文章目录
前言
根据李宏毅教授的视频重新学习机器学习,大概记录一下学习过程
一、机器学习的目的
机器学习就是由机器自动找出一个函数
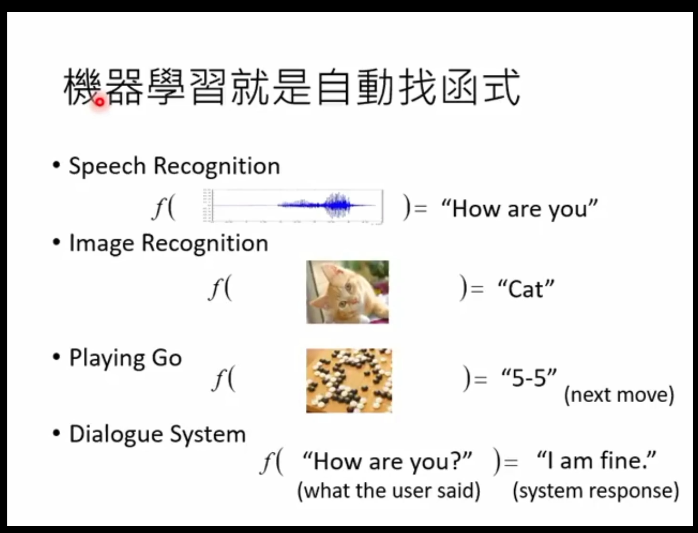
函数分为两大类“Regression”和“Classification”
Regression
输出的是数值的函数就是回归函数(Regression)
Classification
输出的结果是Yes or No(种类) 就是分类函数(Classification)
二、损失函数
损失函数是由自己定义的,用来衡量目前机器学习所寻找到的“函数”效果好坏
例如:
机器学习所寻找到的函数是:y=b+w*xncp(xncp为第n个数据的特征)
我们定义损失函数为:
? ? ? ? ? ? ? ? 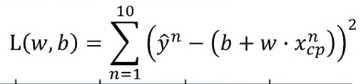
通过计算了L(w,b)的值来衡量机器所寻找的函数的好坏,损失函数越小函数效果越好,反之越不好
三、梯度下降(Gradient Descent)
1.使用梯度下降的目的
??机器学习的目的是为了寻找y=b+w*xncp中适合的b和w使得损失函数的值最小,实际上机器是通过梯度下降方法寻找最佳的b和w,暂时忽略b,假设损失函数为L(w),L(w)随着w的变化如下图所示:
 机器通过梯度下降的方法寻找图像的最低点
机器通过梯度下降的方法寻找图像的最低点
2.梯度下降方法
 ??假设目前在w
0点,计算w
0点的微分,如果为正则减小w,反之增大w,即沿着梯度相反的方向可以走到曲线的最低点。 根据梯度的变化来更新w:
??假设目前在w
0点,计算w
0点的微分,如果为正则减小w,反之增大w,即沿着梯度相反的方向可以走到曲线的最低点。 根据梯度的变化来更新w:

η
\eta
η为学习率
如果是两个参数同样的做法,根据最初的w0和b0计算偏微分,更新w和b

注:如下图所示不同的颜色代表不同种类的input,linger实际上是可以模拟出这样的图像的,采用one-hot 编码将种类和特征进行编码

3.正则化
在原有的损失函数后边加上一个
λ
Σ
\lambda\Sigma
λΣ(wi)2,加入正则化系数的原因是想要尽量减小w,使得input的变化对output的影响不要太大,使得函数曲线尽量平滑
平滑曲线的优势:受杂讯影响较小,如果有杂讯输入,能在一定程度上减小杂讯对结果的影响
4.损失函数损失的来源
损失的来源主要有两种,一种是“bias”一种是“variance”

1.variance
一般来说较为简单的模型variance会比较小,例如左下角和左上角的图,越复杂的模型越容易学习到训练集的局部特征,造成过拟合
2.bias
和variance相反,一般来说较简单的模型bias会更大而较复杂的模型bias会更小,越简单的模型对于训练集的拟合越差,造成欠拟合
5.过拟合和欠拟合
- 过拟合:函数和训练集拟合过好,而在测试集上表现不佳,这时我们可以通过增大训练集或者增大正则化系数的方式来缓解过拟合(在实际操作中还可以直接减少参数数量,减少高次项或者dropout)
- 欠拟合:增加参数数量、增加高次项,减小dropout和正则化系数
6.K-折交叉验证
 如果数据量不足,可以采用交叉验证的方法避免过拟合问题
如果数据量不足,可以采用交叉验证的方法避免过拟合问题
总结
对于机器学习的总体部分进行初步的学习,接下来会具体学习梯度下降等等的机器学习方法