���̳���������������µ�ʱ��,���ٽ���ҵ������,����ѧ��ʱ�����һ��������,�ź����dzɼ������Ǻ�����,���ֻ�õ��˹���,���˸��������DZ���solo�ľ��档�����ڼ���ᵽ����ְ��Ա�IJ���,�����ϰ�,���ϰ�ҹ�����,���̫���˩ѩҩn�ѩҡ����,��Ϊѧ��ʱ���ġ��յ㡱,�����ڴ˼�¼�±���������ѧϰ����֪ʶ,��л�����ǵķ����Լ���������˽�Ŀ�Դ,Ŭ����ǰ������ѡ��ѧϰ��
�˴�����:GitHub��ַ
����:Wisley
����:903953316@qq.com
GitHub:������ҳ
😄😘😇
һ����������w
�˴α������������Ͳ������������Ϣ,���ڸ�����һ���������ù�����Ƶ�š������Ƽ������û�, ������Щ�û�����Ƶ���ڵ���ʷn�����Ϊ����,ͨ���㷨�ڲ��Լ���Ԥ�����Щ�û����ڲ�ͬ��Ƶ���ݵĻ�����Ϊ(�������ޡ����ͷ���ղء�ת����)�ķ������ʡ� ���α����Զ����ΪԤ�����ļ�ȨuAUCֵ�������֡�
1������
������Ҫ����������,feed_info����user_action��,��ϸ����˵�������鿴������
- feed_info.csv
Feed��Ϣ����������Ƶ(���feed)�Ļ�����Ϣ,��authorid(��Ƶ������ID)��bgm_song_id(��������ID),�Լ�manual_keyword_list(�˹���ע�ؼ���)�Ȼ���ID��Ϣ,ͬʱ���������������ı���Ϣ(������Ƶ����),�Լ���Ƶ��Ϣasr��ͼ��ʶ����Ϣocr�Ⱦ����������ַ���������ʾ��ͬʱ���������ṩ���ں���ocr��asr��ͼ�����ֵĶ�ģ̬������������������,����ά��Ϊ512ά�� - user_action.csv
�û���Ϊ���������û�����Ƶ����һ��ʱ���ڵ���ʷ��Ϊ����(����ͣ��ʱ��������ʱ�����������),�ñ����û���Ӧ���ݰ���ʱ���˳����С�������С��������ṩ���û������Ϊ�ı�ǩ��
user action������Ҫ�����ֵ����Ϊ,���г��������շ���Ϊ4����Ϊ(�鿴���ۡ����ޡ����ͷ��ת��)��uAUCֵ�ļ�Ȩƽ�������������շ���Ϊ7����Ϊ(�鿴���ۡ����ޡ����ͷ��ת�����ղء����ۺ�ע)��uAUCֵ�ļ�Ȩƽ����
2������ָ��
���α�������uAUC��Ϊ������ΪԤ����������ָ��,uAUC����Ϊ��ͬ�û���AUC��ƽ��ֵ,���㹫ʽ����:
u
A
U
C
=
1
n
��
i
=
1
n
A
U
C
i
u A U C=\frac{1}{n} \sum_{i=1}^{n} A U C_{i}
uAUC=n1?i=1��n?AUCi?
����,nΪ���Լ��е���Ч�û���,��Ч�û�ָ���Ƕ���ij����Ԥ�����Ϊ,���˵����Լ���ȫ����������ȫ�Ǹ��������û���ʣ�µ��û���AUCiΪ��i����Ч�û���Ԥ������AUC(Area Under Curve)��
�Ӽ��㹫ʽ���Կ���,����ֻ���ÿ���û���AUC���㲢ȡƽ��,��ô����������,��ͬ�û�����Ϊ��Dz���Ӱ���,ͬʱ������AUC�ļ���,���Խ����Ԥ����ʴ�СҲ��,ֻ�����û���ΪԤ��������йء�
3������˵��
- ����ȫ�̲�����ʹ���ⲿ���ݼ���
- ����ʹ�ÿ�Դ�Ĵʵ䡢embedding��Ԥѵ��ģ��,�������ݺ�ģ������2021/07/12����ǰ��Դ,����ͨ���ʼ�����ʽ����ί�ᱨ����Դ���ӵ�ַ��md5��
- ����������ʹ�ó����ε����ݼ���
������������
������Ҫ����deep_ctr[1]�Ŀ�ܽ��е�,����,���ѽ���ʹ��lightgbm����ѧϰ����,��feed����action�����������̺�,����������lgbѵ��Ԥ�⡣����kitty�ǽ��baseline�����ѧϰ����,����deepfmģ�ͽ�������������ɢ�������Լ��ɱ䳤����(�����ı�����)����ģ��Ԥ�⡣�������ѵķ������ǵ�����Ԥ��,�����ܳɶ������,�ⲿ�ֶ��ѵĹ������������,��Ҫ�����±��߳����ķ�����˼·��
1��ѵ�����
���������Ǹ����ǩԤ������,���ǵ��������ڸ����ģ�������Ͻ���,����һ��ʼ��û�в��õ�����Ԥ��ķ�ʽ,���Dz����˶��ǩԤ��ķ�����ģ�������������ʹ��MMOE���ж����������
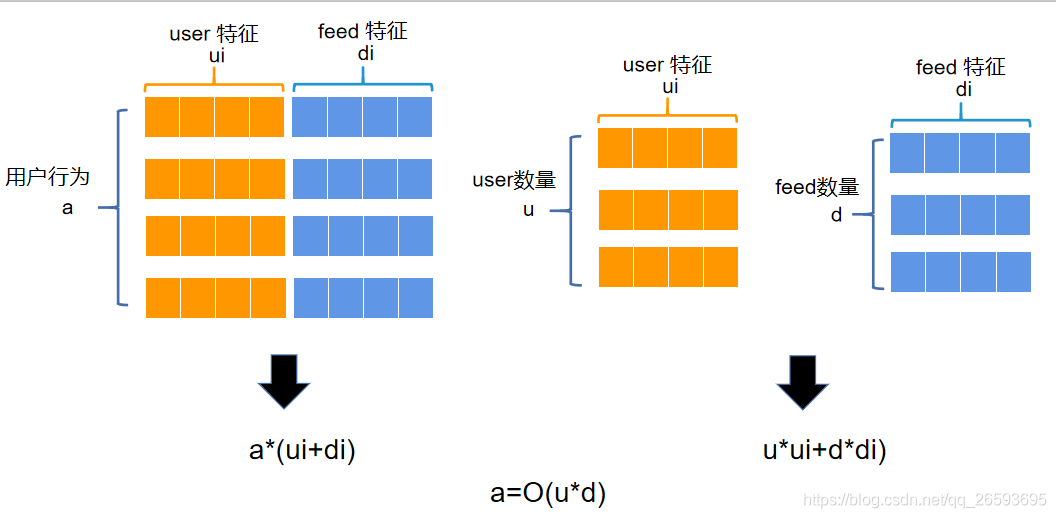
��ѵ����ܵ������,��GNN�칹ͼ�Ĺ�������,���ߵ���������user����feed��,����user�����ڴ���û�����������,feed�����ڴ����Ƶ����������,���������ֵ�ķ�ʽ���д洢,��������Ϊkey�������������Ƕ�feedid����˳���0��ʼ���±���Ϊfeedid_node,ÿ�����������������±�����˳������,���ֻҪ֪��feedid_node�ı���Լ�����key,����ȡ����feed��Ӧ��������ͬ��useridҲ���±���Ϊ��userid_node�������ڹ�����������������,��buildģ��ʱ,����ŵ�GPU�ϡ�����ģ��ǰ��ʱ,ֻ�轫feedid_node��userid_node�ͽ�ȥ,����id��������Ӧ������,����ƴ�Ӽ��ɡ������ʹ�����ڴ濪������ͨ��ѵ����ʽ�ǽ�������user action��Ϊ������ƴ��,��Sequence batch�ķ�ʽ����ģ��ѵ��,�����ڴ�ռ�õĴ�С��action�Ĵ�С�Լ�user��feed����ά�����йء������Dz�ȡ�ķ�ʽ,ֻ��user��������feed������ά���й�,��action�Ĵ�С�ء����ڱ������userid��feedid�ǹ̶�������(���Լ���useridһ��������ѵ������,���ܳ��ֵ�feed������ȫ������),���������ķ�ʽ��ԭ����Ҫ�� a*(di+ui) ���ڴ�ռ�,������ֻ��Ҫ u*ui+d*di ��С���ڴ�ռ䡣����a��ʾ�û���Ϊ��,d��ʾfeed����,u��ʾuser����,di��ʾfeed����ά��,ui��ʾuser����ά�ȡ�����֮��,����Ƕ������,����ֻ�����Ӧ����id,��ģ��ͨ��ģ���ڲ���embedding�������õ���������,���Դ�������ڴ���Դ��ռ��,�ڳ�����,����4096��batcsize �Դ�ռ��Ҳֻ��5g,���Դ�ռ�ô�С��batchsize��С�ء�
������������ѵ������ʾ����������:
#����feed����user��
feed_data={}
user_data={}
#feed
feed_data['dense']=torch.from_numpy(feeds[dense_features].values.astype('float32'))
feed_data['hash_dense']=torch.from_numpy(np.hstack([dense_arry1,dense_arry2,dense_arry4,dense_arry3]).astype('float32'))
# user
user_feats=['userid','device']
for f in user_feats:
user_info[f]=user_info[f].fillna(0)
for f in ['device']:
gens=LabelEncoder()
user_info[f]=gens.fit_transform(user_info[f])
user_data[f]=torch.from_numpy(user_info[f].values)
# �ŵ�GPU��
for f,d in user_data.items():
user_data[f]=d.to(torch.device('cuda'))
for f,d in feed_data.items():
feed_data[f]=d.to(torch.device('cuda'))
#ѵ��
batch_size=4096
src=train_ratings['userid'].apply(lambda x: userid2nid[x]).values
dst=train_ratings['feedid'].apply(lambda x: feedid2nid[x]).values
for ind in tqdm(range(0,n_pos//batch_size+1)):
batch=batch_index[ind*batch_size:(ind+1)*batch_size]
batch_src=src[batch] # user node
batch_dst=dst[batch] # feed node
logits = model(batch_src,batch_dst)
2��ģ�ͽṹ
���ڱ�����У�ڼ�,���й�һЩGNN���֪ʶ,�����GNN���Ƽ�����Ҳ�dz����Ȼ���,�����ڱ�������һֱ�볢��ʹ��GNN ��һЩģ��,�ⲿ��ģ���ǻ���DGLʵ�ֵġ�
(1) PinSage
PinSage��˹̹����Pinterest��˾��������Ĺ�ҵ��GCN�Ƽ�ϵͳ,������Ӧ������Pinterest��,PinSageģ��ʹ�����������ͼ����������ͼ�ṹ�������Լ��ڵ������,�����ɽڵ��Ƕ���ʾ�����㷨���ص�����ͨ�������ڵ���ھӲ���̬�شӲ����ھӹ�������ͼ,ʵ������Ч���ֲ��ľ���,�Ӷ���ѵ��ʱ����Ҫ������ͼ�Ͻ��в������������ǿ��Զ�user�ڵ��feed�ھӽ��в���,������feed�ڵ����ͼ��������ʽͬ����ѡ��������ߵķ�ʽ��
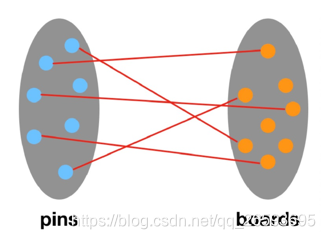
����GCN���� ���߳�����GAT��GraphSAGE�� Ч����������,���Խ�ѧ����node embedding��ԭʼ������embedding���кϲ�,ͨ��DNN���,�бȽϴ������,�������Ϸ���ֻ��0.63���ҡ��������ֲ�ʹ��GNN�е�embedding������������,����������������pinsage����ο�
(2)RGCN
��PinSage��,���ö���ͼ���й�ͼ,�Ȿ�����Ե���һ�����ʵ�ͼ������,����ͬ�����ϵ�������ʵı߹�ϵ����˱����ֳ��Թ�������ͼ������,������RGCN��Ϊͼ����������Ϣ�ۺϡ����ڲ�ͬ�ı߹�ϵ(�����������ò�ͬ�ĵ��������),����һ���ѧϰ�IJ��������Ӧ(ͼ����)���칹ͼRGCN�Ĵ�����Բο�DGL�ٷ��ֲ�ʾ������,����:
import dgl.nn as dglnn
class RGCN(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats, rel_names):
super().__init__()
self.conv1 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(in_feats, hid_feats)
for rel in rel_names}, aggregate='sum')
self.conv2 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(hid_feats, out_feats)
for rel in rel_names}, aggregate='sum')
def forward(self, graph, inputs):
# inputs are features of nodes
h = self.conv1(graph, inputs)
h = {k: F.relu(v) for k, v in h.items()}
h = self.conv2(graph, h)
return h
����ʵ�鷢��,���ڱ�������,�����û���������Ʒ��Ϊ��,���Ե��������Ϊ�߹�ϵЧ��Ҫ��,������ھ�������,��ͨ��ͼ����ҲҪ����������������,���Pinsage,����RGCN�ı���Ҫ����,���������ܴﵽ0.65����,������һ���ĵ��κ������Ż�,���Դﵽ0.66���ҵķ���,���Ǻ�����һ��ʱ�������ȴʼ��û�м����Ϸ���,���Բ�����,���ǰ�ע���������˴�ͳNN�����ϡ�
(3)Cross Net mix
�ڲ�ͬ��ҵ����,CTR�������������ϸ�µ��������̡�һ����˵,�������ģ�;��ǽ�ԭʼ����������ϱ任,���dz��������Ⲣ��������չ,���DZ����������ޡ�����Ч���������ͨ����Ҫ�˹����ϵ�̽���볢�ԡ�NN����,����Ϊ�˴����ʱ�������ֹ�����,��ģ���Զ�̽������ϸ߽����������еĺܶ��������Ч��NNģ��,��Deepfm��DIN��AutoInt,���dz��ԴӲ�ͬ�ķ�������������ı�������,ʹģ���ܸ���Ч���ھ���ɢ���������ı����е���������ϡ�������,DNN�ܹ����ض�ƽ��������������ľ��ȱƽ����⺯��,����ʵ���д�������������������,����DNN�ܹ����ÿ��еIJ������ﵽ�ܺõ�Ч����ͨ��DNN�ܹ�����ɢ�����е�������Embedding�����Լ������Լ����ѧϰ���߽��������,���Ҳв�����ʹ�������ܹ�ѵ����������硣Ȼ����ʽ��ѧϰ�����е��������,����ģ��Ч����ѧϰЧ�ʿ��ܲ�������������,����ȱ��һ���Ŀɽ����ԡ�����FM��FFM �������ʽȥ���������Ķ����߸��߽����,����dz��Ľṹ���������������ı�������,���߽���չ������˴�������ļ��㿪���������ڱ�����,�ܶ���Ч����������������ǵͽġ����,���������һ�ָ�Ч�ķ�ʽ�������Ե��������,Cross Network
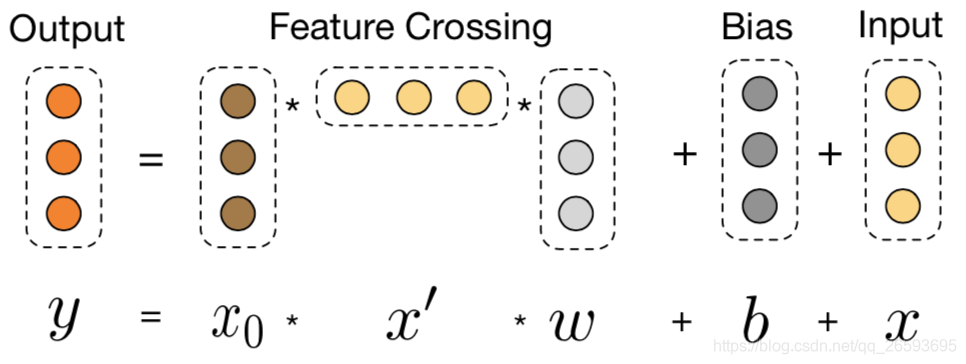
ÿһ�����Ԫ��������ͬ���ҵ�����������
X
0
X_0
X0?��ά��,ÿһ�㶼�����¹�ʽ��ʾ(����������),���к���
f
f
f��ϵ���
X
l
+
1
X_{l+1}
Xl+1??
X
l
X_l
Xl?�IJв��һ��
X
l
+
1
=
X
0
X
l
T
W
l
+
B
l
+
X
l
=
f
(
X
l
,
W
l
,
B
l
)
+
X
l
X_{l+1}=X_{0} X_{l}^{T} W_{l}+B_{l}+X_{l}=f\left(X_{l}, W_{l}, B_{l}\right)+X_{l}
Xl+1?=X0?XlT?Wl?+Bl?+Xl?=f(Xl?,Wl?,Bl?)+Xl?
���DNN,����������ʾ�ع����˽�����,�Ҳ�����ҪС�ܶ�,ͬʱÿһ�����������һ�ν������,ģ�����пɽ����ԡ���һ��,��MOE�ṹ����DCN-Mģ�Ͷ�DCN�����˸Ľ�,��W��ɲ�������,������ֽ�������ӿռ�,���ͨ���ſػ���������Щ�ӿռ�����ں�,����Ч��ѧϰ��ʽ����ʽ��������,ʹģ��Ч����ͬʱ,��ǿ�˱�������,����ͼ��ʾ��
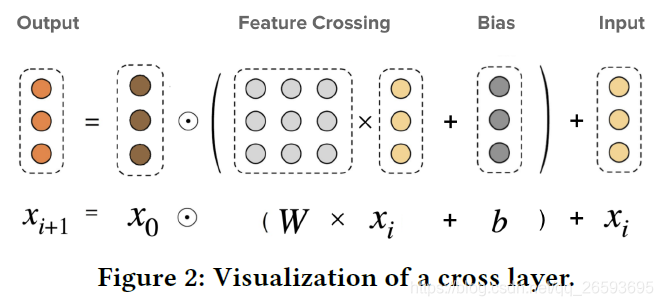
�ڱ�����,���ǽ�ϡ�����������������Լ�embedding����ƴ�Ӻ�,����cross net,ר����Ĭ��4,�����������4,�����DNN�����ƴ��,����һ�����Բ����,�����ܴﵽ0.669���ҵijɼ�,�����֮ǰGNN�ı��ֶ�Ҫ�úܶࡣ��deep_ctr�п���ֱ�ӵ���:
CrossNetMix(128*3+64,layer_num=4)
����ͨ������ʵ��,�Ա�deepfm,����ͬ�����������,cross network���deepfm�н���һ���ٵ�������
3����������
������о��±Ƚ����õ�����,һЩԭʼ�������벻������͡�
1. Target Encode
��feedid��authorid��userid�Ȼ�������,ͨ������(ǰN��)����label�ľ�ֵ��Ϊ������������(��ϸ���ڴ����в鿴)
2. ϡ������
maunual_keyword_list����������ȡ���е�id��Ϊϡ������,����ʹ��tfidf+svd�õ�embdding��
3��embding��
��������������������е�ǿ����,����ǰ�źܶ���鶼�ǿ�����Ϸֵ�,����GNN��˼��,ͨ��groupby userid�õ�feedid����,����������ѵ��w2v,�õ�feedid��embedding�����ﳢ���˷�����embedding,Ч��Զû��ֱ�Ӱ����н�����embedding�á�������Ϊ,�������ṩ�����ݿ������Ѿ����ź�Ľ��,���û��ع��feed��ʵ��һ���̶��ϱ������û�һ����ϲ������,ͬʱ�����������embҲ�������Ϣй¶�����⡣�����embedding���Գ��Զ��ֵ����,��feedid��userid��������,����Դ治���Ļ�������svd�ֽ�����ά��ͨ��һЩʵ�����Ƿ��������õĻ���ͨ��userid��feedid��emb,ͬʱ���ǻ�������deepwalk��node2vec�ķ�ʽ,��groupby�ķ�ʽ���
������������
���������������dz�����10��,���Դ����ѡ�ֵ���Ҫ����������������ڴ��������ֳ����ķ��������߳���ʱ�����˸��������,���Բ�����Ҫ��ԭ���ķ���������ĸĶ�����ͳ����������,���ڲ��Լ����ɼ�,��������������ʱ��,������ѵ������ͳ�������ֲ�,�����ƶ�ʱ�ṩ�����Լ����ڲ����κ��Ż��Ľ�ʱ,������һ���ύ����0.695�ķ�����
1��������
1��feedid emb �ĸĽ�,����sg ��hs ģʽ�ֱ�ѵ��emb������ƴ�ӡ�
2��ͨ���������ϵ��,������Щ����Ƚ����,���Բ����������Բ��ķ�ʽ��
3��DNN��ʹ��BN��dropout ����ģ�͵ķ�������
4��ѵ���ϲ��� lookahead+admw ,����epoch���ɡ�
5�� ���DIN�Ľṹ,����user����Ϊ��������,ͨ��attention pool�õ���Ȥfeed��emb��(�ⲿ�ֿ��Թ���һ���µ�ģ��,������������cross network�Dz���,������Ϊ���Ķ�ģ�ں�,��ϸ���Բο�deep_ctr�еĴ����Լ�����git�ϵĴ���)��Ҳ��ǰ��ѡ���ǽ��transform�Ľṹ����,��ȡ���˲�����Ч��,���DZ���ʹ��tansformer��Ч���dz���,�Ⱥ��濪Դ�˿���ѧϰ�´�������ô���ġ�
2��������
1����action������������(�������Ķ����ж���,���Ƕ���̫����),�������������Ƿdz������,��Ȼ���������Ŀ���,��������û��һ����Ч���ж������ķ���,�������ޱ�Ҫ,������ȫ������ѵ������õġ�
2��userid ��embedding,�ⲿ�ֵ�������feedid��emb��һ����,����Ч����������,�ڳ������н��ֵļ���
3������ple��,PLE�ų��DZ�MMOE�ڶ��������и��õı���,������torchʵ����ple��,����ȷʵ��һ�������,�������Ͻ����mmoe�Dz���,������ȴ����,���������������������
4�� ���Ӹ�������embedding��ά��,����dnn������expert����,��������,�������й���ϵķ��ա�
�ġ�����˼��
(1)�ڳ���ʱ,ͳ��������Ŀ�����ȷ�ʽ,�Է����н�Ϊ���Ե�����,�����ڸ�����,�ⲿ��ȴû��ô��Ҫ,�����ڸ���ʱ,���ⷢ��,��ʹȥ�����н�����ͳ������,ֻ����embedding����,ģ����Ȼ�ܴﵽ�൱�������õķ�����
(2)���������ѿ�Դ��ǰ�ŷ���,���߷�����Ҫ�����û�ж�emb����һ�����볢��,������id��emb+svd�Լ����ı�������tfidf+svd �������Ч��,������һЩ���ı������ϲ��ýضϵķ�ʽҲ���Ǻܺ���,��ͬ�������Ҳ���Ӱ�졣ͬʱ�����ڸ�����,ͳ���������ܶ�ģ��Ԥ�����һ���ĸ�����,����û�н�һ��ȥ�о���ʵ�顣
(3)����˼������,Ϊʲô����GNN�Ľ�ģ��������,����ʹ�õĶ�����Ϣ���ݵĿ��,����������Ҫ��feed�������,��ô������user node����feed node ����������feed emb����Ϣ���ݲ�����,���е�user�����dz���,�е�user����feed�ر��,���ֲ�ƽ���Ƿ��Ӱ��ڵ�ı���? ����GNN�����ʹ�����ƽ��������,������о�����,GCN�е����Ա任������ģ�͵��˻�,�Ƿ����ǿ��Լ�ֻ����һ��GCN ������Ϣ�ۺ�? ������Ȼ���������в�û��ʹ��GNNģ��,����ͨ��groupby userid ��feedidԤѵ����GNN������ͬ��������,���ⲿ�ֵ������Ƿdz����,��˵��GNN �Ľṹ�Ƿdz�ֵ�ý����,��ôʵ��һ���˵��˵�GNN+DNN��ģ��,�Ƿ���Ԥѵ��+dnn����ʽҪ���ø����š�
(4) �����û�����Ϊ������δ���ֳ���ǿ��ʱ����,��Ȼ���ݰ����û��ĵ��ʱ�����������,���ǵ�ʹ��ʱ��ģ����LSTMȥ��ȡ�������ʱ,���ֲ����á�������Ϊ,������Ƶ�Ƽ����û�����,����¼���̫����Ƶ���ع�����Ӱ��,�����Ƽ���ͬ,��û�б��ֳ���ǿ��ʱ����,����:�ϸ�������ϲ����������Ƶ,����������ڻ���ϲ��(���Ƽ��ع����Ƶ����ݶ��ڵ��û���Ȥ�����Ƽ�)��
�����DZ����Լ���һЩ˼���Ͳ���,��ӭ�������۷�����Ȥ�Ĺ۵�һ�����ۡ�
�ڴ��ٴθ�лǰ����˽�Ŀ�Դ�����,������վ�ھ��˵ļ��ſ��ĸ��߸�Զ!
�����
��1��DeepCTR: Easy-to-use,Modular and Extendible package of deep-learning based CTR models ,Weichen Shen
��2�� ����Paper��Deep & Cross Network for Ad Click Predictions - һֻ��Ӱ - ������- https://www.cnblogs.com/cling-cling/p/9922766.html
��3�� �������������:[google]DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning_knight�IJ���-CSDN���͡�- https://blog.csdn.net/u012852385/article/details/109197384
��4�� ��Deep and Cross Networkԭ����ʵ�� Andante��- https://nirvanada.github.io/2017/12/14/DCN/
��5�� ��deepctr.models.dcnmix module �� DeepCTR 0.8.7 documentation��- https://deepctr-doc.readthedocs.io/en/latest/deepctr.models.dcnmix.html