机器学习介绍
机器学习区别于人工设置好的规则类的程序,其程序具备自主学习以及自主优化的能力,鲁棒性相较于人为指定规则的程序更好。
而机器学习的本质就是去拟合一个函数,这个函数的输入值可以是图片,语音,文字等各种人类可能会接触到的信息,甚至可以是人类无法接收到的信息,如红外线等等,输出值则会根据学习目的的不同有所不同,例如图片识别的函数则会输出对应的物体名称,语音识别的函数则可以输出对应的文字,语言翻译的函数则可以输出另一种语言对应的文字等等。
机器学习的步骤总的来说可以被归纳为三部分:
- 构建函数
- 通过训练集计算损失函数通过梯度来更新函数
- 根据测试集来检测得到的函数是否足够优秀
机器学习相关技术
本期Learning map:
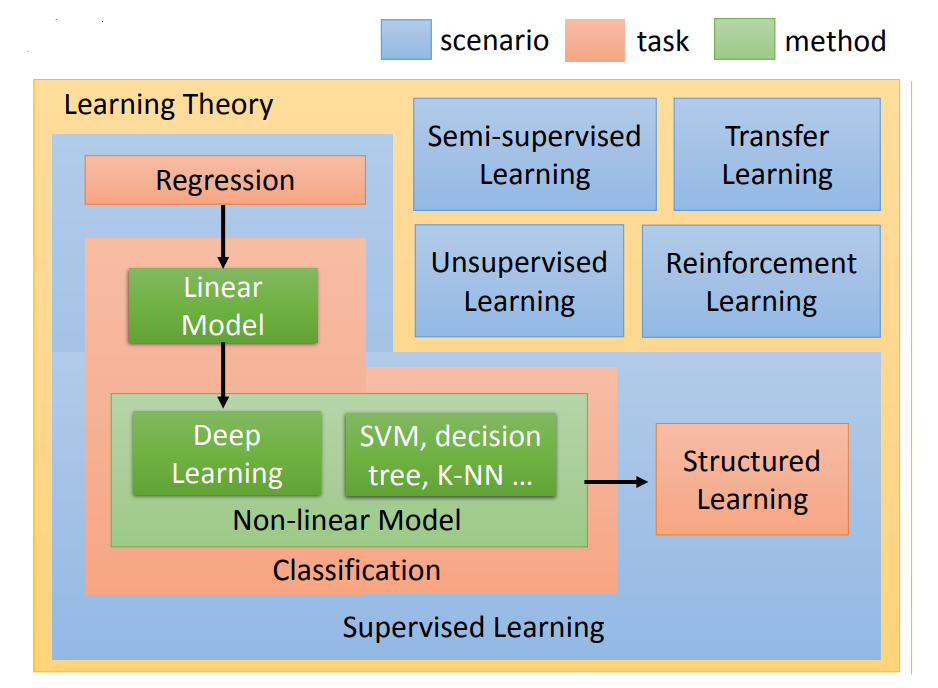
我们将从左上角开始分块介绍每一部分的细节
监督学习
监督学习中一般有两类问题:
-
回归(Regression)
顾名思义,就是求出某个模型的回归函数,以最简单的数学例子为例:当我们已知当 ? x = 1 \ x =1 ?x=1时, ? f ( x ) = 2 \ f(x) = 2 ?f(x)=2,当 ? x = 2 \ x = 2 ?x=2时, ? f ( x ) = 4 \ f(x) = 4 ?f(x)=4,求 ? f ( x ) \ f(x) ?f(x)的解析式。
这里的 ? f ( x ) \ f(x) ?f(x)的形式可能有很多种,但是我们只需要求出满足上述条件的某个解析式即可。类似的例子还有很多,例如我们已知一些时间与PM2.5的对应数值,我们就可以尝试求得时间点与PM2.5的对应函数关系,继而就可以预测在某一时间点的PM2.5数值。
这样类型的任务我们称为是回归类型的任务。 -
分类 (Classification)
分类问题与回归问题相对应,与回归问题最大的不同在于其输出空间为离散的,即输出始终只有有限个,例如给出一封邮件,判断它是否为垃圾邮件,或者给出一张图片,判断上面的动物是什么动物等等,这些问题的答案都是有限个的,而不像回归,其输出答案可以是无限多的。
之所以称回归与分类被归类为监督学习中,是因为它们都非常依赖于被标注(labled)了的数据集,例如我们如果需要训练一个能够进行图像识别的人工智能,我们最需要的往往是一个已经被标注出各类物体类别的图像集合。
而监督学习中有一类很特别的,被广泛应用于强化学习的类型,叫做模仿学习。其本质也是监督学习,只是它的标注(label)不再是某一客观物体,而可能是某一种行为。例如AlphaGo的早期训练中,使用了大量的人类围棋棋谱以及人类高手的对局作为训练集,让机器学习到在某一对应情形下,在某个固定点下棋是“最优”的,进而训练出一个与人类高手水平相近的智能体。(当然这一手段后续在AlphaZero的训练中被剔除了,因为研究人员发现人类的固有思维反而限制了智能体的学习)
半监督学习
从前面的监督学习的概念中我们发现,人工智能的背后可能是“人工”,即我们需要人为去对数据集进行很多标注,这样无疑是非常低效的,半监督学习因此应运而生。
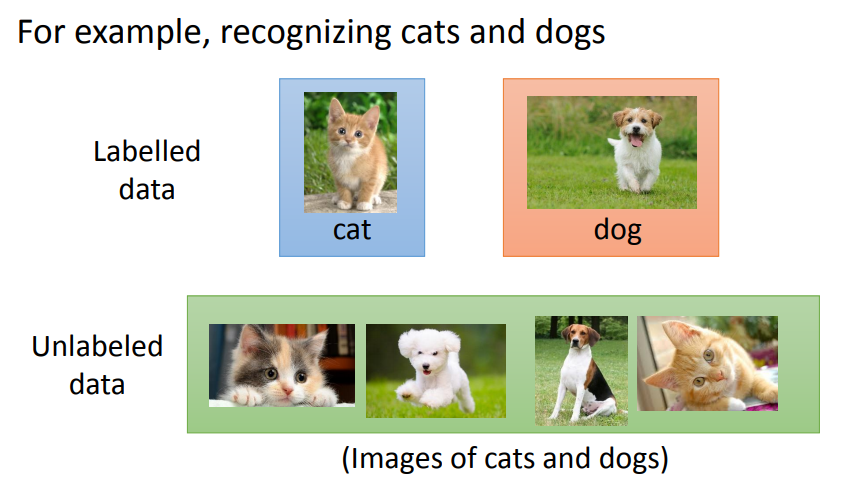
顾名思义,半监督学习就是我们不需要给所有数据集都给出标注,只需给一部分数据集标注好之后,让机器去自己学习标注剩余的数据集。
例如我们需要训练一个能够分辨猫狗的智能体,我们的数据集中只有一部分标注了猫狗,但是剩下的数据集都是没有标注出猫狗的图片。
迁移学习
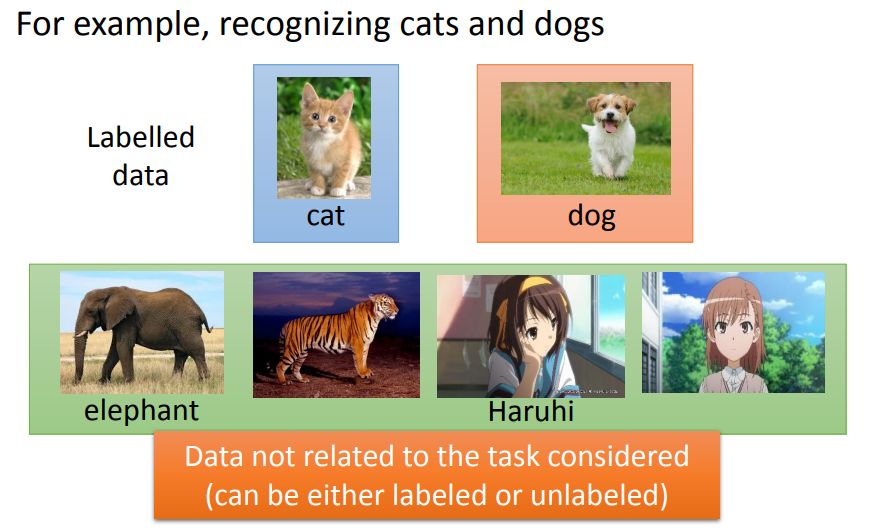
迁移学习是另一种可以有效降低数据标注量的学习方式。
还是以猫狗分类器举例,现在我们的训练集中不止有猫狗,甚至有其他的动物,甚至是动漫人物,现在我们依旧需要让这个分类器能够从中挑出猫狗,并且能够有效识别出来。
无监督学习
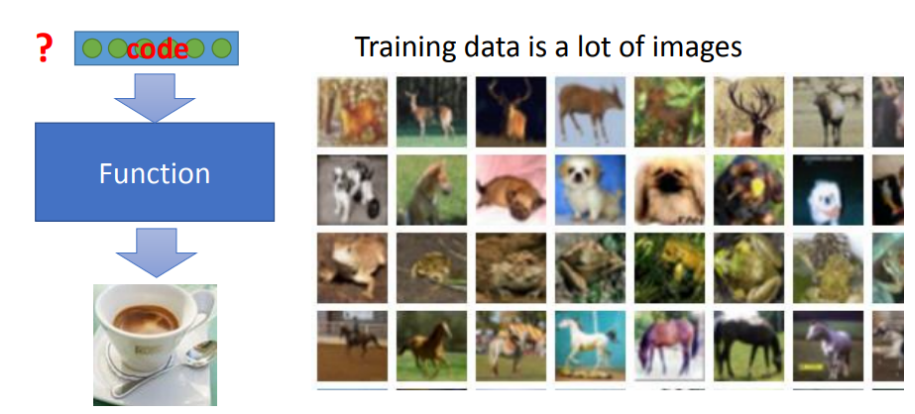
无监督学习顾名思义,就是此时的数据集已经完全没有任何标注了,我们希望智能体能够从中自己提取出有用的信息。
无监督学习中非常典型的一类就是我们现在给出很多很多的图片,我们希望机器能够自行将图片给分类,例如将猫的分为一类,狗的分为一类,风景分为一类,人像分为一类等。
强化学习
强化学习有一些类似于无监督学习,但是又有些许不同,我们往往不会直接给智能体一个训练集,而是让它在某个空间内自由探索,并且在每当它做出一定行动之后,我们会给予它一个“奖励”,最终我们需要得到一个能够将奖励最大化的智能体。
就像是将小白鼠放进了迷宫中一样,同时我们在迷宫的出口处放置了一块很大的蛋糕,而最终我们希望小白鼠自己能够学会走通整个迷宫,并且成功吃到美味的大蛋糕。