛсгУОэЛ§ЩёОЭјТчCNN,ЫќЕФЛљБОЫМЯыЪЧНЛЬцЪЙгУОэЛ§ВуКЭГиЛЏВу,ШУЭМЯёдНРДдНаЁ,зюжееЙЦН,етИіЙ§ГЬИњEncoderБрТыЕФЙ§ГЬЦфЪЕЪЧРрЫЦЕФЁЃ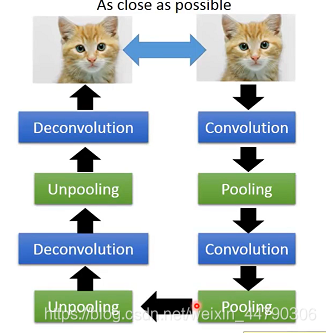
CNNжївЊЪЧОэЛ§(Convolution)КЭГиЛЏ(Pooling)ВйзїЁЃ
вђДЫЯрЖдгІЕФОЭвЊгаЗДОэЛ§(Deconvolution)КЭЗДГиЛЏ(Depooling)ВйзїЁЃ
РэТлЩЯвЊЪЕЯжздБрТыЦї,DecoderжЛашвЊзіИњEncoderЯрЗДЕФЪТМДПЩ,ФЧЖдCNNРДЫЕ,НтТыЕФЙ§ГЬвВОЭБфГЩСЫНЛЬцЪЙгУЗДОэЛ§ВуКЭЗДГиЛЏВуМДПЩЁЃ
ФЧЪВУДЪЧЗДОэЛ§Ву(Deconvolution)КЭЗДГиЛЏВу(Unpooling)Фи?
3.4.1 Unpooling(ЗДГиЛЏ)
зіpoolingЕФЪБКђ,МйШчЕУЕНвЛИі4ЁС4ЕФmatrix,ОЭАбУП4ИіpixelЗжЮЊвЛзщ,ДгУПзщжаЬєвЛИізюДѓЕФСєЯТ,ДЫЪБЭМЯёОЭБфГЩСЫдРДЕФЫФЗжжЎвЛДѓаЁЁЃ
ШчЙћЛЙвЊзіUnpooling,ОЭашвЊЬсЧАМЧТМpoolingЫљЬєбЁЕФpixelдкдЭМжаЕФЮЛжУ,ЯТЭМжагУЛвЩЋЗНПђБъзЂ:
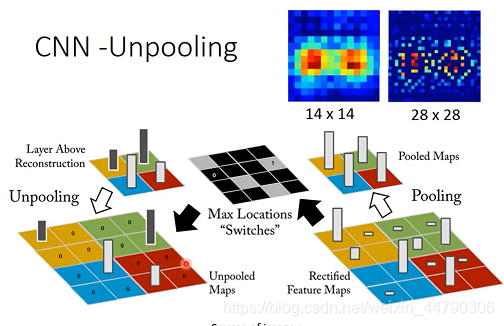
ЕБЧАЕФmatrixЗХДѓЕНдРДЕФЫФБЖ,вВОЭЪЧАб2ЁС2 matrixРяЕФpixelАДеедЯШМЧТМЕФЮЛжУВхШыЗХДѓКѓЕФ4ЁС4 matrixжа,ЦфгрЯюВЙ0МДПЩЁЃ
ЗДГиЛЏКмКУРэНт,жЛашМЧзЁГиЛЏЙ§ГЬжаЕФЮЛжУ(зюДѓжЕГіЯжЕФЕиЗН),дкЗДГиЛЏЕФЙ§ГЬжа,НЋЖдгІЮЛжУжУЯргІЕФжЕ,ЦфгрЮЛжУжУ0МДПЩЁЃ
3.4.2 Deconvolution(ЗДОэЛ§)
ЗДОэЛ§ВйзїОЭгаЕуФбвдРэНтЁЃЪЕМЪЩЯ,ЗДОэЛ§ОЭЪЧОэЛ§ЁЃ
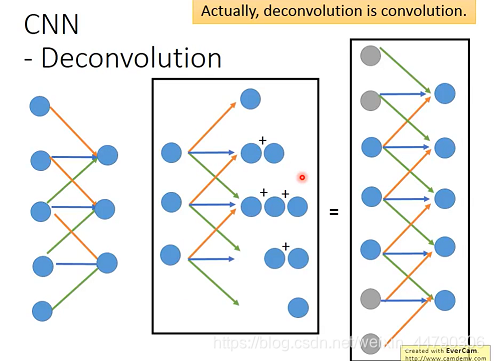
СНИіЙ§ГЬЪЧЕШМлЕФОэЛ§КЭЗДОэЛ§ЕФЙ§ГЬжа,ВЛЭЌЕудкгк,ЗДОэЛ§ашвЊВЙСуЧвЙ§ТЫЦїЕФweightгыОэЛ§ЪЧЯрЗДЕФЁЃ
жЛашЖдОэЛ§КѓЕФНсЙћНјааЬюГф(padding)МДВЙСу,дйНјааГиЛЏВйзї,ЫљЕУжЕОЭЪЧЫљЮНЕФЗДОэЛ§НсЙћЁЃ
4. De-noising Auto-encoder
ШЅдыздБрТыЦїЕФЛљБОЫМЯыЪЧ:АбЪфШыЕФ x x xМгЩЯвЛаЉдыЩљ(noise)БфГЩ x Ёф x' xЁф,дйЖд x Ёф x' xЁф вРДЮзіБрТы(encode)КЭНтТы(decode),ЕУЕНЛЙдКѓЕФ y y y ЁЃ
вЛАуЕФздБрТыЦїЖМЪЧШУЪфШыЪфГіОЁПЩФмНгНќ,ЕЋдкШЅдыздБрТыЦїжа,ЮвУЧЕФФПБъЪЧШУНтТыКѓЕФyгыМгдыЩљжЎЧАЕФxдННгНќдНКУЁЃ
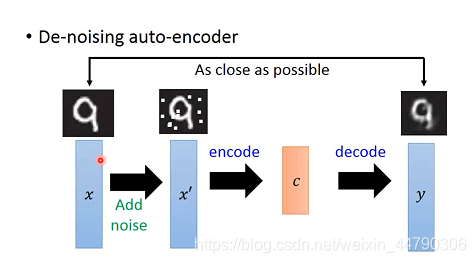
етжжЗНЗЈПЩвддіМгЯЕЭГЕФТГАєад,вђЮЊДЫЪБЕФБрТыЦїEncoderВЛНіНіЪЧдкбЇЯАШчКЮзіБрТы,ЫќЛЙбЇЯАЕНСЫШчКЮЙ§ТЫЕєдыЩљетМўЪТЧщЁЃ
5. Generate(ЩњГЩ)
дкгУздБрТыЦїЕФЪБКђ,ЭЈГЃЪЧЛёШЁEncoderжЎКѓЕФcodeзїЮЊНЕЮЌНсЙћ,ЕЋЪЕМЪЩЯDecoderвВЪЧгазїгУЕФ,ЮвУЧПЩвдФУЫќРДЩњГЩаТЕФЖЋЮїЁЃ
вдMNISTЮЊР§,бЕСЗКУБрТыЦїжЎКѓ,ШЁГіЦфжаЕФDecoder,ЪфШывЛИіЫцЛњЕФcode,ОЭПЩвдЩњГЩвЛеХЭМЯёЁЃ
6. змНсгыеЙЭћ
БОеТжївЊНВЪіСЫздБрТыЕФдРэ,МАЦфдкЮФБОМьЫї(Text Retrieval)ЁЂЭМЯёЫбЫї(Image Search)ЁЂдЄбЕСЗЩюЖШЩёОЭјТч(Pre-training DNN)вдМАдкОэЛ§ЩёОЭјТч(CNN)ЩЯЕФгІгУЁЃ
- ЮФБОМьЫї:ЭЈЙ§auto-encoderНЕЮЌ,ОпгаЯрЭЌжїЬтЕФЮФЕЕЛсгаЯрНќЕФcode,ПЩвдНЋУшЪіЯрЭЌФкШнЕФЮФеТНјааЙщРрЁЃ
- ЭМЯёЫбЫї:ЯШНЋЪфШыЭМЯёзЊГЩcodeдйНјааЯрЫЦЭМЯёВщев,ЕУЕНЕФНсЙћвЊБШЭЈЙ§ЯёЫиЯрЫЦВщевКУКмЖрЁЃ
- дЄбЕСЗЩюЖШЩёОЭјТч:здБрТыЦїПЩгУгкдкбЕСЗНзЖЮПЊЪМЧА,ШЗЖЈШЈжиОиеѓWЕФГѕЪМжЕЁЃ
здБрТыЦї(Auto-encoder)ЪЧвЛжжЬиЖЈЕФЩёОЭјТчНсЙЙ,ЦфФПЕФЪЧЮЊСЫНЋЪфШыаХЯЂгГЩфЕНФГИіИќЕЭЮЌЖШЕФПеМфЁЃСэЭт,ЖдDecoderНтТывВЪЧгаУюгУЕФЁЃЯждквВБЛРЉеЙдкЩњГЩФЃаЭжа,БШШчФГаЉЩњГЩФЃаЭвВПЩвдПДзіЪЧвЛжжЬиЪтЕФздБрТыЦї,Р§ШчБфЗжздБрТыЦї(variational auto-encoder)ЁЃ