监督学习(supervised learning)
分类classification
- 二分类
- 多分类
(预测离散值)
回归regression
(预测连续值)
无监督学习(unsupervised learning)
聚类(clustering)
将数据集中的样本划分成若干组(cluster),对特征空间的一种划分
学习过程中使用的训练样本通常不具有标记信息
常用算法:KNN、Kmeans、密度聚类、层次聚类
模型的评估与选择
1.基础概念
错误率(error rate): m个样本中有a个样本分类错误 E=a/m
精度(accuracy):精度=1-error rate 即 arruracy=(1-a/m)*100%
误差(error):模型的实际预测值和样本真实输出之间的差异
训练误差:model 在训练集上的误差
泛化误差:model 在新样本上的误差
欠拟合(underfitting):model对训练样本的一般性质还未学好
过拟合(overfitting):model的学习能力过于强大,甚至把训练样本不太一般的性质都学到了
2.评估方法
通常使用测试集(testing set)来检测model 的泛化能力
学习模型应采用泛化(generalization)能力强的模型
- 留出法(分层采样):把数据集7:3分为训练集和测试集(二者互斥)
- 交叉验证法(k折交叉验证):将数据集划分为k个大小相似的互斥子集用k-1个子集作为训练集,余下的那个作测试集,进行k次训练,取k个测试结果的均值
- 自助法(bootstrapping):自助采样法
3,性能度量
(1)查准率precision,查全率recall
TP:正确地标记为正,即算法预测它为好西瓜,这个西瓜真实情况也是好西瓜(双重肯定是肯定);
FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。

(2)二者的关系(矛盾)
P-R曲线

性能:A>B>C
(3)F1度量:查准率和查全率的平均调和(harmonic mean)
1/F1=1/2(1/P +1/R)*
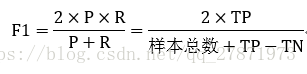
加权平均调和
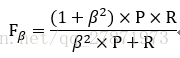
(4)ROC AUC
详细解析见此文章
(5)方差和误差
见我的上一篇文章